 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Skeletal and Signer Noise Reduction in Sign Language Production via Quaternion-Based Pose Encoding and Contrastive Learning
Aug 20, 2025One of the main challenges in neural sign language production (SLP) lies in the high intra-class variability of signs, arising from signer morphology and stylistic variety in the training data. To improve robustness to such variations, we propose two enhancements to the standard Progressive Transformers (PT) architecture (Saunders et al., 2020). First, we encode poses using bone rotations in quaternion space and train with a geodesic loss to improve the accuracy and clarity of angular joint movements. Second, we introduce a contrastive loss to structure decoder embeddings by semantic similarity, using either gloss overlap or SBERT-based sentence similarity, aiming to filter out anatomical and stylistic features that do not convey relevant semantic information. On the Phoenix14T dataset, the contrastive loss alone yields a 16% improvement in Probability of Correct Keypoint over the PT baseline. When combined with quaternion-based pose encoding, the model achieves a 6% reduction in Mean Bone Angle Error. These results point to the benefit of incorporating skeletal structure modeling and semantically guided contrastive objectives on sign pose representations into the training of Transformer-based SLP models.
Posterior Transition Modeling for Unsupervised Diffusion-Based Speech Enhancement
Jul 03, 2025

We explore unsupervised speech enhancement using diffusion models as expressive generative priors for clean speech. Existing approaches guide the reverse diffusion process using noisy speech through an approximate, noise-perturbed likelihood score, combined with the unconditional score via a trade-off hyperparameter. In this work, we propose two alternative algorithms that directly model the conditional reverse transition distribution of diffusion states. The first method integrates the diffusion prior with the observation model in a principled way, removing the need for hyperparameter tuning. The second defines a diffusion process over the noisy speech itself, yielding a fully tractable and exact likelihood score. Experiments on the WSJ0-QUT and VoiceBank-DEMAND datasets demonstrate improved enhancement metrics and greater robustness to domain shifts compared to both supervised and unsupervised baselines.
Joint Beamforming and Speaker-Attributed ASR for Real Distant-Microphone Meeting Transcription
Oct 29, 2024



Distant-microphone meeting transcription is a challenging task. State-of-the-art end-to-end speaker-attributed automatic speech recognition (SA-ASR) architectures lack a multichannel noise and reverberation reduction front-end, which limits their performance. In this paper, we introduce a joint beamforming and SA-ASR approach for real meeting transcription. We first describe a data alignment and augmentation method to pretrain a neural beamformer on real meeting data. We then compare fixed, hybrid, and fully neural beamformers as front-ends to the SA-ASR model. Finally, we jointly optimize the fully neural beamformer and the SA-ASR model. Experiments on the real AMI corpus show that,while state-of-the-art multi-frame cross-channel attention based channel fusion fails to improve ASR performance, fine-tuning SA-ASR on the fixed beamformer's output and jointly fine-tuning SA-ASR with the neural beamformer reduce the word error rate by 8% and 9% relative, respectively.
Diffusion-based Unsupervised Audio-visual Speech Enhancement
Oct 04, 2024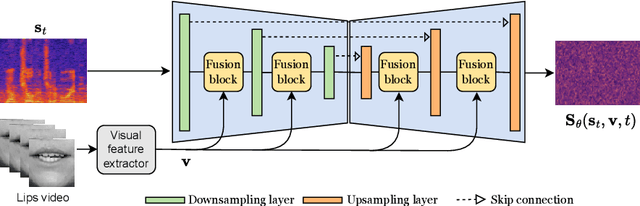
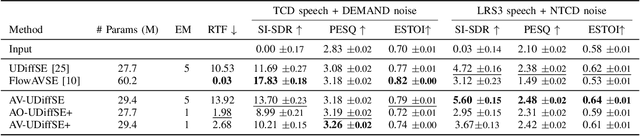
This paper proposes a new unsupervised audiovisual speech enhancement (AVSE) approach that combines a diffusion-based audio-visual speech generative model with a non-negative matrix factorization (NMF) noise model. First, the diffusion model is pre-trained on clean speech conditioned on corresponding video data to simulate the speech generative distribution. This pre-trained model is then paired with the NMF-based noise model to iteratively estimate clean speech. Specifically, a diffusion-based posterior sampling approach is implemented within the reverse diffusion process, where after each iteration, a speech estimate is obtained and used to update the noise parameters. Experimental results confirm that the proposed AVSE approach not only outperforms its audio-only counterpart but also generalizes better than a recent supervisedgenerative AVSE method. Additionally, the new inference algorithm offers a better balance between inference speed and performance compared to the previous diffusion-based method.
