 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Timbre Transfer Via Mutual Information Guided Inpainting
Jan 03, 2026We study timbre transfer as an inference-time editing problem for music audio. Starting from a strong pre-trained latent diffusion model, we introduce a lightweight procedure that requires no additional training: (i) a dimension-wise noise injection that targets latent channels most informative of instrument identity, and (ii) an early-step clamping mechanism that re-imposes the input's melodic and rhythmic structure during reverse diffusion. The method operates directly on audio latents and is compatible with text/audio conditioning (e.g., CLAP). We discuss design choices,analyze trade-offs between timbral change and structural preservation, and show that simple inference-time controls can meaningfully steer pre-trained models for style-transfer use cases.
Towards a Unified Representation Evaluation Framework Beyond Downstream Tasks
May 09, 2025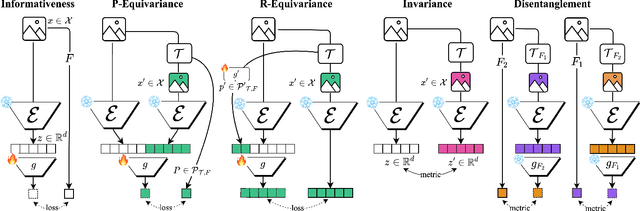


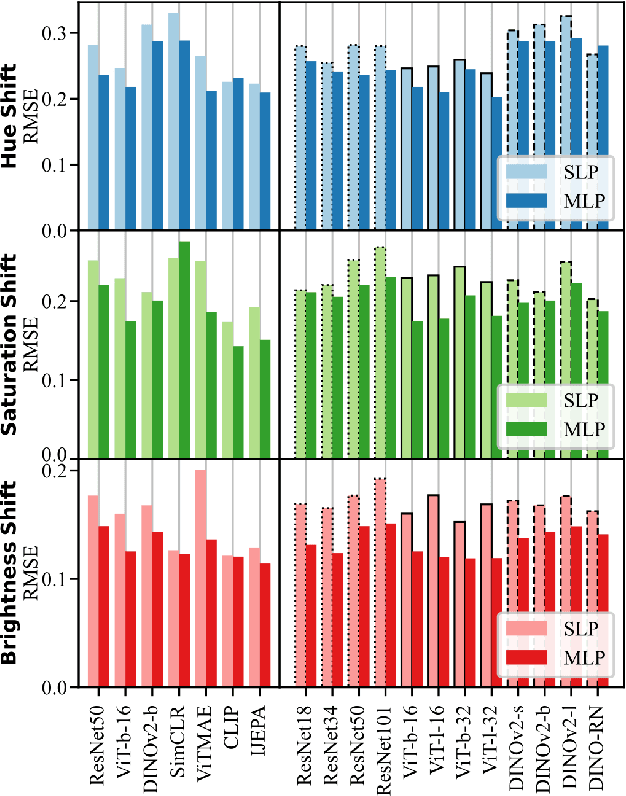
Downstream probing has been the dominant method for evaluating model representations, an important process given the increasing prominence of self-supervised learning and foundation models. However, downstream probing primarily assesses the availability of task-relevant information in the model's latent space, overlooking attributes such as equivariance, invariance, and disentanglement, which contribute to the interpretability, adaptability, and utility of representations in real-world applications. While some attempts have been made to measure these qualities in representations, no unified evaluation framework with modular, generalizable, and interpretable metrics exists. In this paper, we argue for the importance of representation evaluation beyond downstream probing. We introduce a standardized protocol to quantify informativeness, equivariance, invariance, and disentanglement of factors of variation in model representations. We use it to evaluate representations from a variety of models in the image and speech domains using different architectures and pretraining approaches on identified controllable factors of variation. We find that representations from models with similar downstream performance can behave substantially differently with regard to these attributes. This hints that the respective mechanisms underlying their downstream performance are functionally different, prompting new research directions to understand and improve representations.
