 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosterior Transition Modeling for Unsupervised Diffusion-Based Speech Enhancement
Jul 03, 2025

We explore unsupervised speech enhancement using diffusion models as expressive generative priors for clean speech. Existing approaches guide the reverse diffusion process using noisy speech through an approximate, noise-perturbed likelihood score, combined with the unconditional score via a trade-off hyperparameter. In this work, we propose two alternative algorithms that directly model the conditional reverse transition distribution of diffusion states. The first method integrates the diffusion prior with the observation model in a principled way, removing the need for hyperparameter tuning. The second defines a diffusion process over the noisy speech itself, yielding a fully tractable and exact likelihood score. Experiments on the WSJ0-QUT and VoiceBank-DEMAND datasets demonstrate improved enhancement metrics and greater robustness to domain shifts compared to both supervised and unsupervised baselines.
Diffusion-based Unsupervised Audio-visual Speech Enhancement
Oct 04, 2024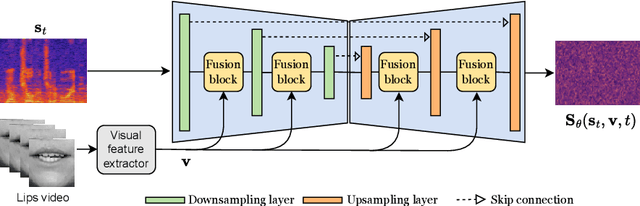
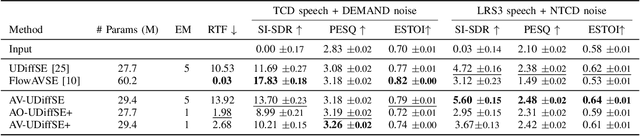
This paper proposes a new unsupervised audiovisual speech enhancement (AVSE) approach that combines a diffusion-based audio-visual speech generative model with a non-negative matrix factorization (NMF) noise model. First, the diffusion model is pre-trained on clean speech conditioned on corresponding video data to simulate the speech generative distribution. This pre-trained model is then paired with the NMF-based noise model to iteratively estimate clean speech. Specifically, a diffusion-based posterior sampling approach is implemented within the reverse diffusion process, where after each iteration, a speech estimate is obtained and used to update the noise parameters. Experimental results confirm that the proposed AVSE approach not only outperforms its audio-only counterpart but also generalizes better than a recent supervisedgenerative AVSE method. Additionally, the new inference algorithm offers a better balance between inference speed and performance compared to the previous diffusion-based method.
Diffusion-based speech enhancement with a weighted generative-supervised learning loss
Sep 19, 2023Diffusion-based generative models have recently gained attention in speech enhancement (SE), providing an alternative to conventional supervised methods. These models transform clean speech training samples into Gaussian noise centered at noisy speech, and subsequently learn a parameterized model to reverse this process, conditionally on noisy speech. Unlike supervised methods, generative-based SE approaches usually rely solely on an unsupervised loss, which may result in less efficient incorporation of conditioned noisy speech. To address this issue, we propose augmenting the original diffusion training objective with a mean squared error (MSE) loss, measuring the discrepancy between estimated enhanced speech and ground-truth clean speech at each reverse process iteration. Experimental results demonstrate the effectiveness of our proposed methodology.