Improving Speaker Assignment in Speaker-Attributed ASR for Real Meeting Applications
Mar 11, 2024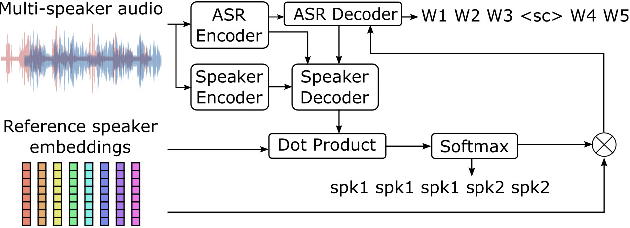
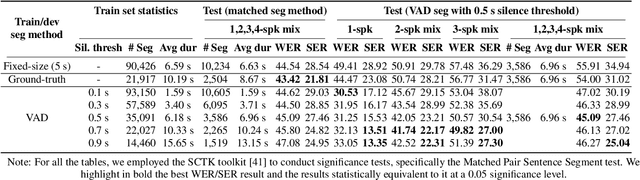
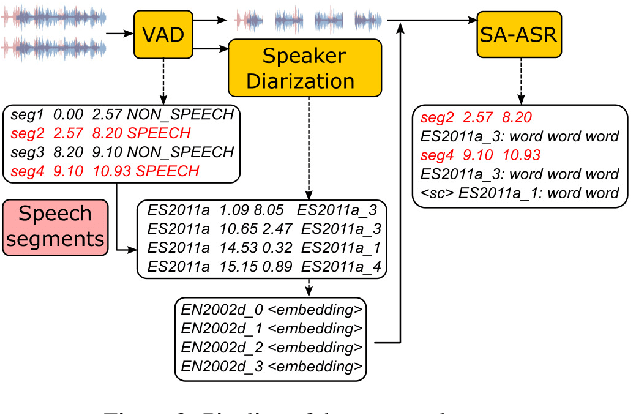
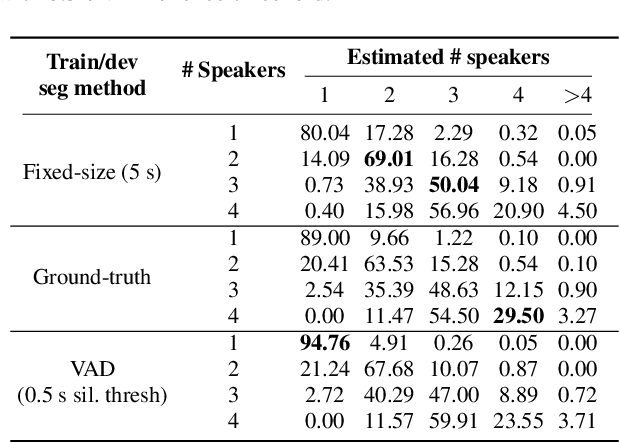
Past studies on end-to-end meeting transcription have focused on model architecture and have mostly been evaluated on simulated meeting data. We present a novel study aiming to optimize the use of a Speaker-Attributed ASR (SA-ASR) system in real-life scenarios, such as the AMI meeting corpus, for improved speaker assignment of speech segments. First, we propose a pipeline tailored to real-life applications involving Voice Activity Detection (VAD), Speaker Diarization (SD), and SA-ASR. Second, we advocate using VAD output segments to fine-tune the SA-ASR model, considering that it is also applied to VAD segments during test, and show that this results in a relative reduction of Speaker Error Rate (SER) up to 28%. Finally, we explore strategies to enhance the extraction of the speaker embedding templates used as inputs by the SA-ASR system. We show that extracting them from SD output rather than annotated speaker segments results in a relative SER reduction up to 20%.
Objective and subjective evaluation of speech enhancement methods in the UDASE task of the 7th CHiME challenge
Feb 02, 2024



Supervised models for speech enhancement are trained using artificially generated mixtures of clean speech and noise signals. However, the synthetic training conditions may not accurately reflect real-world conditions encountered during testing. This discrepancy can result in poor performance when the test domain significantly differs from the synthetic training domain. To tackle this issue, the UDASE task of the 7th CHiME challenge aimed to leverage real-world noisy speech recordings from the test domain for unsupervised domain adaptation of speech enhancement models. Specifically, this test domain corresponds to the CHiME-5 dataset, characterized by real multi-speaker and conversational speech recordings made in noisy and reverberant domestic environments, for which ground-truth clean speech signals are not available. In this paper, we present the objective and subjective evaluations of the systems that were submitted to the CHiME-7 UDASE task, and we provide an analysis of the results. This analysis reveals a limited correlation between subjective ratings and several supervised nonintrusive performance metrics recently proposed for speech enhancement. Conversely, the results suggest that more traditional intrusive objective metrics can be used for in-domain performance evaluation using the reverberant LibriCHiME-5 dataset developed for the challenge. The subjective evaluation indicates that all systems successfully reduced the background noise, but always at the expense of increased distortion. Out of the four speech enhancement methods evaluated subjectively, only one demonstrated an improvement in overall quality compared to the unprocessed noisy speech, highlighting the difficulty of the task. The tools and audio material created for the CHiME-7 UDASE task are shared with the community.
