 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenSocInt: A Multi-modal Training Environment for Human-Aware Social Navigation
Jan 05, 2026In this paper, we introduce OpenSocInt, an open-source software package providing a simulator for multi-modal social interactions and a modular architecture to train social agents. We described the software package and showcased its interest via an experimental protocol based on the task of social navigation. Our framework allows for exploring the use of different perceptual features, their encoding and fusion, as well as the use of different agents. The software is already publicly available under GPL at https://gitlab.inria.fr/robotlearn/OpenSocInt/.
Socially Pertinent Robots in Gerontological Healthcare
Apr 11, 2024
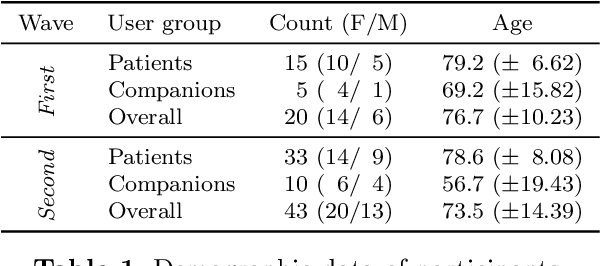
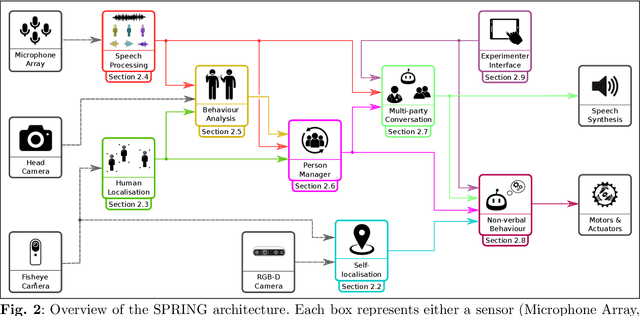
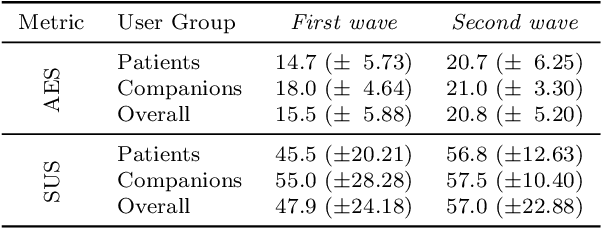
Despite the many recent achievements in developing and deploying social robotics, there are still many underexplored environments and applications for which systematic evaluation of such systems by end-users is necessary. While several robotic platforms have been used in gerontological healthcare, the question of whether or not a social interactive robot with multi-modal conversational capabilities will be useful and accepted in real-life facilities is yet to be answered. This paper is an attempt to partially answer this question, via two waves of experiments with patients and companions in a day-care gerontological facility in Paris with a full-sized humanoid robot endowed with social and conversational interaction capabilities. The software architecture, developed during the H2020 SPRING project, together with the experimental protocol, allowed us to evaluate the acceptability (AES) and usability (SUS) with more than 60 end-users. Overall, the users are receptive to this technology, especially when the robot perception and action skills are robust to environmental clutter and flexible to handle a plethora of different interactions.
