 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlaypen: An Environment for Exploring Learning Through Conversational Interaction
Apr 11, 2025
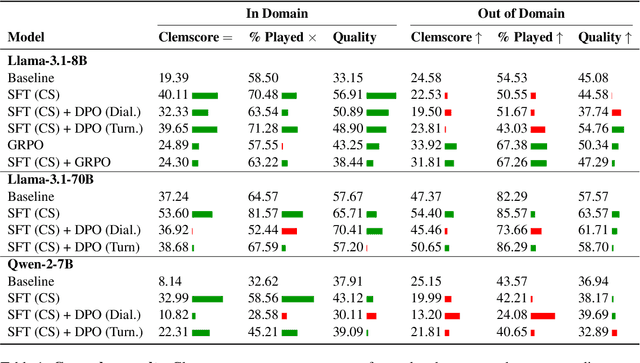


Are we running out of learning signal? Predicting the next word in an existing text has turned out to be a powerful signal, at least at scale. But there are signs that we are running out of this resource. In recent months, interaction between learner and feedback-giver has come into focus, both for "alignment" (with a reward model judging the quality of instruction following attempts) and for improving "reasoning" (process- and outcome-based verifiers judging reasoning steps). In this paper, we explore to what extent synthetic interaction in what we call Dialogue Games -- goal-directed and rule-governed activities driven predominantly by verbal actions -- can provide a learning signal, and how this signal can be used. We introduce an environment for producing such interaction data (with the help of a Large Language Model as counterpart to the learner model), both offline and online. We investigate the effects of supervised fine-tuning on this data, as well as reinforcement learning setups such as DPO, and GRPO; showing that all of these approaches achieve some improvements in in-domain games, but only GRPO demonstrates the ability to generalise to out-of-domain games as well as retain competitive performance in reference-based tasks. We release the framework and the baseline training setups in the hope that this can foster research in this promising new direction.
Triangulating LLM Progress through Benchmarks, Games, and Cognitive Tests
Feb 20, 2025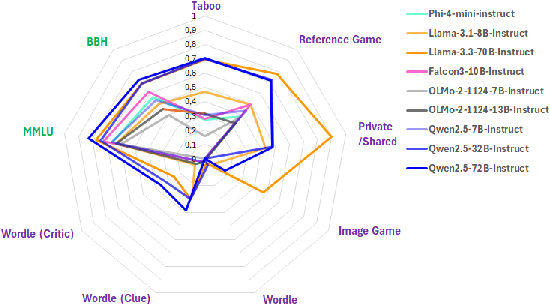
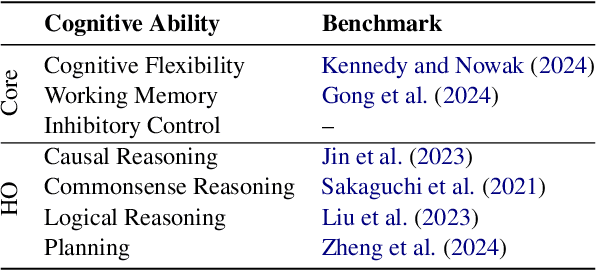
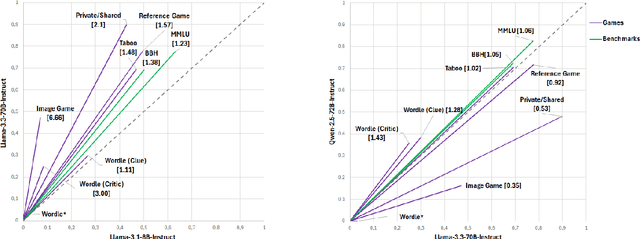
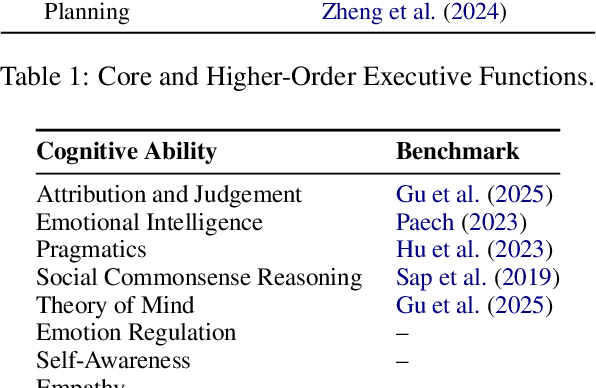
