 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Third VoicePrivacy Challenge: Preserving Emotional Expressiveness and Linguistic Content in Voice Anonymization
Jan 17, 2026We present results and analyses from the third VoicePrivacy Challenge held in 2024, which focuses on advancing voice anonymization technologies. The task was to develop a voice anonymization system for speech data that conceals a speaker's voice identity while preserving linguistic content and emotional state. We provide a systematic overview of the challenge framework, including detailed descriptions of the anonymization task and datasets used for both system development and evaluation. We outline the attack model and objective evaluation metrics for assessing privacy protection (concealing speaker voice identity) and utility (content and emotional state preservation). We describe six baseline anonymization systems and summarize the innovative approaches developed by challenge participants. Finally, we provide key insights and observations to guide the design of future VoicePrivacy challenges and identify promising directions for voice anonymization research.
Use Cases for Voice Anonymization
Aug 08, 2025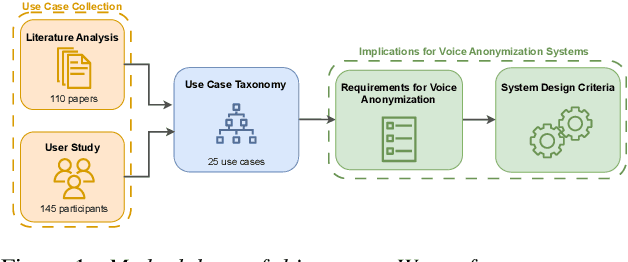



The performance of a voice anonymization system is typically measured according to its ability to hide the speaker's identity and keep the data's utility for downstream tasks. This means that the requirements the anonymization should fulfill depend on the context in which it is used and may differ greatly between use cases. However, these use cases are rarely specified in research papers. In this paper, we study the implications of use case-specific requirements on the design of voice anonymization methods. We perform an extensive literature analysis and user study to collect possible use cases and to understand the expectations of the general public towards such tools. Based on these studies, we propose the first taxonomy of use cases for voice anonymization, and derive a set of requirements and design criteria for method development and evaluation. Using this scheme, we propose to focus more on use case-oriented research and development of voice anonymization systems.
The Risks and Detection of Overestimated Privacy Protection in Voice Anonymisation
Jul 30, 2025Voice anonymisation aims to conceal the voice identity of speakers in speech recordings. Privacy protection is usually estimated from the difficulty of using a speaker verification system to re-identify the speaker post-anonymisation. Performance assessments are therefore dependent on the verification model as well as the anonymisation system. There is hence potential for privacy protection to be overestimated when the verification system is poorly trained, perhaps with mismatched data. In this paper, we demonstrate the insidious risk of overestimating anonymisation performance and show examples of exaggerated performance reported in the literature. For the worst case we identified, performance is overestimated by 74% relative. We then introduce a means to detect when performance assessment might be untrustworthy and show that it can identify all overestimation scenarios presented in the paper. Our solution is openly available as a fork of the 2024 VoicePrivacy Challenge evaluation toolkit.
First Steps Towards Voice Anonymization for Code-Switching Speech
Jul 02, 2025The goal of voice anonymization is to modify an audio such that the true identity of its speaker is hidden. Research on this task is typically limited to the same English read speech datasets, thus the efficacy of current methods for other types of speech data remains unknown. In this paper, we present the first investigation of voice anonymization for the multilingual phenomenon of code-switching speech. We prepare two corpora for this task and propose adaptations to a multilingual anonymization model to make it applicable for code-switching speech. By testing the anonymization performance of this and two language-independent methods on the datasets, we find that only the multilingual system performs well in terms of privacy and utility preservation. Furthermore, we observe challenges in performing utility evaluations on this data because of its spontaneous character and the limited code-switching support by the multilingual speech recognition model.