Variational Meta Reinforcement Learning for Social Robotics
Jun 23, 2022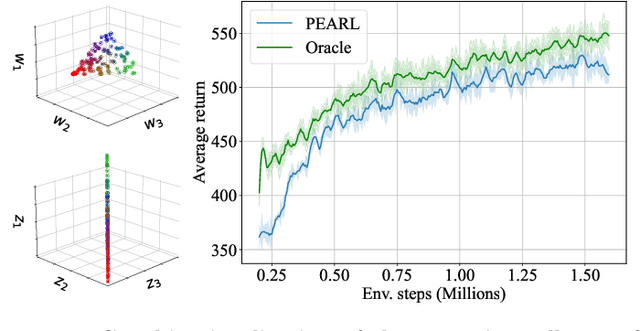
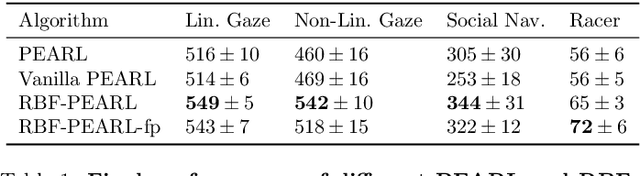
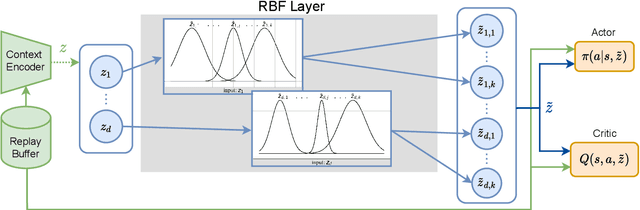

With the increasing presence of robots in our every-day environments, improving their social skills is of utmost importance. Nonetheless, social robotics still faces many challenges. One bottleneck is that robotic behaviors need to be often adapted as social norms depend strongly on the environment. For example, a robot should navigate more carefully around patients in a hospital compared to workers in an office. In this work, we investigate meta-reinforcement learning (meta-RL) as a potential solution. Here, robot behaviors are learned via reinforcement learning where a reward function needs to be chosen so that the robot learns an appropriate behavior for a given environment. We propose to use a variational meta-RL procedure that quickly adapts the robots' behavior to new reward functions. As a result, given a new environment different reward functions can be quickly evaluated and an appropriate one selected. The procedure learns a vectorized representation for reward functions and a meta-policy that can be conditioned on such a representation. Given observations from a new reward function, the procedure identifies its representation and conditions the meta-policy to it. While investigating the procedures' capabilities, we realized that it suffers from posterior collapse where only a subset of the dimensions in the representation encode useful information resulting in a reduced performance. Our second contribution, a radial basis function (RBF) layer, partially mitigates this negative effect. The RBF layer lifts the representation to a higher dimensional space, which is more easily exploitable for the meta-policy. We demonstrate the interest of the RBF layer and the usage of meta-RL for social robotics on four robotic simulation tasks.
Successor Feature Neural Episodic Control
Nov 04, 2021

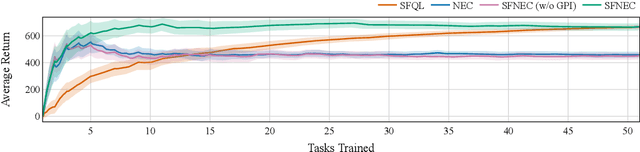
A longstanding goal in reinforcement learning is to build intelligent agents that show fast learning and a flexible transfer of skills akin to humans and animals. This paper investigates the integration of two frameworks for tackling those goals: episodic control and successor features. Episodic control is a cognitively inspired approach relying on episodic memory, an instance-based memory model of an agent's experiences. Meanwhile, successor features and generalized policy improvement (SF&GPI) is a meta and transfer learning framework allowing to learn policies for tasks that can be efficiently reused for later tasks which have a different reward function. Individually, these two techniques have shown impressive results in vastly improving sample efficiency and the elegant reuse of previously learned policies. Thus, we outline a combination of both approaches in a single reinforcement learning framework and empirically illustrate its benefits.
Xi-Learning: Successor Feature Transfer Learning for General Reward Functions
Oct 29, 2021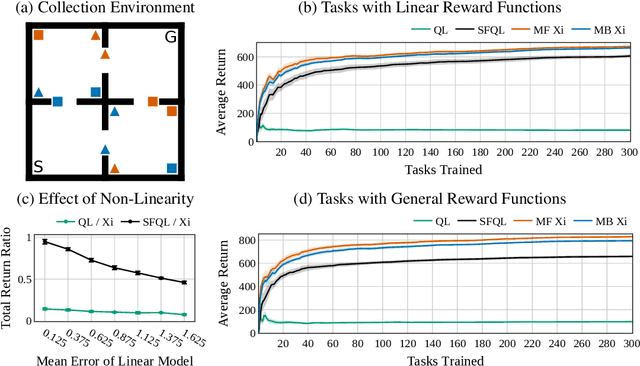

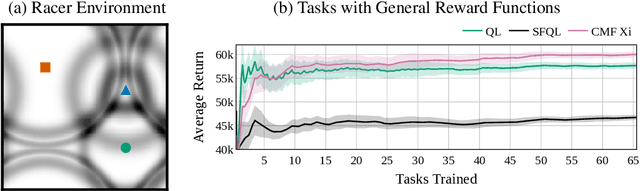

Transfer in Reinforcement Learning aims to improve learning performance on target tasks using knowledge from experienced source tasks. Successor features (SF) are a prominent transfer mechanism in domains where the reward function changes between tasks. They reevaluate the expected return of previously learned policies in a new target task and to transfer their knowledge. A limiting factor of the SF framework is its assumption that rewards linearly decompose into successor features and a reward weight vector. We propose a novel SF mechanism, $\xi$-learning, based on learning the cumulative discounted probability of successor features. Crucially, $\xi$-learning allows to reevaluate the expected return of policies for general reward functions. We introduce two $\xi$-learning variations, prove its convergence, and provide a guarantee on its transfer performance. Experimental evaluations based on $\xi$-learning with function approximation demonstrate the prominent advantage of $\xi$-learning over available mechanisms not only for general reward functions, but also in the case of linearly decomposable reward functions.
