 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGood practices for evaluation of synthesized speech
Mar 05, 2025This document is provided as a guideline for reviewers of papers about speech synthesis. We outline some best practices and common pitfalls for papers about speech synthesis, with a particular focus on evaluation. We also recommend that reviewers check the guidelines for authors written in the paper kit and consider those as reviewing criteria as well. This is intended to be a living document, and it will be updated as we receive comments and feedback from readers. We note that this document is meant to provide guidance only, and that reviewers should ultimately use their own discretion when evaluating papers.
Strategies in Transfer Learning for Low-Resource Speech Synthesis: Phone Mapping, Features Input, and Source Language Selection
Jun 21, 2023



We compare using a PHOIBLE-based phone mapping method and using phonological features input in transfer learning for TTS in low-resource languages. We use diverse source languages (English, Finnish, Hindi, Japanese, and Russian) and target languages (Bulgarian, Georgian, Kazakh, Swahili, Urdu, and Uzbek) to test the language-independence of the methods and enhance the findings' applicability. We use Character Error Rates from automatic speech recognition and predicted Mean Opinion Scores for evaluation. Results show that both phone mapping and features input improve the output quality and the latter performs better, but these effects also depend on the specific language combination. We also compare the recently-proposed Angular Similarity of Phone Frequencies (ASPF) with a family tree-based distance measure as a criterion to select source languages in transfer learning. ASPF proves effective if label-based phone input is used, while the language distance does not have expected effects.
The Effects of Input Type and Pronunciation Dictionary Usage in Transfer Learning for Low-Resource Text-to-Speech
Jun 01, 2023


We compare phone labels and articulatory features as input for cross-lingual transfer learning in text-to-speech (TTS) for low-resource languages (LRLs). Experiments with FastSpeech 2 and the LRL West Frisian show that using articulatory features outperformed using phone labels in both intelligibility and naturalness. For LRLs without pronunciation dictionaries, we propose two novel approaches: a) using a massively multilingual model to convert grapheme-to-phone (G2P) in both training and synthesizing, and b) using a universal phone recognizer to create a makeshift dictionary. Results show that the G2P approach performs largely on par with using a ground-truth dictionary and the phone recognition approach, while performing generally worse, remains a viable option for LRLs less suitable for the G2P approach. Within each approach, using articulatory features as input outperforms using phone labels.
Resource-Efficient Fine-Tuning Strategies for Automatic MOS Prediction in Text-to-Speech for Low-Resource Languages
May 30, 2023