Probing the Feasibility of Multilingual Speaker Anonymization
Jul 03, 2024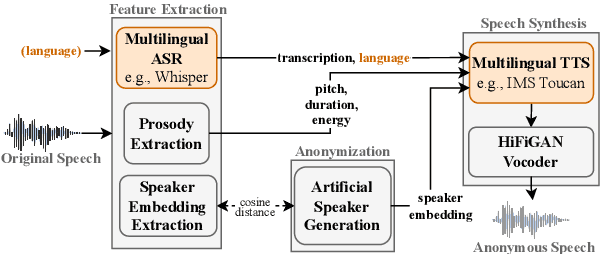
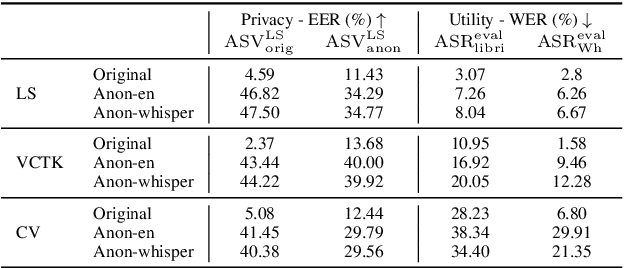
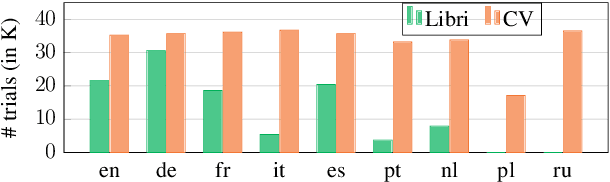
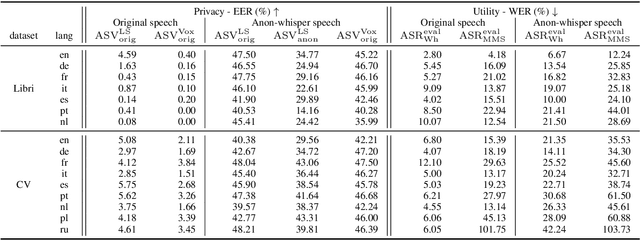
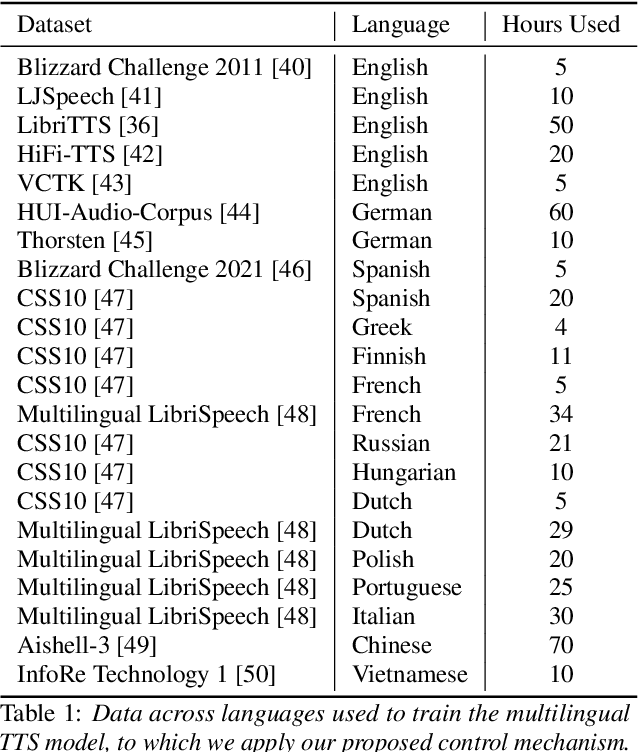
In speaker anonymization, speech recordings are modified in a way that the identity of the speaker remains hidden. While this technology could help to protect the privacy of individuals around the globe, current research restricts this by focusing almost exclusively on English data. In this study, we extend a state-of-the-art anonymization system to nine languages by transforming language-dependent components to their multilingual counterparts. Experiments testing the robustness of the anonymized speech against privacy attacks and speech deterioration show an overall success of this system for all languages. The results suggest that speaker embeddings trained on English data can be applied across languages, and that the anonymization performance for a language is mainly affected by the quality of the speech synthesis component used for it.