Music2Latent2: Audio Compression with Summary Embeddings and Autoregressive Decoding
Jan 29, 2025Efficiently compressing high-dimensional audio signals into a compact and informative latent space is crucial for various tasks, including generative modeling and music information retrieval (MIR). Existing audio autoencoders, however, often struggle to achieve high compression ratios while preserving audio fidelity and facilitating efficient downstream applications. We introduce Music2Latent2, a novel audio autoencoder that addresses these limitations by leveraging consistency models and a novel approach to representation learning based on unordered latent embeddings, which we call summary embeddings. Unlike conventional methods that encode local audio features into ordered sequences, Music2Latent2 compresses audio signals into sets of summary embeddings, where each embedding can capture distinct global features of the input sample. This enables to achieve higher reconstruction quality at the same compression ratio. To handle arbitrary audio lengths, Music2Latent2 employs an autoregressive consistency model trained on two consecutive audio chunks with causal masking, ensuring coherent reconstruction across segment boundaries. Additionally, we propose a novel two-step decoding procedure that leverages the denoising capabilities of consistency models to further refine the generated audio at no additional cost. Our experiments demonstrate that Music2Latent2 outperforms existing continuous audio autoencoders regarding audio quality and performance on downstream tasks. Music2Latent2 paves the way for new possibilities in audio compression.
Towards An Integrated Approach for Expressive Piano Performance Synthesis from Music Scores
Jan 17, 2025
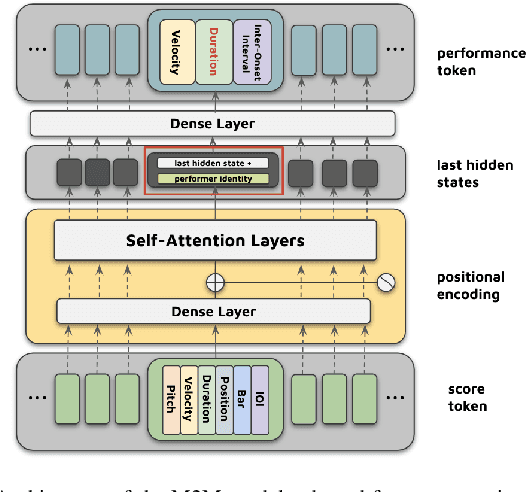


This paper presents an integrated system that transforms symbolic music scores into expressive piano performance audio. By combining a Transformer-based Expressive Performance Rendering (EPR) model with a fine-tuned neural MIDI synthesiser, our approach directly generates expressive audio performances from score inputs. To the best of our knowledge, this is the first system to offer a streamlined method for converting score MIDI files lacking expression control into rich, expressive piano performances. We conducted experiments using subsets of the ATEPP dataset, evaluating the system with both objective metrics and subjective listening tests. Our system not only accurately reconstructs human-like expressiveness, but also captures the acoustic ambience of environments such as concert halls and recording studios. Additionally, the proposed system demonstrates its ability to achieve musical expressiveness while ensuring good audio quality in its outputs.
Continuous Autoregressive Models with Noise Augmentation Avoid Error Accumulation
Nov 27, 2024Autoregressive models are typically applied to sequences of discrete tokens, but recent research indicates that generating sequences of continuous embeddings in an autoregressive manner is also feasible. However, such Continuous Autoregressive Models (CAMs) can suffer from a decline in generation quality over extended sequences due to error accumulation during inference. We introduce a novel method to address this issue by injecting random noise into the input embeddings during training. This procedure makes the model robust against varying error levels at inference. We further reduce error accumulation through an inference procedure that introduces low-level noise. Experiments on musical audio generation show that CAM substantially outperforms existing autoregressive and non-autoregressive approaches while preserving audio quality over extended sequences. This work paves the way for generating continuous embeddings in a purely autoregressive setting, opening new possibilities for real-time and interactive generative applications.