We train a MOS prediction model based on wav2vec 2.0 using the open-access data sets BVCC and SOMOS. Our test with neural TTS data in the low-resource language (LRL) West Frisian shows that pre-training on BVCC before fine-tuning on SOMOS leads to the best accuracy for both fine-tuned and zero-shot prediction. Further fine-tuning experiments show that using more than 30 percent of the total data does not lead to significant improvements. In addition, fine-tuning with data from a single listener shows promising system-level accuracy, supporting the viability of one-participant pilot tests. These findings can all assist the resource-conscious development of TTS for LRLs by progressing towards better zero-shot MOS prediction and informing the design of listening tests, especially in early-stage evaluation.
Data-augmented cross-lingual synthesis in a teacher-student framework
Mar 31, 2022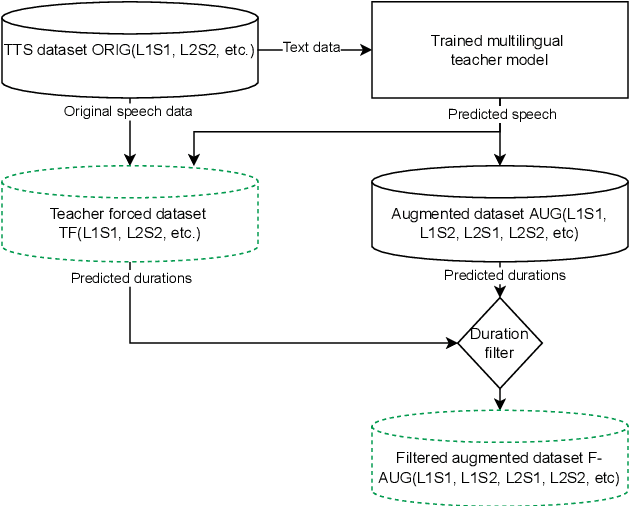
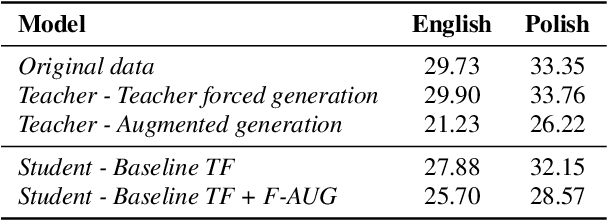
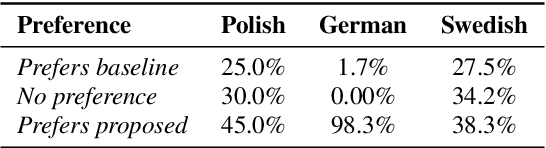
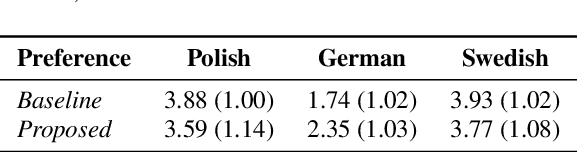
Cross-lingual synthesis can be defined as the task of letting a speaker generate fluent synthetic speech in another language. This is a challenging task, and resulting speech can suffer from reduced naturalness, accented speech, and/or loss of essential voice characteristics. Previous research shows that many models appear to have insufficient generalization capabilities to perform well on every of these cross-lingual aspects. To overcome these generalization problems, we propose to apply the teacher-student paradigm to cross-lingual synthesis. While a teacher model is commonly used to produce teacher forced data, we propose to also use it to produce augmented data of unseen speaker-language pairs, where the aim is to retain essential speaker characteristics. Both sets of data are then used for student model training, which is trained to retain the naturalness and prosodic variation present in the teacher forced data, while learning the speaker identity from the augmented data. Some modifications to the student model are proposed to make the separation of teacher forced and augmented data more straightforward. Results show that the proposed approach improves the retention of speaker characteristics in the speech, while managing to retain high levels of naturalness and prosodic variation.
Efficient neural speech synthesis for low-resource languages through multilingual modeling
Aug 20, 2020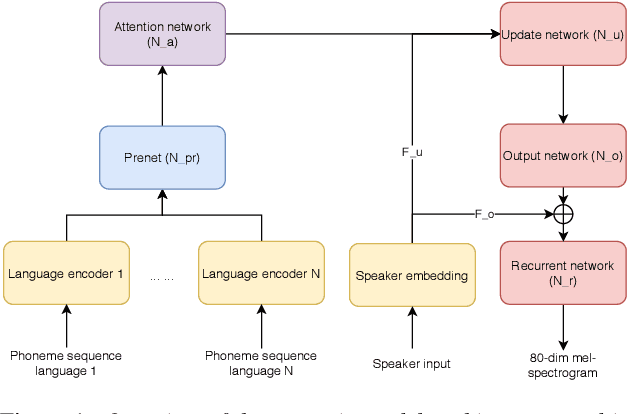
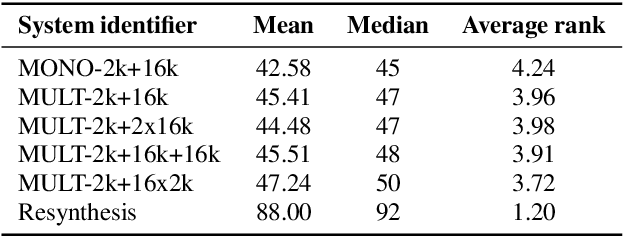

Recent advances in neural TTS have led to models that can produce high-quality synthetic speech. However, these models typically require large amounts of training data, which can make it costly to produce a new voice with the desired quality. Although multi-speaker modeling can reduce the data requirements necessary for a new voice, this approach is usually not viable for many low-resource languages for which abundant multi-speaker data is not available. In this paper, we therefore investigated to what extent multilingual multi-speaker modeling can be an alternative to monolingual multi-speaker modeling, and explored how data from foreign languages may best be combined with low-resource language data. We found that multilingual modeling can increase the naturalness of low-resource language speech, showed that multilingual models can produce speech with a naturalness comparable to monolingual multi-speaker models, and saw that the target language naturalness was affected by the strategy used to add foreign language data.