We examine three evaluation paradigms: large question-answering benchmarks (e.g., MMLU and BBH), interactive games (e.g., Signalling Games or Taboo), and cognitive tests (e.g., for working memory or theory of mind). First, we investigate which of the former two-benchmarks or games-is most effective at discriminating LLMs of varying quality. Then, inspired by human cognitive assessments, we compile a suite of targeted tests that measure cognitive abilities deemed essential for effective language use, and we investigate their correlation with model performance in benchmarks and games. Our analyses reveal that interactive games are superior to standard benchmarks in discriminating models. Causal and logical reasoning correlate with both static and interactive tests, while differences emerge regarding core executive functions and social/emotional skills, which correlate more with games. We advocate the development of new interactive benchmarks and targeted cognitive tasks inspired by assessing human abilities but designed specifically for LLMs.
Shaking Up VLMs: Comparing Transformers and Structured State Space Models for Vision & Language Modeling
Sep 09, 2024
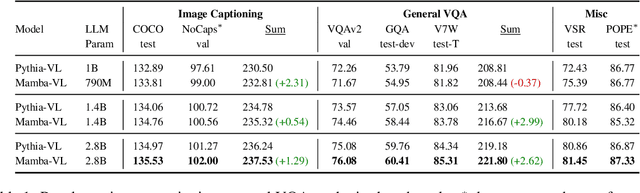
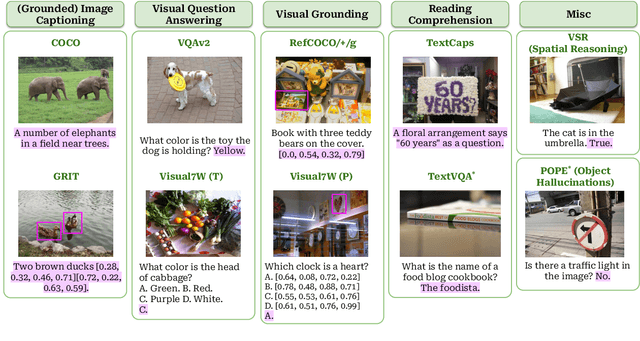
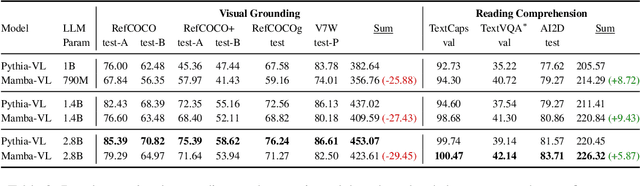
This study explores replacing Transformers in Visual Language Models (VLMs) with Mamba, a recent structured state space model (SSM) that demonstrates promising performance in sequence modeling. We test models up to 3B parameters under controlled conditions, showing that Mamba-based VLMs outperforms Transformers-based VLMs in captioning, question answering, and reading comprehension. However, we find that Transformers achieve greater performance in visual grounding and the performance gap widens with scale. We explore two hypotheses to explain this phenomenon: 1) the effect of task-agnostic visual encoding on the updates of the hidden states, and 2) the difficulty in performing visual grounding from the perspective of in-context multimodal retrieval. Our results indicate that a task-aware encoding yields minimal performance gains on grounding, however, Transformers significantly outperform Mamba at in-context multimodal retrieval. Overall, Mamba shows promising performance on tasks where the correct output relies on a summary of the image but struggles when retrieval of explicit information from the context is required.
