 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta Learning Text-to-Speech Synthesis in over 7000 Languages
Jun 10, 2024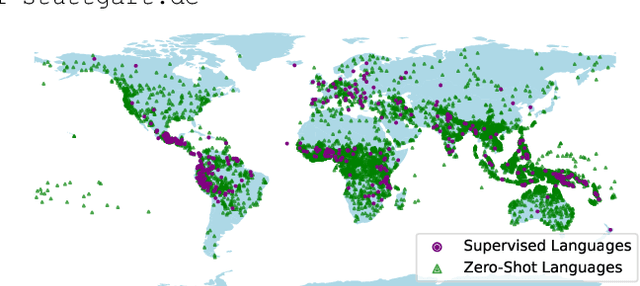
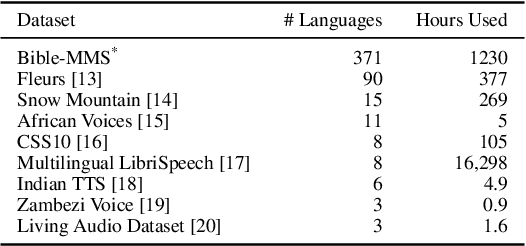
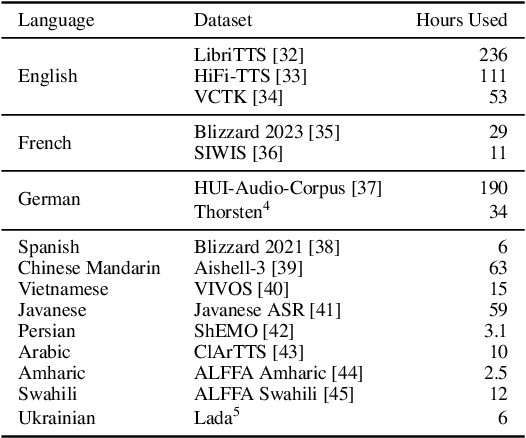
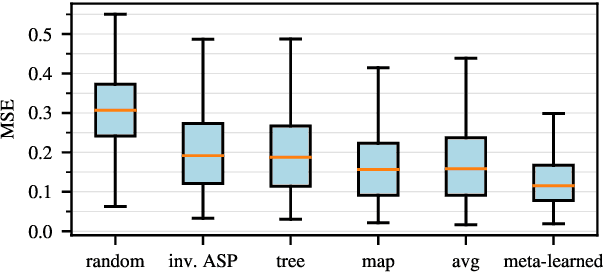
In this work, we take on the challenging task of building a single text-to-speech synthesis system that is capable of generating speech in over 7000 languages, many of which lack sufficient data for traditional TTS development. By leveraging a novel integration of massively multilingual pretraining and meta learning to approximate language representations, our approach enables zero-shot speech synthesis in languages without any available data. We validate our system's performance through objective measures and human evaluation across a diverse linguistic landscape. By releasing our code and models publicly, we aim to empower communities with limited linguistic resources and foster further innovation in the field of speech technology.
Strategies in Transfer Learning for Low-Resource Speech Synthesis: Phone Mapping, Features Input, and Source Language Selection
Jun 21, 2023



We compare using a PHOIBLE-based phone mapping method and using phonological features input in transfer learning for TTS in low-resource languages. We use diverse source languages (English, Finnish, Hindi, Japanese, and Russian) and target languages (Bulgarian, Georgian, Kazakh, Swahili, Urdu, and Uzbek) to test the language-independence of the methods and enhance the findings' applicability. We use Character Error Rates from automatic speech recognition and predicted Mean Opinion Scores for evaluation. Results show that both phone mapping and features input improve the output quality and the latter performs better, but these effects also depend on the specific language combination. We also compare the recently-proposed Angular Similarity of Phone Frequencies (ASPF) with a family tree-based distance measure as a criterion to select source languages in transfer learning. ASPF proves effective if label-based phone input is used, while the language distance does not have expected effects.
The Effects of Input Type and Pronunciation Dictionary Usage in Transfer Learning for Low-Resource Text-to-Speech
Jun 01, 2023


We compare phone labels and articulatory features as input for cross-lingual transfer learning in text-to-speech (TTS) for low-resource languages (LRLs). Experiments with FastSpeech 2 and the LRL West Frisian show that using articulatory features outperformed using phone labels in both intelligibility and naturalness. For LRLs without pronunciation dictionaries, we propose two novel approaches: a) using a massively multilingual model to convert grapheme-to-phone (G2P) in both training and synthesizing, and b) using a universal phone recognizer to create a makeshift dictionary. Results show that the G2P approach performs largely on par with using a ground-truth dictionary and the phone recognition approach, while performing generally worse, remains a viable option for LRLs less suitable for the G2P approach. Within each approach, using articulatory features as input outperforms using phone labels.
Resource-Efficient Fine-Tuning Strategies for Automatic MOS Prediction in Text-to-Speech for Low-Resource Languages
May 30, 2023



We train a MOS prediction model based on wav2vec 2.0 using the open-access data sets BVCC and SOMOS. Our test with neural TTS data in the low-resource language (LRL) West Frisian shows that pre-training on BVCC before fine-tuning on SOMOS leads to the best accuracy for both fine-tuned and zero-shot prediction. Further fine-tuning experiments show that using more than 30 percent of the total data does not lead to significant improvements. In addition, fine-tuning with data from a single listener shows promising system-level accuracy, supporting the viability of one-participant pilot tests. These findings can all assist the resource-conscious development of TTS for LRLs by progressing towards better zero-shot MOS prediction and informing the design of listening tests, especially in early-stage evaluation.