Low-Data Classification of Historical Music Manuscripts: A Few-Shot Learning Approach
Nov 25, 2024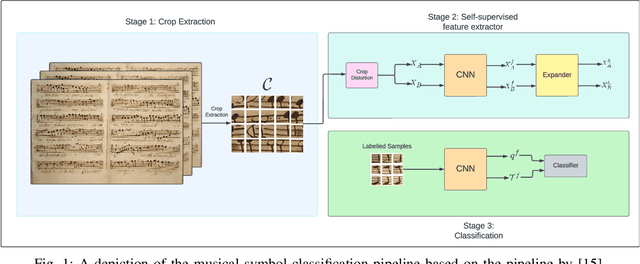

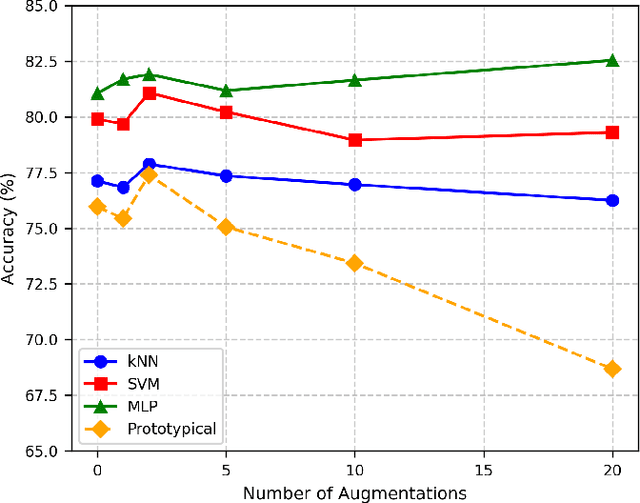
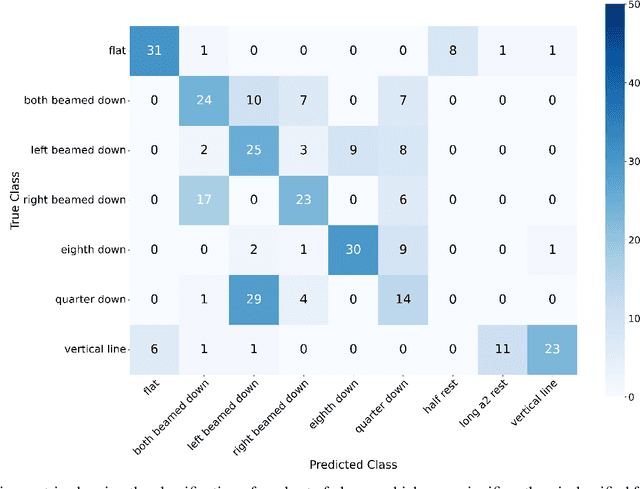
In this paper, we explore the intersection of technology and cultural preservation by developing a self-supervised learning framework for the classification of musical symbols in historical manuscripts. Optical Music Recognition (OMR) plays a vital role in digitising and preserving musical heritage, but historical documents often lack the labelled data required by traditional methods. We overcome this challenge by training a neural-based feature extractor on unlabelled data, enabling effective classification with minimal samples. Key contributions include optimising crop preprocessing for a self-supervised Convolutional Neural Network and evaluating classification methods, including SVM, multilayer perceptrons, and prototypical networks. Our experiments yield an accuracy of 87.66\%, showcasing the potential of AI-driven methods to ensure the survival of historical music for future generations through advanced digital archiving techniques.
Synthesising Handwritten Music with GANs: A Comprehensive Evaluation of CycleWGAN, ProGAN, and DCGAN
Nov 25, 2024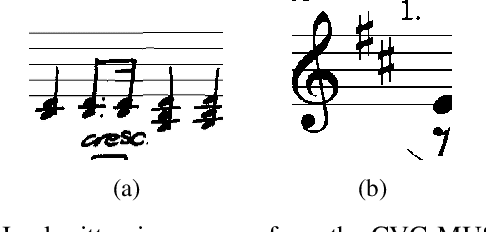
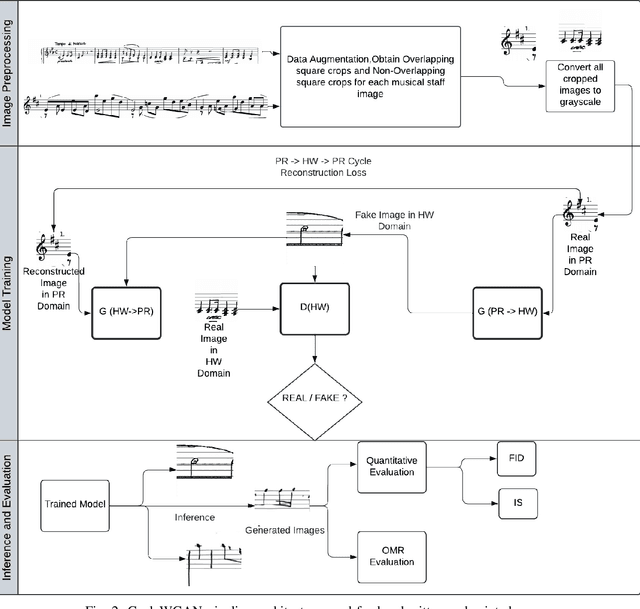
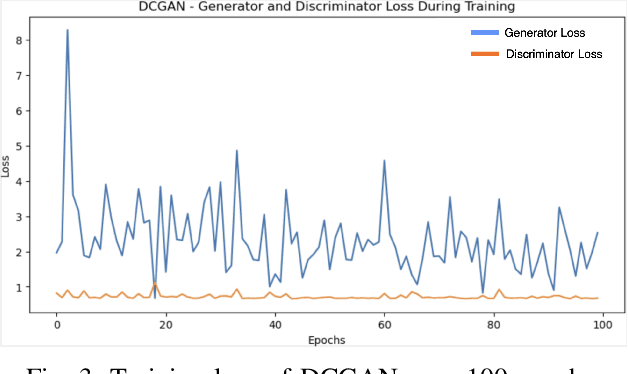
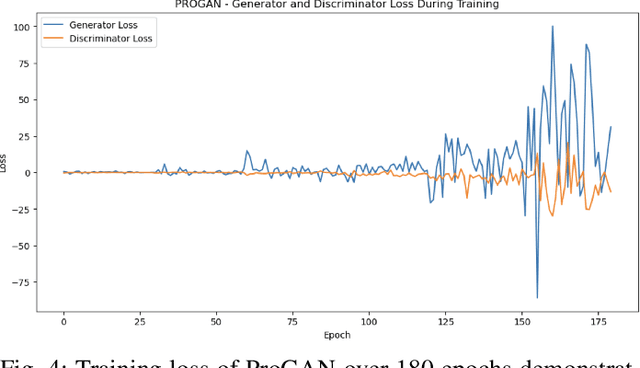