Progressive growing of self-organized hierarchical representations for exploration
May 13, 2020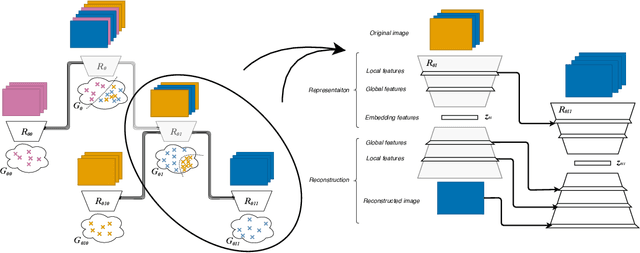

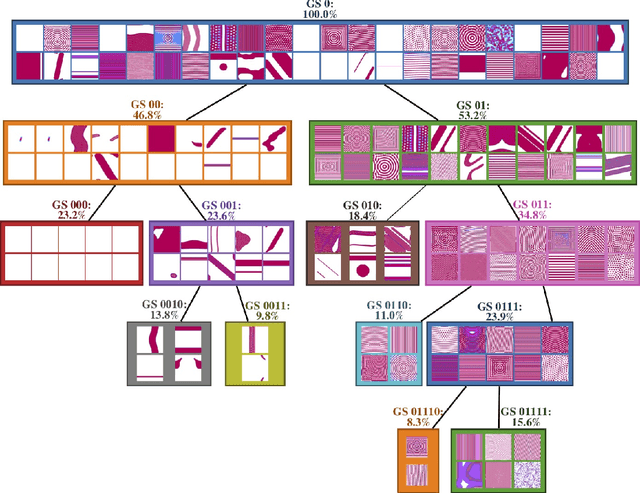

Designing agent that can autonomously discover and learn a diversity of structures and skills in unknown changing environments is key for lifelong machine learning. A central challenge is how to learn incrementally representations in order to progressively build a map of the discovered structures and re-use it to further explore. To address this challenge, we identify and target several key functionalities. First, we aim to build lasting representations and avoid catastrophic forgetting throughout the exploration process. Secondly we aim to learn a diversity of representations allowing to discover a "diversity of diversity" of structures (and associated skills) in complex high-dimensional environments. Thirdly, we target representations that can structure the agent discoveries in a coarse-to-fine manner. Finally, we target the reuse of such representations to drive exploration toward an "interesting" type of diversity, for instance leveraging human guidance. Current approaches in state representation learning rely generally on monolithic architectures which do not enable all these functionalities. Therefore, we present a novel technique to progressively construct a Hierarchy of Observation Latent Models for Exploration Stratification, called HOLMES. This technique couples the use of a dynamic modular model architecture for representation learning with intrinsically-motivated goal exploration processes (IMGEPs). The paper shows results in the domain of automated discovery of diverse self-organized patterns, considering as testbed the experimental framework from Reinke et al. (2019).
