 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescribe-Then-Act: Proactive Agent Steering via Distilled Language-Action World Models
Mar 24, 2026Deploying safety-critical agents requires anticipating the consequences of actions before they are executed. While world models offer a paradigm for this proactive foresight, current approaches relying on visual simulation incur prohibitive latencies, often exceeding several seconds per step. In this work, we challenge the assumption that visual processing is necessary for failure prevention. We show that a trained policy's latent state, combined with its planned actions, already encodes sufficient information to anticipate action outcomes, making visual simulation redundant for failure prevention. To this end, we introduce DILLO (DIstiLLed Language-ActiOn World Model), a fast steering layer that shifts the paradigm from "simulate-then-act" to "describe-then-act." DILLO is trained via cross-modal distillation, where a privileged Vision Language Model teacher annotates offline trajectories and a latent-conditioned Large Language Model student learns to predict semantic outcomes. This creates a text-only inference path, bypassing heavy visual generation entirely, achieving a 14x speedup over baselines. Experiments on MetaWorld and LIBERO demonstrate that DILLO produces high-fidelity descriptions of the next state and is able to steer the policy, improving episode success rate by up to 15 pp and 9.3 pp on average across tasks.
The Equalizer: Introducing Shape-Gain Decomposition in Neural Audio Codecs
Feb 17, 2026Neural audio codecs (NACs) typically encode the short-term energy (gain) and normalized structure (shape) of speech/audio signals jointly within the same latent space. As a result, they are poorly robust to a global variation of the input signal level in the sense that such variation has strong influence on the embedding vectors at the output of the encoder and their quantization. This methodology is inherently inefficient, leading to codebook redundancy and suboptimal bitrate-distortion performance. To address these limitations, we propose to introduce shape-gain decomposition, widely used in classical speech/audio coding, into the NAC framework. The principle of the proposed Equalizer methodology is to decompose the input signal -- before the NAC encoder -- into gain and normalized shape vector on a short-term basis. The shape vector is processed by the NAC, while the gain is quantized with scalar quantization and transmitted separately. The output (decoded) signal is reconstructed from the normalized output of the NAC and the quantized gain. Our experiments conducted on speech signals show that this general methodology, easily applicable to any NAC, enables a substantial gain in bitrate-distortion performance, as well as a massive reduction in complexity.
Residual Tokens Enhance Masked Autoencoders for Speech Modeling
Jan 27, 2026Recent speech modeling relies on explicit attributes such as pitch, content, and speaker identity, but these alone cannot capture the full richness of natural speech. We introduce RT-MAE, a novel masked autoencoder framework that augments the supervised attributes-based modeling with unsupervised residual trainable tokens, designed to encode the information not explained by explicit labeled factors (e.g., timbre variations, noise, emotion etc). Experiments show that RT-MAE improves reconstruction quality, preserving content and speaker similarity while enhancing expressivity. We further demonstrate its applicability to speech enhancement, removing noise at inference while maintaining controllability and naturalness.
OpenSocInt: A Multi-modal Training Environment for Human-Aware Social Navigation
Jan 05, 2026In this paper, we introduce OpenSocInt, an open-source software package providing a simulator for multi-modal social interactions and a modular architecture to train social agents. We described the software package and showcased its interest via an experimental protocol based on the task of social navigation. Our framework allows for exploring the use of different perceptual features, their encoding and fusion, as well as the use of different agents. The software is already publicly available under GPL at https://gitlab.inria.fr/robotlearn/OpenSocInt/.
Modeling strategies for speech enhancement in the latent space of a neural audio codec
Oct 30, 2025Neural audio codecs (NACs) provide compact latent speech representations in the form of sequences of continuous vectors or discrete tokens. In this work, we investigate how these two types of speech representations compare when used as training targets for supervised speech enhancement. We consider both autoregressive and non-autoregressive speech enhancement models based on the Conformer architecture, as well as a simple baseline where the NAC encoder is simply fine-tuned for speech enhancement. Our experiments reveal three key findings: predicting continuous latent representations consistently outperforms discrete token prediction; autoregressive models achieve higher quality but at the expense of intelligibility and efficiency, making non-autoregressive models more attractive in practice; and encoder fine-tuning yields the strongest enhancement metrics overall, though at the cost of degraded codec reconstruction. The code and audio samples are available online.
Posterior Transition Modeling for Unsupervised Diffusion-Based Speech Enhancement
Jul 03, 2025

We explore unsupervised speech enhancement using diffusion models as expressive generative priors for clean speech. Existing approaches guide the reverse diffusion process using noisy speech through an approximate, noise-perturbed likelihood score, combined with the unconditional score via a trade-off hyperparameter. In this work, we propose two alternative algorithms that directly model the conditional reverse transition distribution of diffusion states. The first method integrates the diffusion prior with the observation model in a principled way, removing the need for hyperparameter tuning. The second defines a diffusion process over the noisy speech itself, yielding a fully tractable and exact likelihood score. Experiments on the WSJ0-QUT and VoiceBank-DEMAND datasets demonstrate improved enhancement metrics and greater robustness to domain shifts compared to both supervised and unsupervised baselines.