AlanaVLM: A Multimodal Embodied AI Foundation Model for Egocentric Video Understanding
Jun 19, 2024AI personal assistants deployed via robots or wearables require embodied understanding to collaborate with humans effectively. However, current Vision-Language Models (VLMs) primarily focus on third-person view videos, neglecting the richness of egocentric perceptual experience. To address this gap, we propose three key contributions. First, we introduce the Egocentric Video Understanding Dataset (EVUD) for training VLMs on video captioning and question answering tasks specific to egocentric videos. Second, we present AlanaVLM, a 7B parameter VLM trained using parameter-efficient methods on EVUD. Finally, we evaluate AlanaVLM's capabilities on OpenEQA, a challenging benchmark for embodied video question answering. Our model achieves state-of-the-art performance, outperforming open-source models including strong Socratic models using GPT-4 as a planner by 3.6%. Additionally, we outperform Claude 3 and Gemini Pro Vision 1.0 and showcase competitive results compared to Gemini Pro 1.5 and GPT-4V, even surpassing the latter in spatial reasoning. This research paves the way for building efficient VLMs that can be deployed in robots or wearables, leveraging embodied video understanding to collaborate seamlessly with humans in everyday tasks, contributing to the next generation of Embodied AI
Lost in Space: Probing Fine-grained Spatial Understanding in Vision and Language Resamplers
Apr 21, 2024



An effective method for combining frozen large language models (LLM) and visual encoders involves a resampler module that creates a `visual prompt' which is provided to the LLM, along with the textual prompt. While this approach has enabled impressive performance across many coarse-grained tasks like image captioning and visual question answering, more fine-grained tasks that require spatial understanding have not been thoroughly examined. In this paper, we use \textit{diagnostic classifiers} to measure the extent to which the visual prompt produced by the resampler encodes spatial information. Our results show that this information is largely absent from the resampler output when kept frozen during training of the classifiers. However, when the resampler and classifier are trained jointly, we observe a significant performance boost. This shows that the compression achieved by the resamplers can in principle encode the requisite spatial information, but that more object-aware objectives are needed at the pretraining stage to facilitate this capability
Socially Pertinent Robots in Gerontological Healthcare
Apr 11, 2024
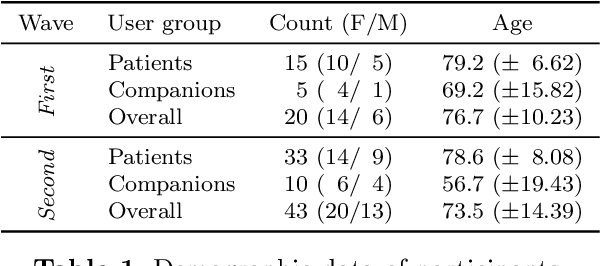
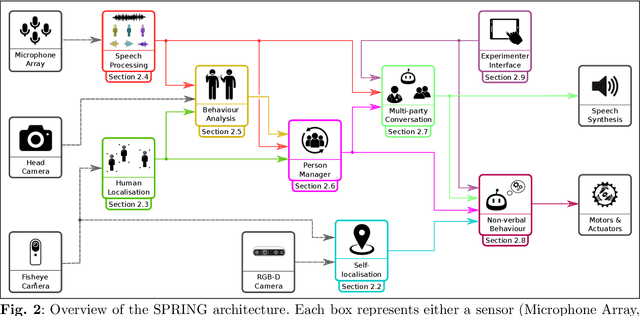
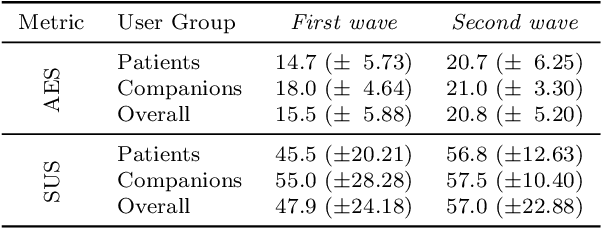
Despite the many recent achievements in developing and deploying social robotics, there are still many underexplored environments and applications for which systematic evaluation of such systems by end-users is necessary. While several robotic platforms have been used in gerontological healthcare, the question of whether or not a social interactive robot with multi-modal conversational capabilities will be useful and accepted in real-life facilities is yet to be answered. This paper is an attempt to partially answer this question, via two waves of experiments with patients and companions in a day-care gerontological facility in Paris with a full-sized humanoid robot endowed with social and conversational interaction capabilities. The software architecture, developed during the H2020 SPRING project, together with the experimental protocol, allowed us to evaluate the acceptability (AES) and usability (SUS) with more than 60 end-users. Overall, the users are receptive to this technology, especially when the robot perception and action skills are robust to environmental clutter and flexible to handle a plethora of different interactions.
