 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Unified Representation Evaluation Framework Beyond Downstream Tasks
May 09, 2025Downstream probing has been the dominant method for evaluating model representations, an important process given the increasing prominence of self-supervised learning and foundation models. However, downstream probing primarily assesses the availability of task-relevant information in the model's latent space, overlooking attributes such as equivariance, invariance, and disentanglement, which contribute to the interpretability, adaptability, and utility of representations in real-world applications. While some attempts have been made to measure these qualities in representations, no unified evaluation framework with modular, generalizable, and interpretable metrics exists. In this paper, we argue for the importance of representation evaluation beyond downstream probing. We introduce a standardized protocol to quantify informativeness, equivariance, invariance, and disentanglement of factors of variation in model representations. We use it to evaluate representations from a variety of models in the image and speech domains using different architectures and pretraining approaches on identified controllable factors of variation. We find that representations from models with similar downstream performance can behave substantially differently with regard to these attributes. This hints that the respective mechanisms underlying their downstream performance are functionally different, prompting new research directions to understand and improve representations.
Leave-One-EquiVariant: Alleviating invariance-related information loss in contrastive music representations
Dec 25, 2024



Contrastive learning has proven effective in self-supervised musical representation learning, particularly for Music Information Retrieval (MIR) tasks. However, reliance on augmentation chains for contrastive view generation and the resulting learnt invariances pose challenges when different downstream tasks require sensitivity to certain musical attributes. To address this, we propose the Leave One EquiVariant (LOEV) framework, which introduces a flexible, task-adaptive approach compared to previous work by selectively preserving information about specific augmentations, allowing the model to maintain task-relevant equivariances. We demonstrate that LOEV alleviates information loss related to learned invariances, improving performance on augmentation related tasks and retrieval without sacrificing general representation quality. Furthermore, we introduce a variant of LOEV, LOEV++, which builds a disentangled latent space by design in a self-supervised manner, and enables targeted retrieval based on augmentation related attributes.
Foundation Models for Music: A Survey
Aug 27, 2024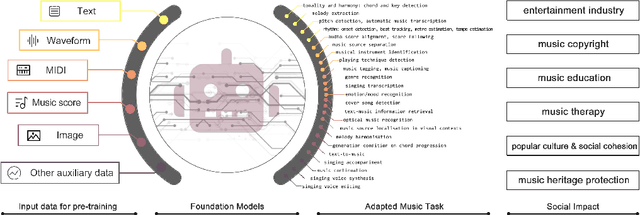

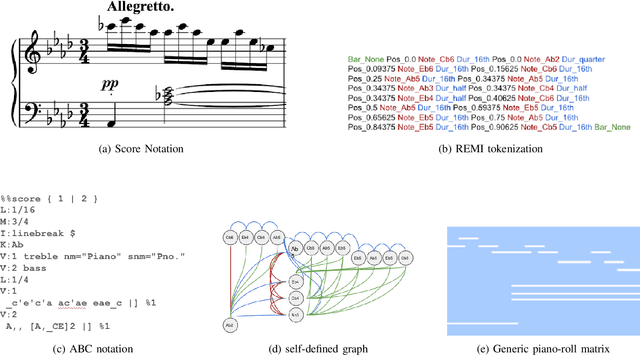
In recent years, foundation models (FMs) such as large language models (LLMs) and latent diffusion models (LDMs) have profoundly impacted diverse sectors, including music. This comprehensive review examines state-of-the-art (SOTA) pre-trained models and foundation models in music, spanning from representation learning, generative learning and multimodal learning. We first contextualise the significance of music in various industries and trace the evolution of AI in music. By delineating the modalities targeted by foundation models, we discover many of the music representations are underexplored in FM development. Then, emphasis is placed on the lack of versatility of previous methods on diverse music applications, along with the potential of FMs in music understanding, generation and medical application. By comprehensively exploring the details of the model pre-training paradigm, architectural choices, tokenisation, finetuning methodologies and controllability, we emphasise the important topics that should have been well explored, like instruction tuning and in-context learning, scaling law and emergent ability, as well as long-sequence modelling etc. A dedicated section presents insights into music agents, accompanied by a thorough analysis of datasets and evaluations essential for pre-training and downstream tasks. Finally, by underscoring the vital importance of ethical considerations, we advocate that following research on FM for music should focus more on such issues as interpretability, transparency, human responsibility, and copyright issues. The paper offers insights into future challenges and trends on FMs for music, aiming to shape the trajectory of human-AI collaboration in the music realm.
Semi-Supervised Contrastive Learning of Musical Representations
Jul 18, 2024



Despite the success of contrastive learning in Music Information Retrieval, the inherent ambiguity of contrastive self-supervision presents a challenge. Relying solely on augmentation chains and self-supervised positive sampling strategies can lead to a pretraining objective that does not capture key musical information for downstream tasks. We introduce semi-supervised contrastive learning (SemiSupCon), a simple method for leveraging musically informed labeled data (supervision signals) in the contrastive learning of musical representations. Our approach introduces musically relevant supervision signals into self-supervised contrastive learning by combining supervised and self-supervised contrastive objectives in a simpler framework than previous approaches. This framework improves downstream performance and robustness to audio corruptions on a range of downstream MIR tasks with moderate amounts of labeled data. Our approach enables shaping the learned similarity metric through the choice of labeled data that (1) infuses the representations with musical domain knowledge and (2) improves out-of-domain performance with minimal general downstream performance loss. We show strong transfer learning performance on musically related yet not trivially similar tasks - such as pitch and key estimation. Additionally, our approach shows performance improvement on automatic tagging over self-supervised approaches with only 5\% of available labels included in pretraining.