 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodecMOS-Accent: A MOS Benchmark of Resynthesized and TTS Speech from Neural Codecs Across English Accents
Mar 15, 2026We present the CodecMOS-Accent dataset, a mean opinion score (MOS) benchmark designed to evaluate neural audio codec (NAC) models and the large language model (LLM)-based text-to-speech (TTS) models trained upon them, especially across non-standard speech like accented speech. The dataset comprises 4,000 codec resynthesis and TTS samples from 24 systems, featuring 32 speakers spanning ten accents. A large-scale subjective test was conducted to collect 19,600 annotations from 25 listeners across three dimensions: naturalness, speaker similarity, and accent similarity. This dataset does not only represent an up-to-date study of recent speech synthesis system performance but reveals insights including a tight relationship between speaker and accent similarity, the predictive power of objective metrics, and a perceptual bias when listeners share the same accent with the speaker. This dataset is expected to foster research on more human-centric evaluation for NAC and accented TTS.
MOS-Bias: From Hidden Gender Bias to Gender-Aware Speech Quality Assessment
Mar 11, 2026The Mean Opinion Score (MOS) serves as the standard metric for speech quality assessment, yet biases in human annotations remain underexplored. We conduct the first systematic analysis of gender bias in MOS, revealing that male listeners consistently assign higher scores than female listeners--a gap that is most pronounced in low-quality speech and gradually diminishes as quality improves. This quality-dependent structure proves difficult to eliminate through simple calibration. We further demonstrate that automated MOS models trained on aggregated labels exhibit predictions skewed toward male standards of perception. To address this, we propose a gender-aware model that learns gender-specific scoring patterns through abstracting binary group embeddings, thereby improving overall and gender-specific prediction accuracy. This study establishes that gender bias in MOS constitutes a systematic, learnable pattern demanding attention in equitable speech evaluation.
Layer-wise Analysis for Quality of Multilingual Synthesized Speech
Sep 05, 2025While supervised quality predictors for synthesized speech have demonstrated strong correlations with human ratings, their requirement for in-domain labeled training data hinders their generalization ability to new domains. Unsupervised approaches based on pretrained self-supervised learning (SSL) based models and automatic speech recognition (ASR) models are a promising alternative; however, little is known about how these models encode information about speech quality. Towards the goal of better understanding how different aspects of speech quality are encoded in a multilingual setting, we present a layer-wise analysis of multilingual pretrained speech models based on reference modeling. We find that features extracted from early SSL layers show correlations with human ratings of synthesized speech, and later layers of ASR models can predict quality of non-neural systems as well as intelligibility. We also demonstrate the importance of using well-matched reference data.
SHEET: A Multi-purpose Open-source Speech Human Evaluation Estimation Toolkit
May 21, 2025We introduce SHEET, a multi-purpose open-source toolkit designed to accelerate subjective speech quality assessment (SSQA) research. SHEET stands for the Speech Human Evaluation Estimation Toolkit, which focuses on data-driven deep neural network-based models trained to predict human-labeled quality scores of speech samples. SHEET provides comprehensive training and evaluation scripts, multi-dataset and multi-model support, as well as pre-trained models accessible via Torch Hub and HuggingFace Spaces. To demonstrate its capabilities, we re-evaluated SSL-MOS, a speech self-supervised learning (SSL)-based SSQA model widely used in recent scientific papers, on an extensive list of speech SSL models. Experiments were conducted on two representative SSQA datasets named BVCC and NISQA, and we identified the optimal speech SSL model, whose performance surpassed the original SSL-MOS implementation and was comparable to state-of-the-art methods.
Good practices for evaluation of synthesized speech
Mar 05, 2025This document is provided as a guideline for reviewers of papers about speech synthesis. We outline some best practices and common pitfalls for papers about speech synthesis, with a particular focus on evaluation. We also recommend that reviewers check the guidelines for authors written in the paper kit and consider those as reviewing criteria as well. This is intended to be a living document, and it will be updated as we receive comments and feedback from readers. We note that this document is meant to provide guidance only, and that reviewers should ultimately use their own discretion when evaluating papers.
Towards An Integrated Approach for Expressive Piano Performance Synthesis from Music Scores
Jan 17, 2025
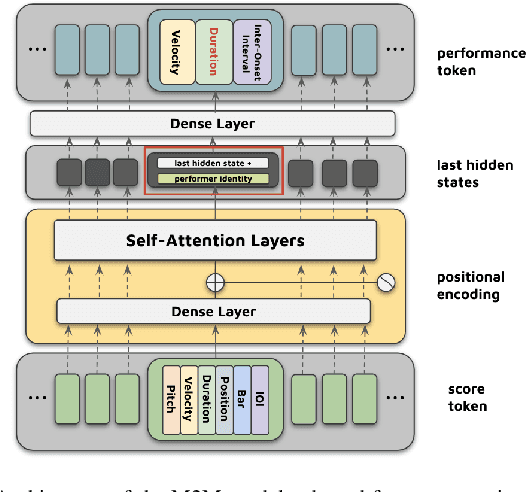