NLP Verification: Towards a General Methodology for Certifying Robustness
Mar 15, 2024Deep neural networks have exhibited substantial success in the field of Natural Language Processing (NLP) and ensuring their safety and reliability is crucial: there are safety critical contexts where such models must be robust to variability or attack, and give guarantees over their output. Unlike Computer Vision, NLP lacks a unified verification methodology and, despite recent advancements in literature, they are often light on the pragmatical issues of NLP verification. In this paper, we make an attempt to distil and evaluate general components of an NLP verification pipeline, that emerges from the progress in the field to date. Our contributions are two-fold. Firstly, we give a general characterisation of verifiable subspaces that result from embedding sentences into continuous spaces. We identify, and give an effective method to deal with, the technical challenge of semantic generalisability of verified subspaces; and propose it as a standard metric in the NLP verification pipelines (alongside with the standard metrics of model accuracy and model verifiability). Secondly, we propose a general methodology to analyse the effect of the embedding gap, a problem that refers to the discrepancy between verification of geometric subpspaces on the one hand, and semantic meaning of sentences which the geometric subspaces are supposed to represent, on the other hand. In extreme cases, poor choices in embedding of sentences may invalidate verification results. We propose a number of practical NLP methods that can help to identify the effects of the embedding gap; and in particular we propose the metric of falsifiability of semantic subpspaces as another fundamental metric to be reported as part of the NLP verification pipeline. We believe that together these general principles pave the way towards a more consolidated and effective development of this new domain.