The generation of handwritten music sheets is a crucial step toward enhancing Optical Music Recognition (OMR) systems, which rely on large and diverse datasets for optimal performance. However, handwritten music sheets, often found in archives, present challenges for digitisation due to their fragility, varied handwriting styles, and image quality. This paper addresses the data scarcity problem by applying Generative Adversarial Networks (GANs) to synthesise realistic handwritten music sheets. We provide a comprehensive evaluation of three GAN models - DCGAN, ProGAN, and CycleWGAN - comparing their ability to generate diverse and high-quality handwritten music images. The proposed CycleWGAN model, which enhances style transfer and training stability, significantly outperforms DCGAN and ProGAN in both qualitative and quantitative evaluations. CycleWGAN achieves superior performance, with an FID score of 41.87, an IS of 2.29, and a KID of 0.05, making it a promising solution for improving OMR systems.
Diff-MSTC: A Mixing Style Transfer Prototype for Cubase
Nov 10, 2024

In our demo, participants are invited to explore the Diff-MSTC prototype, which integrates the Diff-MST model into Steinberg's digital audio workstation (DAW), Cubase. Diff-MST, a deep learning model for mixing style transfer, forecasts mixing console parameters for tracks using a reference song. The system processes up to 20 raw tracks along with a reference song to predict mixing console parameters that can be used to create an initial mix. Users have the option to manually adjust these parameters further for greater control. In contrast to earlier deep learning systems that are limited to research ideas, Diff-MSTC is a first-of-its-kind prototype integrated into a DAW. This integration facilitates mixing decisions on multitracks and lets users input context through a reference song, followed by fine-tuning of audio effects in a traditional manner.
