 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePositional Biases Shift as Inputs Approach Context Window Limits
Aug 10, 2025



Large Language Models (LLMs) often struggle to use information across long inputs effectively. Prior work has identified positional biases, such as the Lost in the Middle (LiM) effect, where models perform better when information appears at the beginning (primacy bias) or end (recency bias) of the input, rather than in the middle. However, long-context studies have not consistently replicated these effects, raising questions about their intensity and the conditions under which they manifest. To address this, we conducted a comprehensive analysis using relative rather than absolute input lengths, defined with respect to each model's context window. Our findings reveal that the LiM effect is strongest when inputs occupy up to 50% of a model's context window. Beyond that, the primacy bias weakens, while recency bias remains relatively stable. This effectively eliminates the LiM effect; instead, we observe a distance-based bias, where model performance is better when relevant information is closer to the end of the input. Furthermore, our results suggest that successful retrieval is a prerequisite for reasoning in LLMs, and that the observed positional biases in reasoning are largely inherited from retrieval. These insights have implications for long-context tasks, the design of future LLM benchmarks, and evaluation methodologies for LLMs handling extended inputs.
Language models can learn implicit multi-hop reasoning, but only if they have lots of training data
May 23, 2025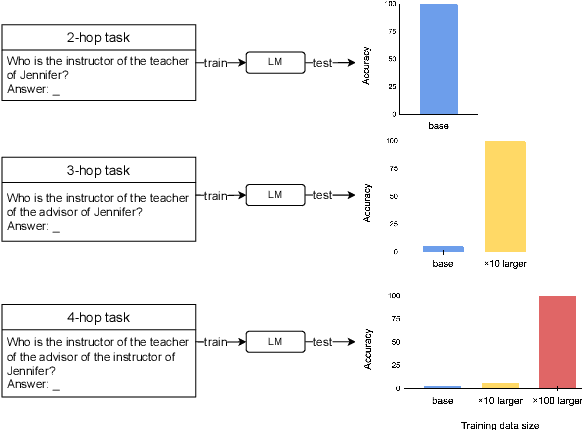
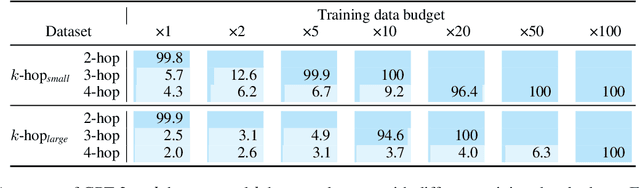
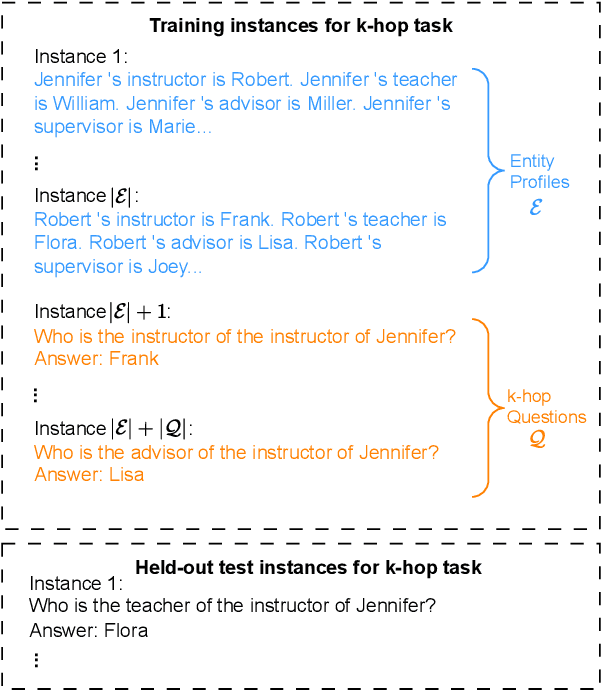
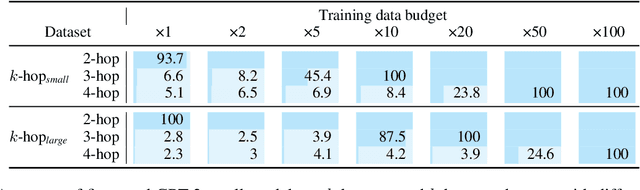
Implicit reasoning is the ability of a language model to solve multi-hop reasoning tasks in a single forward pass, without chain of thought. We investigate this capability using GPT2-style language models trained from scratch on controlled $k$-hop reasoning datasets ($k = 2, 3, 4$). We show that while such models can indeed learn implicit $k$-hop reasoning, the required training data grows exponentially in $k$, and the required number of transformer layers grows linearly in $k$. We offer a theoretical explanation for why this depth growth is necessary. We further find that the data requirement can be mitigated, but not eliminated, through curriculum learning.
