 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Third VoicePrivacy Challenge: Preserving Emotional Expressiveness and Linguistic Content in Voice Anonymization
Jan 17, 2026We present results and analyses from the third VoicePrivacy Challenge held in 2024, which focuses on advancing voice anonymization technologies. The task was to develop a voice anonymization system for speech data that conceals a speaker's voice identity while preserving linguistic content and emotional state. We provide a systematic overview of the challenge framework, including detailed descriptions of the anonymization task and datasets used for both system development and evaluation. We outline the attack model and objective evaluation metrics for assessing privacy protection (concealing speaker voice identity) and utility (content and emotional state preservation). We describe six baseline anonymization systems and summarize the innovative approaches developed by challenge participants. Finally, we provide key insights and observations to guide the design of future VoicePrivacy challenges and identify promising directions for voice anonymization research.
Mixture of LoRA Experts for Low-Resourced Multi-Accent Automatic Speech Recognition
May 26, 2025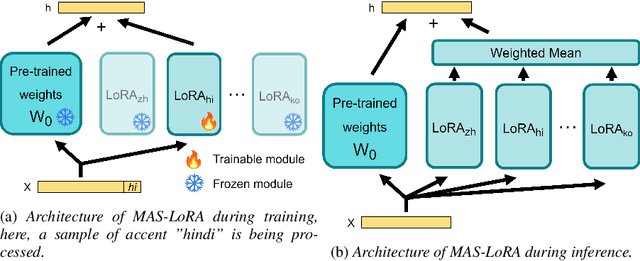
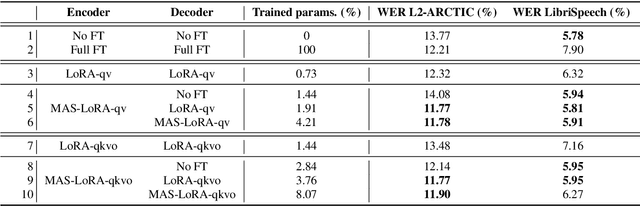
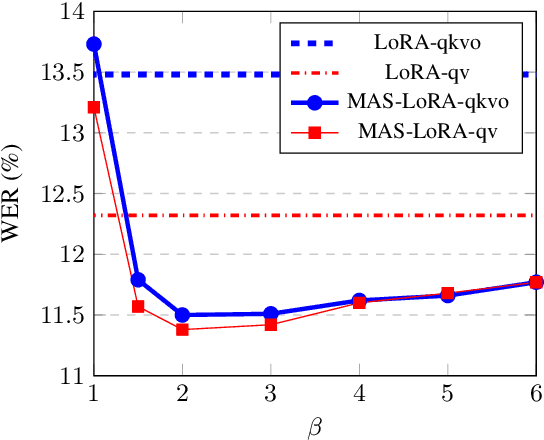
We aim to improve the robustness of Automatic Speech Recognition (ASR) systems against non-native speech, particularly in low-resourced multi-accent settings. We introduce Mixture of Accent-Specific LoRAs (MAS-LoRA), a fine-tuning method that leverages a mixture of Low-Rank Adaptation (LoRA) experts, each specialized in a specific accent. This method can be used when the accent is known or unknown at inference time, without the need to fine-tune the model again. Our experiments, conducted using Whisper on the L2-ARCTIC corpus, demonstrate significant improvements in Word Error Rate compared to regular LoRA and full fine-tuning when the accent is unknown. When the accent is known, the results further improve. Furthermore, MAS-LoRA shows less catastrophic forgetting than the other fine-tuning methods. To the best of our knowledge, this is the first use of a mixture of LoRA experts for non-native multi-accent ASR.
An Exhaustive Evaluation of TTS- and VC-based Data Augmentation for ASR
Mar 11, 2025



Augmenting the training data of automatic speech recognition (ASR) systems with synthetic data generated by text-to-speech (TTS) or voice conversion (VC) has gained popularity in recent years. Several works have demonstrated improvements in ASR performance using this augmentation approach. However, because of the lower diversity of synthetic speech, naively combining synthetic and real data often does not yield the best results. In this work, we leverage recently proposed flow-based TTS/VC models allowing greater speech diversity, and assess the respective impact of augmenting various speech attributes on the word error rate (WER) achieved by several ASR models. Pitch augmentation and VC-based speaker augmentation are found to be ineffective in our setup. Jointly augmenting all other attributes reduces the WER of a Conformer-Transducer model by 11\% relative on Common Voice and by up to 35\% relative on LibriSpeech compared to training on real data only.