Knowledge Discovery in Optical Music Recognition: Enhancing Information Retrieval with Instance Segmentation
Aug 27, 2024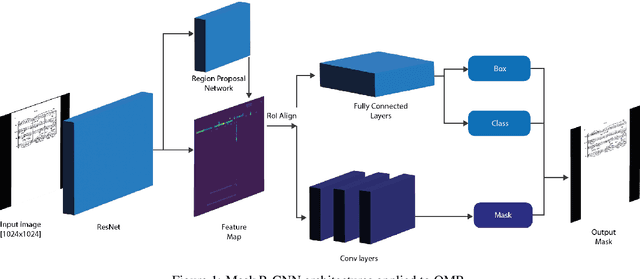
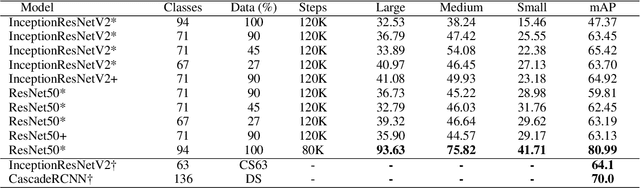
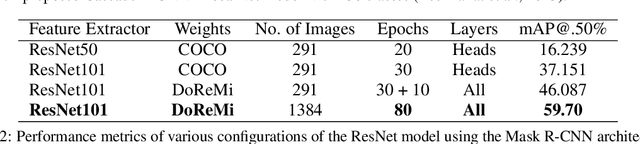
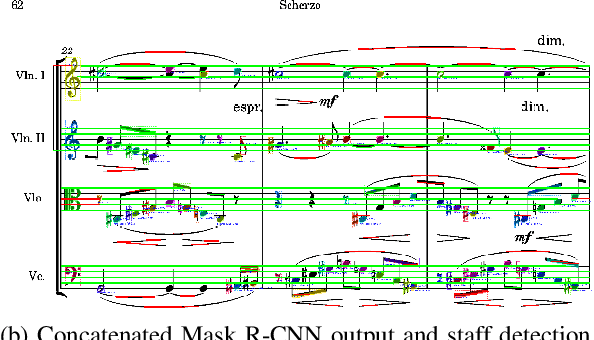
Optical Music Recognition (OMR) automates the transcription of musical notation from images into machine-readable formats like MusicXML, MEI, or MIDI, significantly reducing the costs and time of manual transcription. This study explores knowledge discovery in OMR by applying instance segmentation using Mask R-CNN to enhance the detection and delineation of musical symbols in sheet music. Unlike Optical Character Recognition (OCR), OMR must handle the intricate semantics of Common Western Music Notation (CWMN), where symbol meanings depend on shape, position, and context. Our approach leverages instance segmentation to manage the density and overlap of musical symbols, facilitating more precise information retrieval from music scores. Evaluations on the DoReMi and MUSCIMA++ datasets demonstrate substantial improvements, with our method achieving a mean Average Precision (mAP) of up to 59.70\% in dense symbol environments, achieving comparable results to object detection. Furthermore, using traditional computer vision techniques, we add a parallel step for staff detection to infer the pitch for the recognised symbols. This study emphasises the role of pixel-wise segmentation in advancing accurate music symbol recognition, contributing to knowledge discovery in OMR. Our findings indicate that instance segmentation provides more precise representations of musical symbols, particularly in densely populated scores, advancing OMR technology. We make our implementation, pre-processing scripts, trained models, and evaluation results publicly available to support further research and development.
Music2Latent: Consistency Autoencoders for Latent Audio Compression
Aug 12, 2024



Efficient audio representations in a compressed continuous latent space are critical for generative audio modeling and Music Information Retrieval (MIR) tasks. However, some existing audio autoencoders have limitations, such as multi-stage training procedures, slow iterative sampling, or low reconstruction quality. We introduce Music2Latent, an audio autoencoder that overcomes these limitations by leveraging consistency models. Music2Latent encodes samples into a compressed continuous latent space in a single end-to-end training process while enabling high-fidelity single-step reconstruction. Key innovations include conditioning the consistency model on upsampled encoder outputs at all levels through cross connections, using frequency-wise self-attention to capture long-range frequency dependencies, and employing frequency-wise learned scaling to handle varying value distributions across frequencies at different noise levels. We demonstrate that Music2Latent outperforms existing continuous audio autoencoders in sound quality and reconstruction accuracy while achieving competitive performance on downstream MIR tasks using its latent representations. To our knowledge, this represents the first successful attempt at training an end-to-end consistency autoencoder model.