Time Adaptive Reinforcement Learning
Apr 18, 2020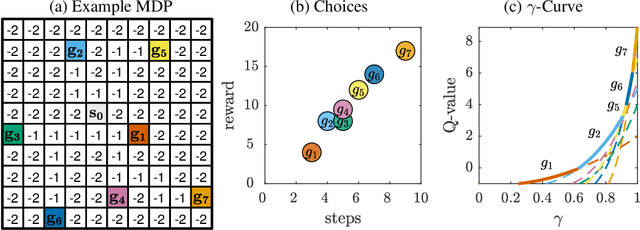
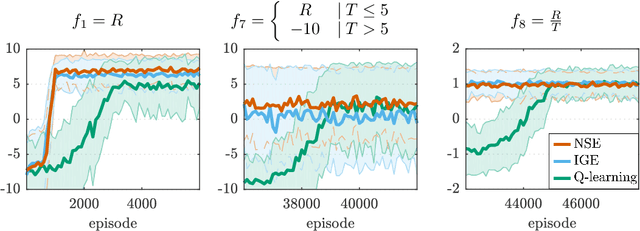
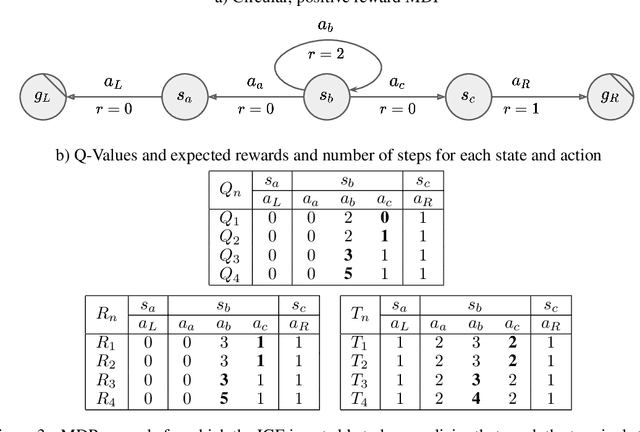
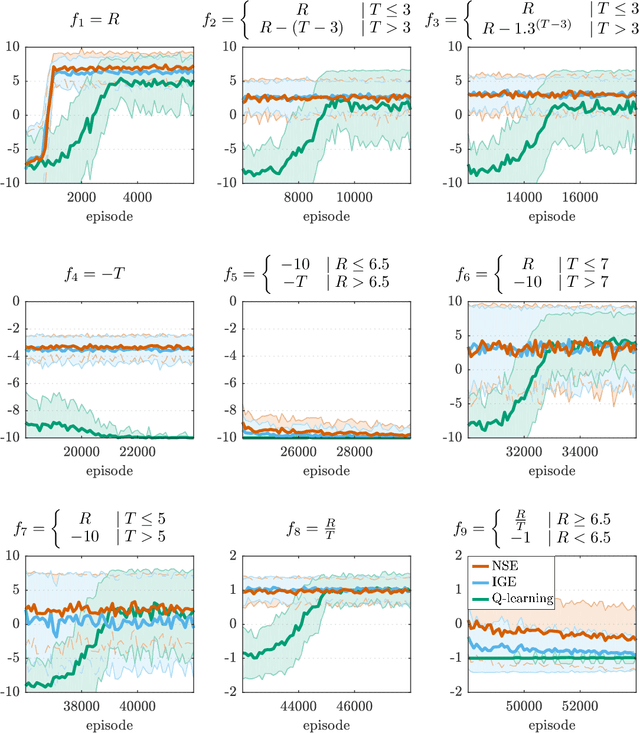
Reinforcement learning (RL) allows to solve complex tasks such as Go often with a stronger performance than humans. However, the learned behaviors are usually fixed to specific tasks and unable to adapt to different contexts. Here we consider the case of adapting RL agents to different time restrictions, such as finishing a task with a given time limit that might change from one task execution to the next. We define such problems as Time Adaptive Markov Decision Processes and introduce two model-free, value-based algorithms: the Independent Gamma-Ensemble and the n-Step Ensemble. In difference to classical approaches, they allow a zero-shot adaptation between different time restrictions. The proposed approaches represent general mechanisms to handle time adaptive tasks making them compatible with many existing RL methods, algorithms, and scenarios.
Intrinsically Motivated Discovery of Diverse Patterns in Self-Organizing Systems
Sep 30, 2019In many complex dynamical systems, artificial or natural, one can observe self-organization of patterns emerging from local rules. Cellular automata, like the Game of Life (GOL), have been widely used as abstract models enabling the study of various aspects of self-organization and morphogenesis, such as the emergence of spatially localized patterns. However, findings of self-organized patterns in such models have so far relied on manual tuning of parameters and initial states, and on the human eye to identify interesting patterns. In this paper, we formulate the problem of automated discovery of diverse self-organized patterns in such high-dimensional complex dynamical systems, as well as a framework for experimentation and evaluation. Using a continuous GOL as a testbed, we show that recent intrinsically-motivated machine learning algorithms (POP-IMGEPs), initially developed for learning of inverse models in robotics, can be transposed and used in this novel application area. These algorithms combine intrinsically-motivated goal exploration and unsupervised learning of goal space representations. Goal space representations describe the interesting features of patterns for which diverse variations should be discovered. In particular, we compare various approaches to define and learn goal space representations from the perspective of discovering diverse spatially localized patterns. Moreover, we introduce an extension of a state-of-the-art POP-IMGEP algorithm which incrementally learns a goal representation using a deep auto-encoder, and the use of CPPN primitives for generating initialization parameters. We show that it is more efficient than several baselines and equally efficient as a system pre-trained on a hand-made database of patterns identified by human experts.