 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Speaker Assignment in Speaker-Attributed ASR for Real Meeting Applications
Paper and Code
Mar 11, 2024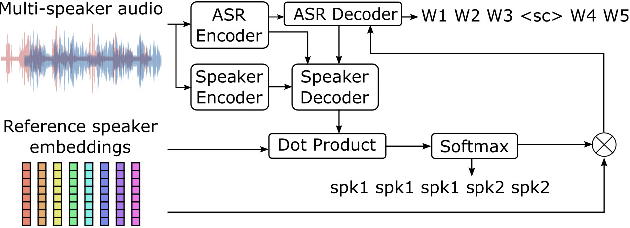
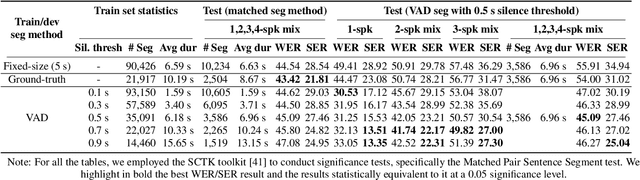
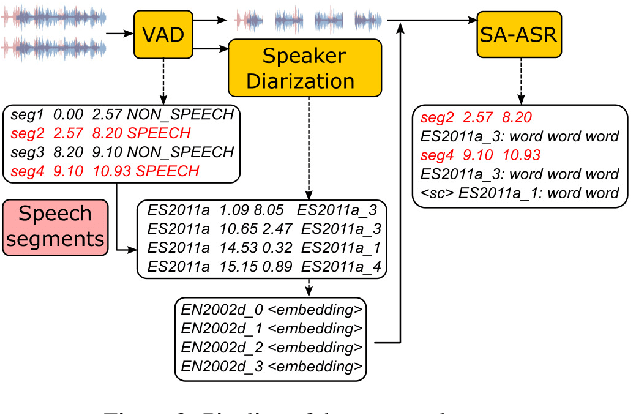
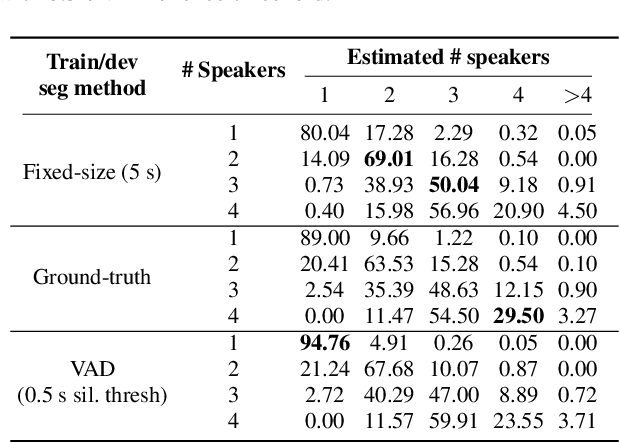
Past studies on end-to-end meeting transcription have focused on model architecture and have mostly been evaluated on simulated meeting data. We present a novel study aiming to optimize the use of a Speaker-Attributed ASR (SA-ASR) system in real-life scenarios, such as the AMI meeting corpus, for improved speaker assignment of speech segments. First, we propose a pipeline tailored to real-life applications involving Voice Activity Detection (VAD), Speaker Diarization (SD), and SA-ASR. Second, we advocate using VAD output segments to fine-tune the SA-ASR model, considering that it is also applied to VAD segments during test, and show that this results in a relative reduction of Speaker Error Rate (SER) up to 28%. Finally, we explore strategies to enhance the extraction of the speaker embedding templates used as inputs by the SA-ASR system. We show that extracting them from SD output rather than annotated speaker segments results in a relative SER reduction up to 20%.