Visually Grounded Language Learning: a review of language games, datasets, tasks, and models
Dec 05, 2023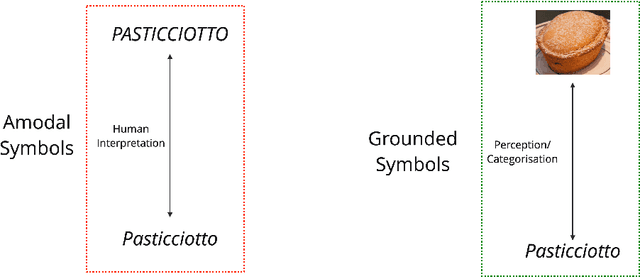
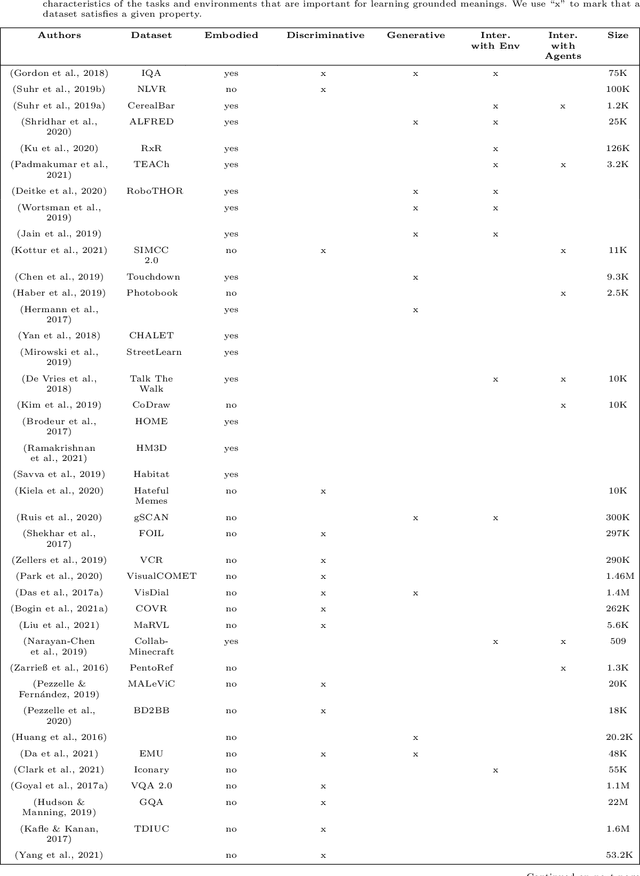
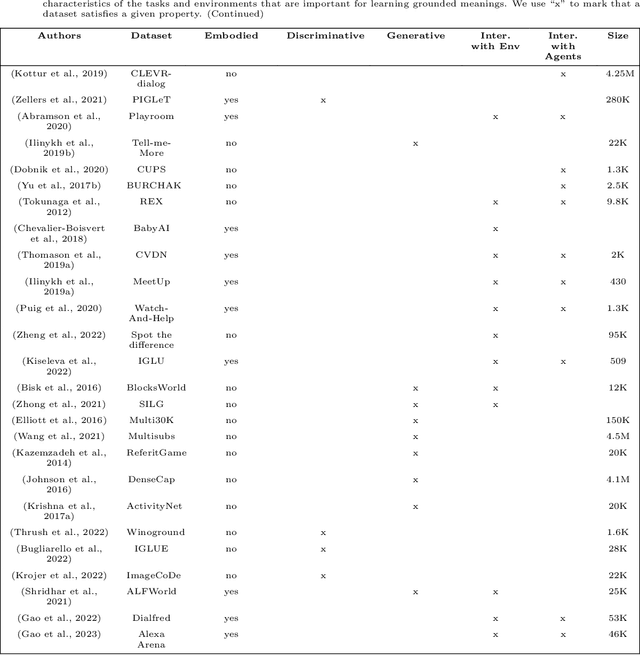
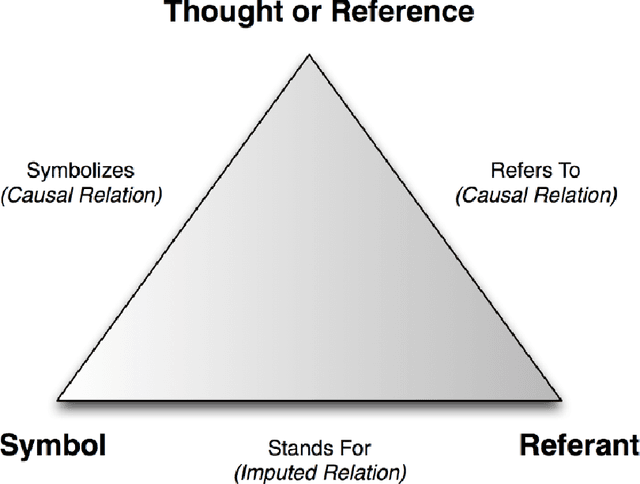
In recent years, several machine learning models have been proposed. They are trained with a language modelling objective on large-scale text-only data. With such pretraining, they can achieve impressive results on many Natural Language Understanding and Generation tasks. However, many facets of meaning cannot be learned by ``listening to the radio" only. In the literature, many Vision+Language (V+L) tasks have been defined with the aim of creating models that can ground symbols in the visual modality. In this work, we provide a systematic literature review of several tasks and models proposed in the V+L field. We rely on Wittgenstein's idea of `language games' to categorise such tasks into 3 different families: 1) discriminative games, 2) generative games, and 3) interactive games. Our analysis of the literature provides evidence that future work should be focusing on interactive games where communication in Natural Language is important to resolve ambiguities about object referents and action plans and that physical embodiment is essential to understand the semantics of situations and events. Overall, these represent key requirements for developing grounded meanings in neural models.