End-to-end Joint Rich and Normalized ASR with a limited amount of rich training data
Nov 29, 2023Joint rich and normalized automatic speech recognition (ASR), that produces transcriptions both with and without punctuation and capitalization, remains a challenge. End-to-end (E2E) ASR models offer both convenience and the ability to perform such joint transcription of speech. Training such models requires paired speech and rich text data, which is not widely available. In this paper, we compare two different approaches to train a stateless Transducer-based E2E joint rich and normalized ASR system, ready for streaming applications, with a limited amount of rich labeled data. The first approach uses a language model to generate pseudo-rich transcriptions of normalized training data. The second approach uses a single decoder conditioned on the type of the output. The first approach leads to E2E rich ASR which perform better on out-of-domain data, with up to 9% relative reduction in errors. The second approach demonstrates the feasibility of an E2E joint rich and normalized ASR system using as low as 5% rich training data with moderate (2.42% absolute) increase in errors.
End-to-end Multichannel Speaker-Attributed ASR: Speaker Guided Decoder and Input Feature Analysis
Oct 16, 2023We present an end-to-end multichannel speaker-attributed automatic speech recognition (MC-SA-ASR) system that combines a Conformer-based encoder with multi-frame crosschannel attention and a speaker-attributed Transformer-based decoder. To the best of our knowledge, this is the first model that efficiently integrates ASR and speaker identification modules in a multichannel setting. On simulated mixtures of LibriSpeech data, our system reduces the word error rate (WER) by up to 12% and 16% relative compared to previously proposed single-channel and multichannel approaches, respectively. Furthermore, we investigate the impact of different input features, including multichannel magnitude and phase information, on the ASR performance. Finally, our experiments on the AMI corpus confirm the effectiveness of our system for real-world multichannel meeting transcription.
Posterior sampling algorithms for unsupervised speech enhancement with recurrent variational autoencoder
Sep 19, 2023In this paper, we address the unsupervised speech enhancement problem based on recurrent variational autoencoder (RVAE). This approach offers promising generalization performance over the supervised counterpart. Nevertheless, the involved iterative variational expectation-maximization (VEM) process at test time, which relies on a variational inference method, results in high computational complexity. To tackle this issue, we present efficient sampling techniques based on Langevin dynamics and Metropolis-Hasting algorithms, adapted to the EM-based speech enhancement with RVAE. By directly sampling from the intractable posterior distribution within the EM process, we circumvent the intricacies of variational inference. We conduct a series of experiments, comparing the proposed methods with VEM and a state-of-the-art supervised speech enhancement approach based on diffusion models. The results reveal that our sampling-based algorithms significantly outperform VEM, not only in terms of computational efficiency but also in overall performance. Furthermore, when compared to the supervised baseline, our methods showcase robust generalization performance in mismatched test conditions.
Unsupervised speech enhancement with diffusion-based generative models
Sep 19, 2023Recently, conditional score-based diffusion models have gained significant attention in the field of supervised speech enhancement, yielding state-of-the-art performance. However, these methods may face challenges when generalising to unseen conditions. To address this issue, we introduce an alternative approach that operates in an unsupervised manner, leveraging the generative power of diffusion models. Specifically, in a training phase, a clean speech prior distribution is learnt in the short-time Fourier transform (STFT) domain using score-based diffusion models, allowing it to unconditionally generate clean speech from Gaussian noise. Then, we develop a posterior sampling methodology for speech enhancement by combining the learnt clean speech prior with a noise model for speech signal inference. The noise parameters are simultaneously learnt along with clean speech estimation through an iterative expectationmaximisation (EM) approach. To the best of our knowledge, this is the first work exploring diffusion-based generative models for unsupervised speech enhancement, demonstrating promising results compared to a recent variational auto-encoder (VAE)-based unsupervised approach and a state-of-the-art diffusion-based supervised method. It thus opens a new direction for future research in unsupervised speech enhancement.