Analysis of Speech Temporal Dynamics in the Context of Speaker Verification and Voice Anonymization
Dec 22, 2024In this paper, we investigate the impact of speech temporal dynamics in application to automatic speaker verification and speaker voice anonymization tasks. We propose several metrics to perform automatic speaker verification based only on phoneme durations. Experimental results demonstrate that phoneme durations leak some speaker information and can reveal speaker identity from both original and anonymized speech. Thus, this work emphasizes the importance of taking into account the speaker's speech rate and, more importantly, the speaker's phonetic duration characteristics, as well as the need to modify them in order to develop anonymization systems with strong privacy protection capacity.
Joint Beamforming and Speaker-Attributed ASR for Real Distant-Microphone Meeting Transcription
Oct 29, 2024



Distant-microphone meeting transcription is a challenging task. State-of-the-art end-to-end speaker-attributed automatic speech recognition (SA-ASR) architectures lack a multichannel noise and reverberation reduction front-end, which limits their performance. In this paper, we introduce a joint beamforming and SA-ASR approach for real meeting transcription. We first describe a data alignment and augmentation method to pretrain a neural beamformer on real meeting data. We then compare fixed, hybrid, and fully neural beamformers as front-ends to the SA-ASR model. Finally, we jointly optimize the fully neural beamformer and the SA-ASR model. Experiments on the real AMI corpus show that,while state-of-the-art multi-frame cross-channel attention based channel fusion fails to improve ASR performance, fine-tuning SA-ASR on the fixed beamformer's output and jointly fine-tuning SA-ASR with the neural beamformer reduce the word error rate by 8% and 9% relative, respectively.
The First VoicePrivacy Attacker Challenge Evaluation Plan
Oct 09, 2024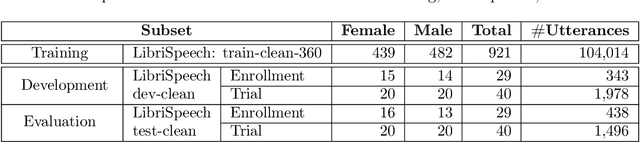
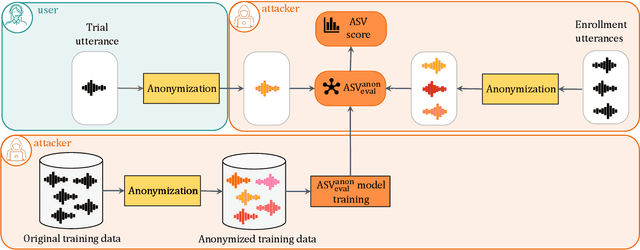
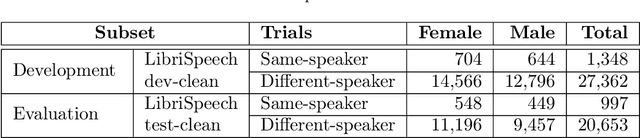
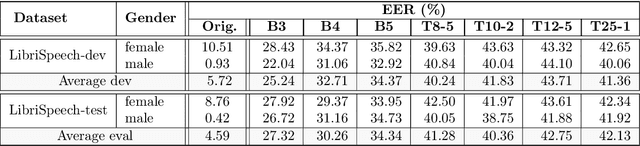
The First VoicePrivacy Attacker Challenge is a new kind of challenge organized as part of the VoicePrivacy initiative and supported by ICASSP 2025 as the SP Grand Challenge It focuses on developing attacker systems against voice anonymization, which will be evaluated against a set of anonymization systems submitted to the VoicePrivacy 2024 Challenge. Training, development, and evaluation datasets are provided along with a baseline attacker system. Participants shall develop their attacker systems in the form of automatic speaker verification systems and submit their scores on the development and evaluation data to the organizers. To do so, they can use any additional training data and models, provided that they are openly available and declared before the specified deadline. The metric for evaluation is equal error rate (EER). Results will be presented at the ICASSP 2025 special session to which 5 selected top-ranked participants will be invited to submit and present their challenge systems.