Multitask Multimodal Prompted Training for Interactive Embodied Task Completion
Nov 07, 2023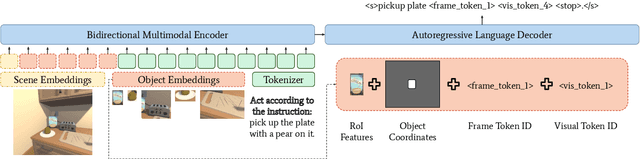
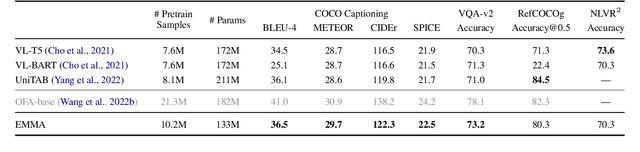
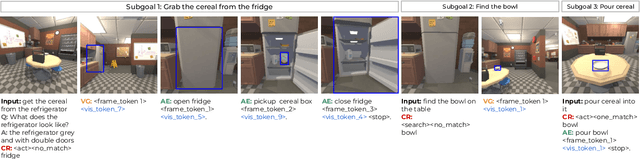
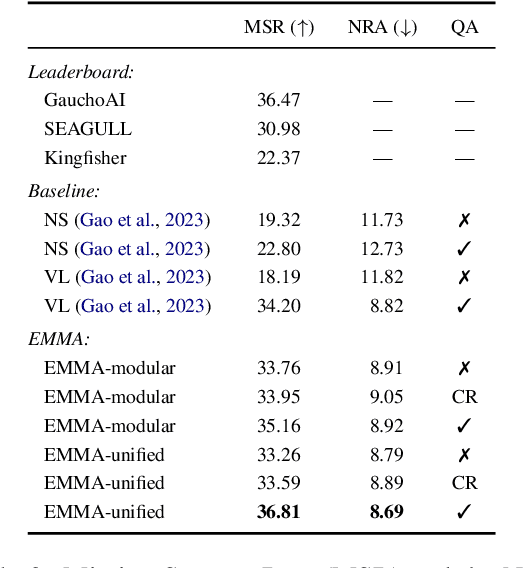
Interactive and embodied tasks pose at least two fundamental challenges to existing Vision & Language (VL) models, including 1) grounding language in trajectories of actions and observations, and 2) referential disambiguation. To tackle these challenges, we propose an Embodied MultiModal Agent (EMMA): a unified encoder-decoder model that reasons over images and trajectories, and casts action prediction as multimodal text generation. By unifying all tasks as text generation, EMMA learns a language of actions which facilitates transfer across tasks. Different to previous modular approaches with independently trained components, we use a single multitask model where each task contributes to goal completion. EMMA performs on par with similar models on several VL benchmarks and sets a new state-of-the-art performance (36.81% success rate) on the Dialog-guided Task Completion (DTC), a benchmark to evaluate dialog-guided agents in the Alexa Arena
Detecting Agreement in Multi-party Conversational AI
Nov 06, 2023Today, conversational systems are expected to handle conversations in multi-party settings, especially within Socially Assistive Robots (SARs). However, practical usability remains difficult as there are additional challenges to overcome, such as speaker recognition, addressee recognition, and complex turn-taking. In this paper, we present our work on a multi-party conversational system, which invites two users to play a trivia quiz game. The system detects users' agreement or disagreement on a final answer and responds accordingly. Our evaluation includes both performance and user assessment results, with a focus on detecting user agreement. Our annotated transcripts and the code for the proposed system have been released open-source on GitHub.