Collaborative Problem-Solving in an Optimization Game
May 21, 2025



Dialogue agents that support human users in solving complex tasks have received much attention recently. Many such tasks are NP-hard optimization problems that require careful collaborative exploration of the solution space. We introduce a novel dialogue game in which the agents collaboratively solve a two-player Traveling Salesman problem, along with an agent that combines LLM prompting with symbolic mechanisms for state tracking and grounding. Our best agent solves 45% of games optimally in self-play. It also demonstrates an ability to collaborate successfully with human users and generalize to unfamiliar graphs.
Playpen: An Environment for Exploring Learning Through Conversational Interaction
Apr 11, 2025Are we running out of learning signal? Predicting the next word in an existing text has turned out to be a powerful signal, at least at scale. But there are signs that we are running out of this resource. In recent months, interaction between learner and feedback-giver has come into focus, both for "alignment" (with a reward model judging the quality of instruction following attempts) and for improving "reasoning" (process- and outcome-based verifiers judging reasoning steps). In this paper, we explore to what extent synthetic interaction in what we call Dialogue Games -- goal-directed and rule-governed activities driven predominantly by verbal actions -- can provide a learning signal, and how this signal can be used. We introduce an environment for producing such interaction data (with the help of a Large Language Model as counterpart to the learner model), both offline and online. We investigate the effects of supervised fine-tuning on this data, as well as reinforcement learning setups such as DPO, and GRPO; showing that all of these approaches achieve some improvements in in-domain games, but only GRPO demonstrates the ability to generalise to out-of-domain games as well as retain competitive performance in reference-based tasks. We release the framework and the baseline training setups in the hope that this can foster research in this promising new direction.
LLMs syntactically adapt their language use to their conversational partner
Mar 10, 2025It has been frequently observed that human speakers align their language use with each other during conversations. In this paper, we study empirically whether large language models (LLMs) exhibit the same behavior of conversational adaptation. We construct a corpus of conversations between LLMs and find that two LLM agents end up making more similar syntactic choices as conversations go on, confirming that modern LLMs adapt their language use to their conversational partners in at least a rudimentary way.
Triangulating LLM Progress through Benchmarks, Games, and Cognitive Tests
Feb 20, 2025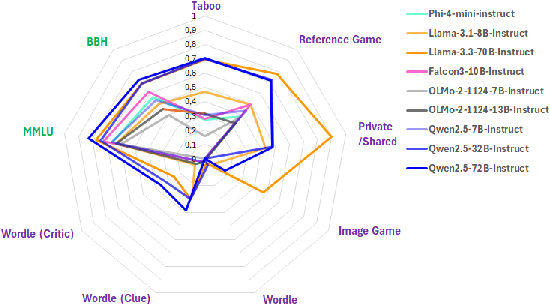
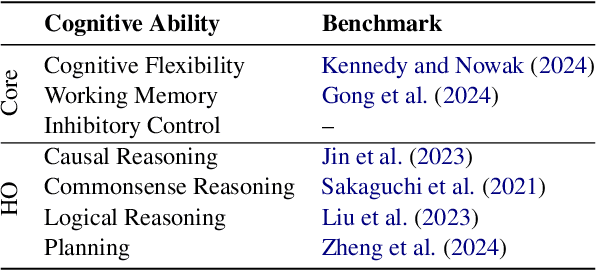
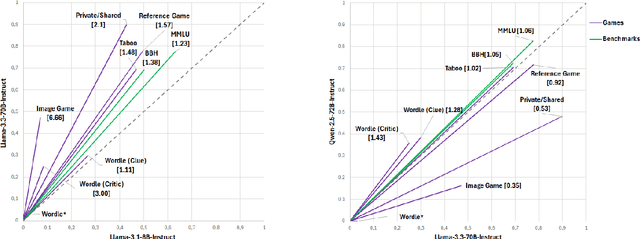
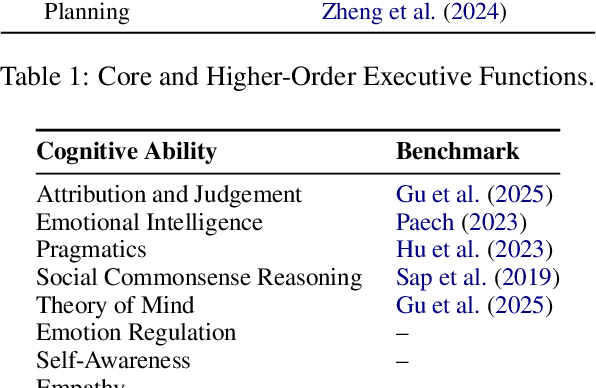
We examine three evaluation paradigms: large question-answering benchmarks (e.g., MMLU and BBH), interactive games (e.g., Signalling Games or Taboo), and cognitive tests (e.g., for working memory or theory of mind). First, we investigate which of the former two-benchmarks or games-is most effective at discriminating LLMs of varying quality. Then, inspired by human cognitive assessments, we compile a suite of targeted tests that measure cognitive abilities deemed essential for effective language use, and we investigate their correlation with model performance in benchmarks and games. Our analyses reveal that interactive games are superior to standard benchmarks in discriminating models. Causal and logical reasoning correlate with both static and interactive tests, while differences emerge regarding core executive functions and social/emotional skills, which correlate more with games. We advocate the development of new interactive benchmarks and targeted cognitive tasks inspired by assessing human abilities but designed specifically for LLMs.