The VoicePrivacy 2022 Challenge: Progress and Perspectives in Voice Anonymisation
Jul 16, 2024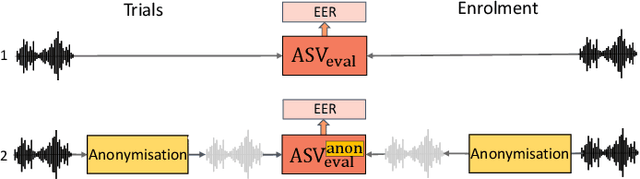
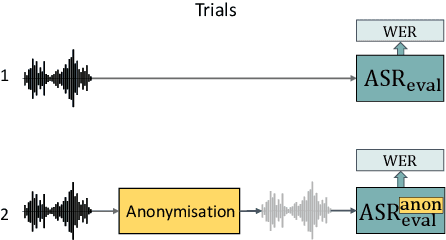
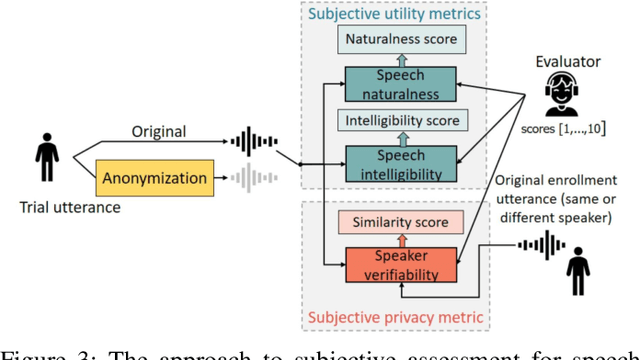
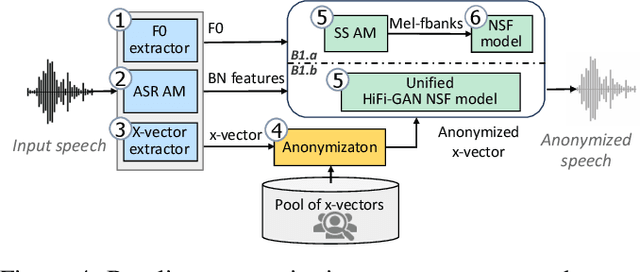
The VoicePrivacy Challenge promotes the development of voice anonymisation solutions for speech technology. In this paper we present a systematic overview and analysis of the second edition held in 2022. We describe the voice anonymisation task and datasets used for system development and evaluation, present the different attack models used for evaluation, and the associated objective and subjective metrics. We describe three anonymisation baselines, provide a summary description of the anonymisation systems developed by challenge participants, and report objective and subjective evaluation results for all. In addition, we describe post-evaluation analyses and a summary of related work reported in the open literature. Results show that solutions based on voice conversion better preserve utility, that an alternative which combines automatic speech recognition with synthesis achieves greater privacy, and that a privacy-utility trade-off remains inherent to current anonymisation solutions. Finally, we present our ideas and priorities for future VoicePrivacy Challenge editions.
The VoicePrivacy 2024 Challenge Evaluation Plan
Apr 03, 2024
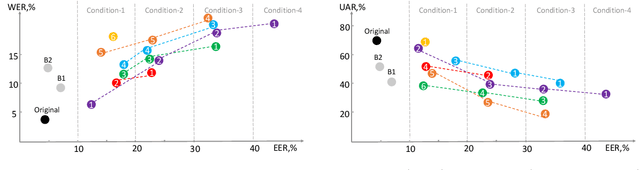
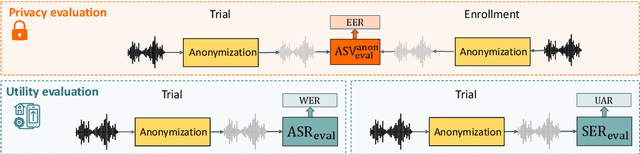
The task of the challenge is to develop a voice anonymization system for speech data which conceals the speaker's voice identity while protecting linguistic content and emotional states. The organizers provide development and evaluation datasets and evaluation scripts, as well as baseline anonymization systems and a list of training resources formed on the basis of the participants' requests. Participants apply their developed anonymization systems, run evaluation scripts and submit evaluation results and anonymized speech data to the organizers. Results will be presented at a workshop held in conjunction with Interspeech 2024 to which all participants are invited to present their challenge systems and to submit additional workshop papers.