This paper presents an integrated system that transforms symbolic music scores into expressive piano performance audio. By combining a Transformer-based Expressive Performance Rendering (EPR) model with a fine-tuned neural MIDI synthesiser, our approach directly generates expressive audio performances from score inputs. To the best of our knowledge, this is the first system to offer a streamlined method for converting score MIDI files lacking expression control into rich, expressive piano performances. We conducted experiments using subsets of the ATEPP dataset, evaluating the system with both objective metrics and subjective listening tests. Our system not only accurately reconstructs human-like expressiveness, but also captures the acoustic ambience of environments such as concert halls and recording studios. Additionally, the proposed system demonstrates its ability to achieve musical expressiveness while ensuring good audio quality in its outputs.
MOS-Bench: Benchmarking Generalization Abilities of Subjective Speech Quality Assessment Models
Nov 06, 2024



Subjective speech quality assessment (SSQA) is critical for evaluating speech samples as perceived by human listeners. While model-based SSQA has enjoyed great success thanks to the development of deep neural networks (DNNs), generalization remains a key challenge, especially for unseen, out-of-domain data. To benchmark the generalization abilities of SSQA models, we present MOS-Bench, a diverse collection of datasets. In addition, we also introduce SHEET, an open-source toolkit containing complete recipes to conduct SSQA experiments. We provided benchmark results for MOS-Bench, and we also explored multi-dataset training to enhance generalization. Additionally, we proposed a new performance metric, best score difference/ratio, and used latent space visualizations to explain model behavior, offering valuable insights for future research.
The VoiceMOS Challenge 2024: Beyond Speech Quality Prediction
Sep 11, 2024



We present the third edition of the VoiceMOS Challenge, a scientific initiative designed to advance research into automatic prediction of human speech ratings. There were three tracks. The first track was on predicting the quality of ``zoomed-in'' high-quality samples from speech synthesis systems. The second track was to predict ratings of samples from singing voice synthesis and voice conversion with a large variety of systems, listeners, and languages. The third track was semi-supervised quality prediction for noisy, clean, and enhanced speech, where a very small amount of labeled training data was provided. Among the eight teams from both academia and industry, we found that many were able to outperform the baseline systems. Successful techniques included retrieval-based methods and the use of non-self-supervised representations like spectrograms and pitch histograms. These results showed that the challenge has advanced the field of subjective speech rating prediction.
Spoofing-Aware Speaker Verification Robust Against Domain and Channel Mismatches
Sep 10, 2024In real-world applications, it is challenging to build a speaker verification system that is simultaneously robust against common threats, including spoofing attacks, channel mismatch, and domain mismatch. Traditional automatic speaker verification (ASV) systems often tackle these issues separately, leading to suboptimal performance when faced with simultaneous challenges. In this paper, we propose an integrated framework that incorporates pair-wise learning and spoofing attack simulation into the meta-learning paradigm to enhance robustness against these multifaceted threats. This novel approach employs an asymmetric dual-path model and a multi-task learning strategy to handle ASV, anti-spoofing, and spoofing-aware ASV tasks concurrently. A new testing dataset, CNComplex, is introduced to evaluate system performance under these combined threats. Experimental results demonstrate that our integrated model significantly improves performance over traditional ASV systems across various scenarios, showcasing its potential for real-world deployment. Additionally, the proposed framework's ability to generalize across different conditions highlights its robustness and reliability, making it a promising solution for practical ASV applications.
An Initial Investigation of Language Adaptation for TTS Systems under Low-resource Scenarios
Jun 13, 2024Self-supervised learning (SSL) representations from massively multilingual models offer a promising solution for low-resource language speech tasks. Despite advancements, language adaptation in TTS systems remains an open problem. This paper explores the language adaptation capability of ZMM-TTS, a recent SSL-based multilingual TTS system proposed in our previous work. We conducted experiments on 12 languages using limited data with various fine-tuning configurations. We demonstrate that the similarity in phonetics between the pre-training and target languages, as well as the language category, affects the target language's adaptation performance. Additionally, we find that the fine-tuning dataset size and number of speakers influence adaptability. Surprisingly, we also observed that using paired data for fine-tuning is not always optimal compared to audio-only data. Beyond speech intelligibility, our analysis covers speaker similarity, language identification, and predicted MOS.