Meta Learning Text-to-Speech Synthesis in over 7000 Languages
Jun 10, 2024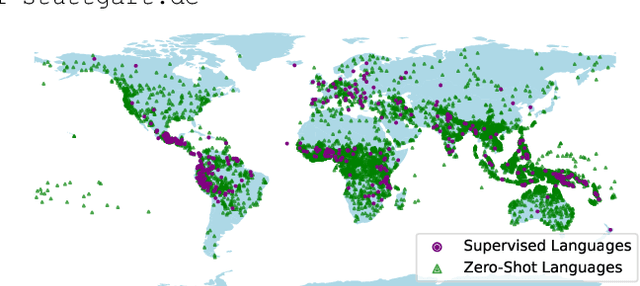
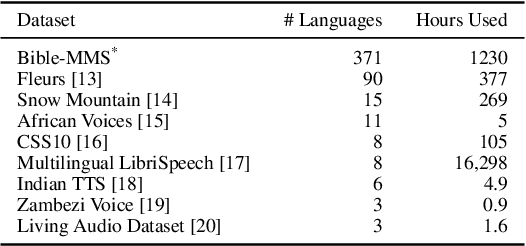
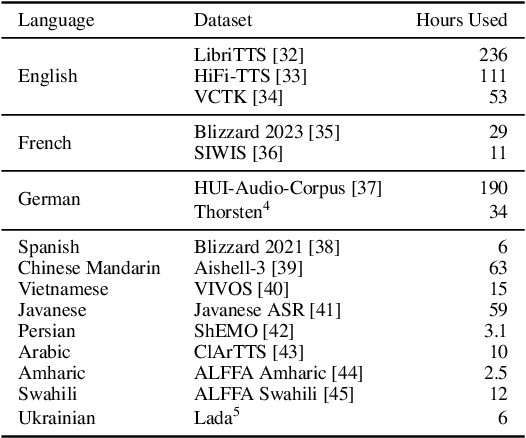
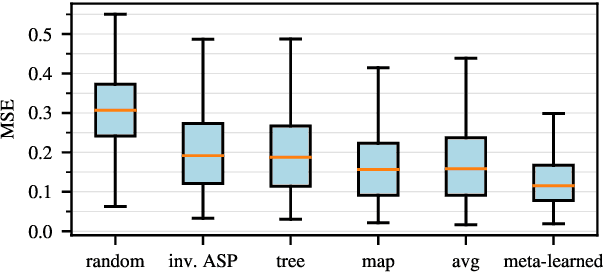
In this work, we take on the challenging task of building a single text-to-speech synthesis system that is capable of generating speech in over 7000 languages, many of which lack sufficient data for traditional TTS development. By leveraging a novel integration of massively multilingual pretraining and meta learning to approximate language representations, our approach enables zero-shot speech synthesis in languages without any available data. We validate our system's performance through objective measures and human evaluation across a diverse linguistic landscape. By releasing our code and models publicly, we aim to empower communities with limited linguistic resources and foster further innovation in the field of speech technology.
The VoicePrivacy 2024 Challenge Evaluation Plan
Apr 03, 2024
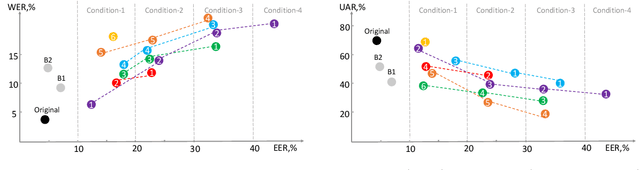
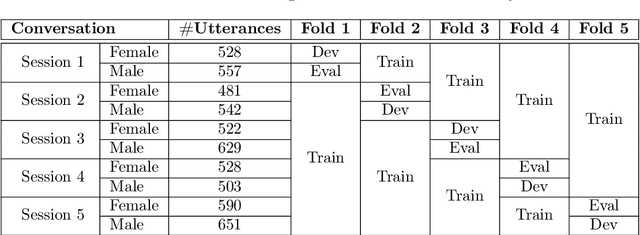
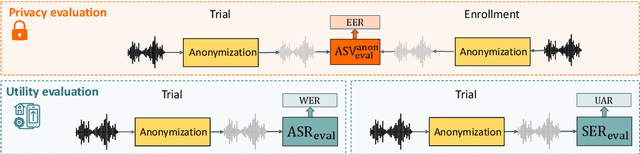
The task of the challenge is to develop a voice anonymization system for speech data which conceals the speaker's voice identity while protecting linguistic content and emotional states. The organizers provide development and evaluation datasets and evaluation scripts, as well as baseline anonymization systems and a list of training resources formed on the basis of the participants' requests. Participants apply their developed anonymization systems, run evaluation scripts and submit evaluation results and anonymized speech data to the organizers. Results will be presented at a workshop held in conjunction with Interspeech 2024 to which all participants are invited to present their challenge systems and to submit additional workshop papers.
Controllable Generation of Artificial Speaker Embeddings through Discovery of Principal Directions
Oct 26, 2023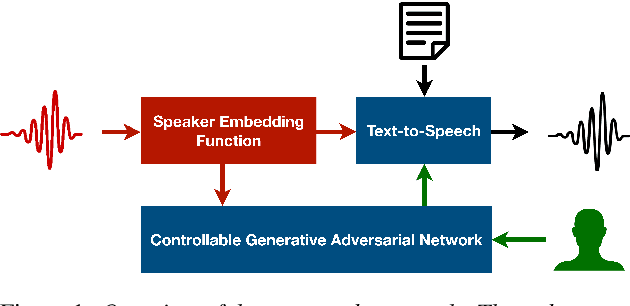
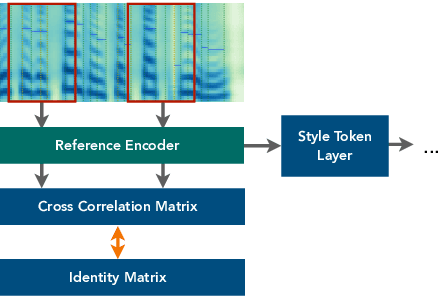

Customizing voice and speaking style in a speech synthesis system with intuitive and fine-grained controls is challenging, given that little data with appropriate labels is available. Furthermore, editing an existing human's voice also comes with ethical concerns. In this paper, we propose a method to generate artificial speaker embeddings that cannot be linked to a real human while offering intuitive and fine-grained control over the voice and speaking style of the embeddings, without requiring any labels for speaker or style. The artificial and controllable embeddings can be fed to a speech synthesis system, conditioned on embeddings of real humans during training, without sacrificing privacy during inference.