EHOP: A Dataset of Everyday NP-Hard Optimization Problems
Feb 19, 2025We introduce the dataset of Everyday Hard Optimization Problems (EHOP), a collection of NP-hard optimization problems expressed in natural language. EHOP includes problem formulations that could be found in computer science textbooks, versions that are dressed up as problems that could arise in real life, and variants of well-known problems with inverted rules. We find that state-of-the-art LLMs, across multiple prompting strategies, systematically solve textbook problems more accurately than their real-life and inverted counterparts. We argue that this constitutes evidence that LLMs adapt solutions seen during training, rather than leveraging reasoning abilities that would enable them to generalize to novel problems.
A Survey on Complex Tasks for Goal-Directed Interactive Agents
Sep 27, 2024Goal-directed interactive agents, which autonomously complete tasks through interactions with their environment, can assist humans in various domains of their daily lives. Recent advances in large language models (LLMs) led to a surge of new, more and more challenging tasks to evaluate such agents. To properly contextualize performance across these tasks, it is imperative to understand the different challenges they pose to agents. To this end, this survey compiles relevant tasks and environments for evaluating goal-directed interactive agents, structuring them along dimensions relevant for understanding current obstacles. An up-to-date compilation of relevant resources can be found on our project website: https://coli-saar.github.io/interactive-agents.
Learning Program Behavioral Models from Synthesized Input-Output Pairs
Jul 11, 2024



We introduce Modelizer - a novel framework that, given a black-box program, learns a _model from its input/output behavior_ using _neural machine translation_. The resulting model _mocks_ the original program: Given an input, the model predicts the output that would have been produced by the program. However, the model is also _reversible_ - that is, the model can predict the input that would have produced a given output. Finally, the model is _differentiable_ and can be efficiently restricted to predict only a certain aspect of the program behavior. Modelizer uses _grammars_ to synthesize inputs and to parse the resulting outputs, allowing it to learn sequence-to-sequence associations between token streams. Other than input and output grammars, Modelizer only requires the ability to execute the program. The resulting models are _small_, requiring fewer than 6.3 million parameters for languages such as Markdown or HTML; and they are _accurate_, achieving up to 95.4% accuracy and a BLEU score of 0.98 with standard error 0.04 in mocking real-world applications. We foresee several _applications_ of these models, especially as the output of the program can be any aspect of program behavior. Besides mocking and predicting program behavior, the model can also synthesize inputs that are likely to produce a particular behavior, such as failures or coverage.
Strengthening Structural Inductive Biases by Pre-training to Perform Syntactic Transformations
Jul 05, 2024Models need appropriate inductive biases to effectively learn from small amounts of data and generalize systematically outside of the training distribution. While Transformers are highly versatile and powerful, they can still benefit from enhanced structural inductive biases for seq2seq tasks, especially those involving syntactic transformations, such as converting active to passive voice or semantic parsing. In this paper, we propose to strengthen the structural inductive bias of a Transformer by intermediate pre-training to perform synthetically generated syntactic transformations of dependency trees given a description of the transformation. Our experiments confirm that this helps with few-shot learning of syntactic tasks such as chunking, and also improves structural generalization for semantic parsing. Our analysis shows that the intermediate pre-training leads to attention heads that keep track of which syntactic transformation needs to be applied to which token, and that the model can leverage these attention heads on downstream tasks.