Improving Speaker Assignment in Speaker-Attributed ASR for Real Meeting Applications
Mar 11, 2024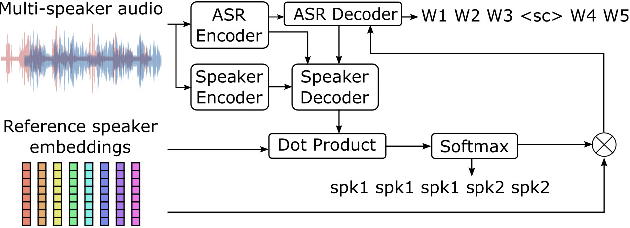
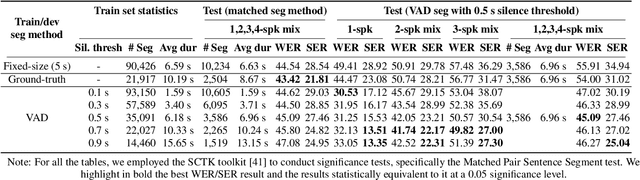
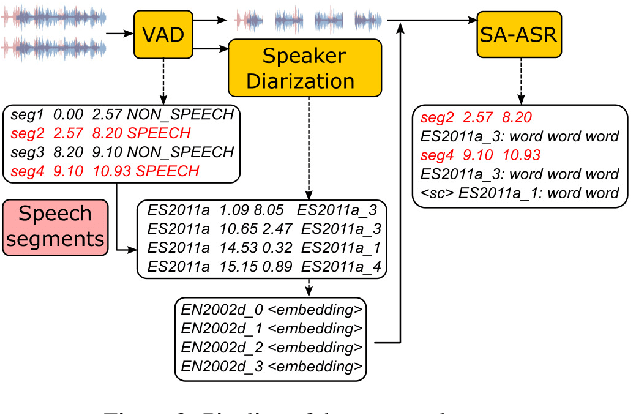
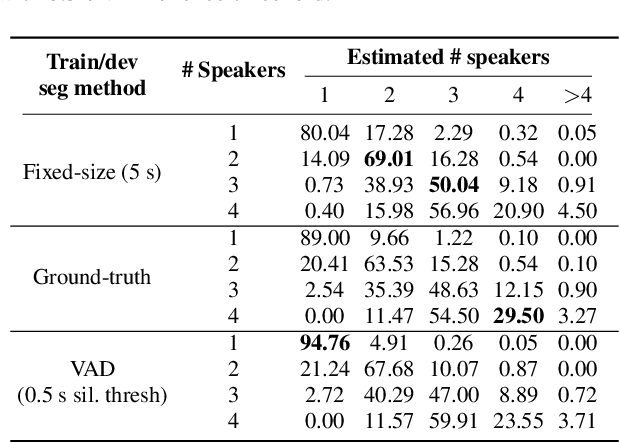
Past studies on end-to-end meeting transcription have focused on model architecture and have mostly been evaluated on simulated meeting data. We present a novel study aiming to optimize the use of a Speaker-Attributed ASR (SA-ASR) system in real-life scenarios, such as the AMI meeting corpus, for improved speaker assignment of speech segments. First, we propose a pipeline tailored to real-life applications involving Voice Activity Detection (VAD), Speaker Diarization (SD), and SA-ASR. Second, we advocate using VAD output segments to fine-tune the SA-ASR model, considering that it is also applied to VAD segments during test, and show that this results in a relative reduction of Speaker Error Rate (SER) up to 28%. Finally, we explore strategies to enhance the extraction of the speaker embedding templates used as inputs by the SA-ASR system. We show that extracting them from SD output rather than annotated speaker segments results in a relative SER reduction up to 20%.
End-to-end Joint Rich and Normalized ASR with a limited amount of rich training data
Nov 29, 2023Joint rich and normalized automatic speech recognition (ASR), that produces transcriptions both with and without punctuation and capitalization, remains a challenge. End-to-end (E2E) ASR models offer both convenience and the ability to perform such joint transcription of speech. Training such models requires paired speech and rich text data, which is not widely available. In this paper, we compare two different approaches to train a stateless Transducer-based E2E joint rich and normalized ASR system, ready for streaming applications, with a limited amount of rich labeled data. The first approach uses a language model to generate pseudo-rich transcriptions of normalized training data. The second approach uses a single decoder conditioned on the type of the output. The first approach leads to E2E rich ASR which perform better on out-of-domain data, with up to 9% relative reduction in errors. The second approach demonstrates the feasibility of an E2E joint rich and normalized ASR system using as low as 5% rich training data with moderate (2.42% absolute) increase in errors.