AnCoGen: Analysis, Control and Generation of Speech with a Masked Autoencoder
Jan 09, 2025This article introduces AnCoGen, a novel method that leverages a masked autoencoder to unify the analysis, control, and generation of speech signals within a single model. AnCoGen can analyze speech by estimating key attributes, such as speaker identity, pitch, content, loudness, signal-to-noise ratio, and clarity index. In addition, it can generate speech from these attributes and allow precise control of the synthesized speech by modifying them. Extensive experiments demonstrated the effectiveness of AnCoGen across speech analysis-resynthesis, pitch estimation, pitch modification, and speech enhancement.
Diffusion-based Unsupervised Audio-visual Speech Enhancement
Oct 04, 2024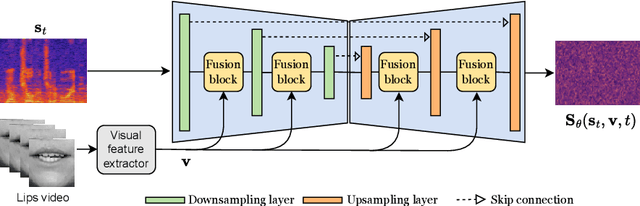
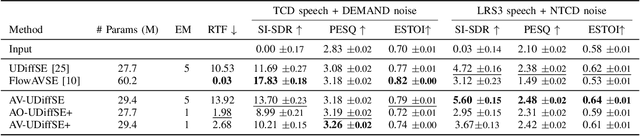
This paper proposes a new unsupervised audiovisual speech enhancement (AVSE) approach that combines a diffusion-based audio-visual speech generative model with a non-negative matrix factorization (NMF) noise model. First, the diffusion model is pre-trained on clean speech conditioned on corresponding video data to simulate the speech generative distribution. This pre-trained model is then paired with the NMF-based noise model to iteratively estimate clean speech. Specifically, a diffusion-based posterior sampling approach is implemented within the reverse diffusion process, where after each iteration, a speech estimate is obtained and used to update the noise parameters. Experimental results confirm that the proposed AVSE approach not only outperforms its audio-only counterpart but also generalizes better than a recent supervisedgenerative AVSE method. Additionally, the new inference algorithm offers a better balance between inference speed and performance compared to the previous diffusion-based method.
Lost and Found: Overcoming Detector Failures in Online Multi-Object Tracking
Jul 16, 2024Multi-object tracking (MOT) endeavors to precisely estimate the positions and identities of multiple objects over time. The prevailing approach, tracking-by-detection (TbD), first detects objects and then links detections, resulting in a simple yet effective method. However, contemporary detectors may occasionally miss some objects in certain frames, causing trackers to cease tracking prematurely. To tackle this issue, we propose BUSCA, meaning `to search', a versatile framework compatible with any online TbD system, enhancing its ability to persistently track those objects missed by the detector, primarily due to occlusions. Remarkably, this is accomplished without modifying past tracking results or accessing future frames, i.e., in a fully online manner. BUSCA generates proposals based on neighboring tracks, motion, and learned tokens. Utilizing a decision Transformer that integrates multimodal visual and spatiotemporal information, it addresses the object-proposal association as a multi-choice question-answering task. BUSCA is trained independently of the underlying tracker, solely on synthetic data, without requiring fine-tuning. Through BUSCA, we showcase consistent performance enhancements across five different trackers and establish a new state-of-the-art baseline across three different benchmarks. Code available at: https://github.com/lorenzovaquero/BUSCA.
MEGA: Masked Generative Autoencoder for Human Mesh Recovery
May 29, 2024Human Mesh Recovery (HMR) from a single RGB image is a highly ambiguous problem, as similar 2D projections can correspond to multiple 3D interpretations. Nevertheless, most HMR methods overlook this ambiguity and make a single prediction without accounting for the associated uncertainty. A few approaches generate a distribution of human meshes, enabling the sampling of multiple predictions; however, none of them is competitive with the latest single-output model when making a single prediction. This work proposes a new approach based on masked generative modeling. By tokenizing the human pose and shape, we formulate the HMR task as generating a sequence of discrete tokens conditioned on an input image. We introduce MEGA, a MaskEd Generative Autoencoder trained to recover human meshes from images and partial human mesh token sequences. Given an image, our flexible generation scheme allows us to predict a single human mesh in deterministic mode or to generate multiple human meshes in stochastic mode. MEGA enables us to propose multiple outputs and to evaluate the uncertainty of the predictions. Experiments on in-the-wild benchmarks show that MEGA achieves state-of-the-art performance in deterministic and stochastic modes, outperforming single-output and multi-output approaches.