The IMS Toucan System for the Blizzard Challenge 2023
Oct 26, 2023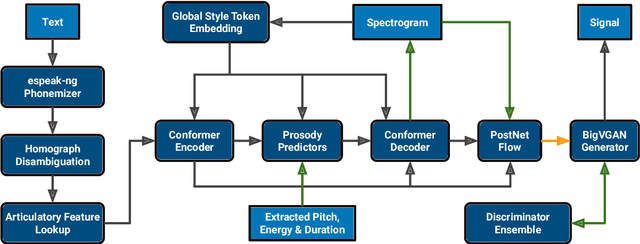
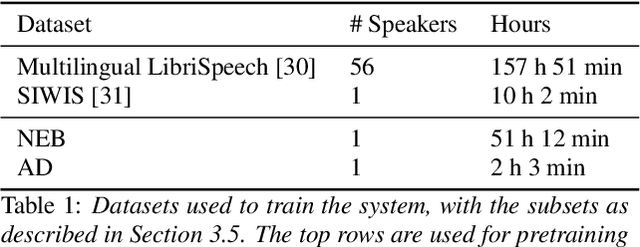
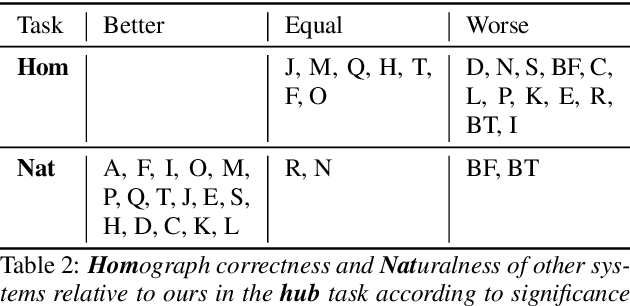
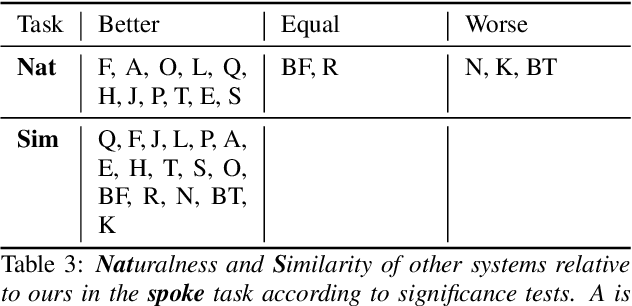
For our contribution to the Blizzard Challenge 2023, we improved on the system we submitted to the Blizzard Challenge 2021. Our approach entails a rule-based text-to-phoneme processing system that includes rule-based disambiguation of homographs in the French language. It then transforms the phonemes to spectrograms as intermediate representations using a fast and efficient non-autoregressive synthesis architecture based on Conformer and Glow. A GAN based neural vocoder that combines recent state-of-the-art approaches converts the spectrogram to the final wave. We carefully designed the data processing, training, and inference procedures for the challenge data. Our system identifier is G. Open source code and demo are available.
VoicePAT: An Efficient Open-source Evaluation Toolkit for Voice Privacy Research
Sep 14, 2023



Speaker anonymization is the task of modifying a speech recording such that the original speaker cannot be identified anymore. Since the first Voice Privacy Challenge in 2020, along with the release of a framework, the popularity of this research topic is continually increasing. However, the comparison and combination of different anonymization approaches remains challenging due to the complexity of evaluation and the absence of user-friendly research frameworks. We therefore propose an efficient speaker anonymization and evaluation framework based on a modular and easily extendable structure, almost fully in Python. The framework facilitates the orchestration of several anonymization approaches in parallel and allows for interfacing between different techniques. Furthermore, we propose modifications to common evaluation methods which make the evaluation more powerful and reduces their computation time by 65 to 95\%, depending on the metric. Our code is fully open source.