 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Alignment of Audio Representations with Timbre Similarity Ratings
Jul 10, 2025Psychoacoustical so-called "timbre spaces" map perceptual similarity ratings of instrument sounds onto low-dimensional embeddings via multidimensional scaling, but suffer from scalability issues and are incapable of generalization. Recent results from audio (music and speech) quality assessment as well as image similarity have shown that deep learning is able to produce embeddings that align well with human perception while being largely free from these constraints. Although the existing human-rated timbre similarity data is not large enough to train deep neural networks (2,614 pairwise ratings on 334 audio samples), it can serve as test-only data for audio models. In this paper, we introduce metrics to assess the alignment of diverse audio representations with human judgments of timbre similarity by comparing both the absolute values and the rankings of embedding distances to human similarity ratings. Our evaluation involves three signal-processing-based representations, twelve representations extracted from pre-trained models, and three representations extracted from a novel sound matching model. Among them, the style embeddings inspired by image style transfer, extracted from the CLAP model and the sound matching model, remarkably outperform the others, showing their potential in modeling timbre similarity.
Audio synthesizer inversion in symmetric parameter spaces with approximately equivariant flow matching
Jun 08, 2025Many audio synthesizers can produce the same signal given different parameter configurations, meaning the inversion from sound to parameters is an inherently ill-posed problem. We show that this is largely due to intrinsic symmetries of the synthesizer, and focus in particular on permutation invariance. First, we demonstrate on a synthetic task that regressing point estimates under permutation symmetry degrades performance, even when using a permutation-invariant loss function or symmetry-breaking heuristics. Then, viewing equivalent solutions as modes of a probability distribution, we show that a conditional generative model substantially improves performance. Further, acknowledging the invariance of the implicit parameter distribution, we find that performance is further improved by using a permutation equivariant continuous normalizing flow. To accommodate intricate symmetries in real synthesizers, we also propose a relaxed equivariance strategy that adaptively discovers relevant symmetries from data. Applying our method to Surge XT, a full-featured open source synthesizer used in real world audio production, we find our method outperforms regression and generative baselines across audio reconstruction metrics.
Mamba-Diffusion Model with Learnable Wavelet for Controllable Symbolic Music Generation
May 06, 2025The recent surge in the popularity of diffusion models for image synthesis has attracted new attention to their potential for generation tasks in other domains. However, their applications to symbolic music generation remain largely under-explored because symbolic music is typically represented as sequences of discrete events and standard diffusion models are not well-suited for discrete data. We represent symbolic music as image-like pianorolls, facilitating the use of diffusion models for the generation of symbolic music. Moreover, this study introduces a novel diffusion model that incorporates our proposed Transformer-Mamba block and learnable wavelet transform. Classifier-free guidance is utilised to generate symbolic music with target chords. Our evaluation shows that our method achieves compelling results in terms of music quality and controllability, outperforming the strong baseline in pianoroll generation. Our code is available at https://github.com/jinchengzhanggg/proffusion.
Designing Neural Synthesizers for Low Latency Interaction
Mar 14, 2025Neural Audio Synthesis (NAS) models offer interactive musical control over high-quality, expressive audio generators. While these models can operate in real-time, they often suffer from high latency, making them unsuitable for intimate musical interaction. The impact of architectural choices in deep learning models on audio latency remains largely unexplored in the NAS literature. In this work, we investigate the sources of latency and jitter typically found in interactive NAS models. We then apply this analysis to the task of timbre transfer using RAVE, a convolutional variational autoencoder for audio waveforms introduced by Caillon et al. in 2021. Finally, we present an iterative design approach for optimizing latency. This culminates with a model we call BRAVE (Bravely Realtime Audio Variational autoEncoder), which is low-latency and exhibits better pitch and loudness replication while showing timbre modification capabilities similar to RAVE. We implement it in a specialized inference framework for low-latency, real-time inference and present a proof-of-concept audio plugin compatible with audio signals from musical instruments. We expect the challenges and guidelines described in this document to support NAS researchers in designing models for low-latency inference from the ground up, enriching the landscape of possibilities for musicians.
Foundation Models for Music: A Survey
Aug 27, 2024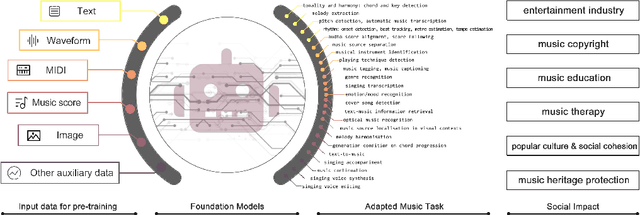

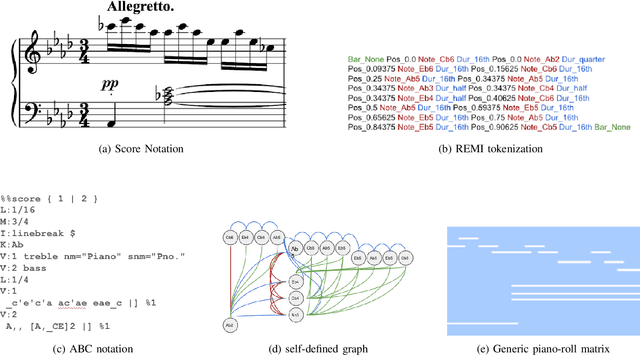
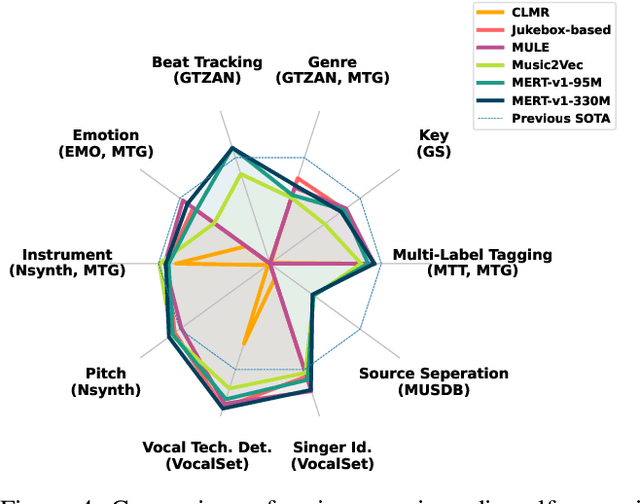
In recent years, foundation models (FMs) such as large language models (LLMs) and latent diffusion models (LDMs) have profoundly impacted diverse sectors, including music. This comprehensive review examines state-of-the-art (SOTA) pre-trained models and foundation models in music, spanning from representation learning, generative learning and multimodal learning. We first contextualise the significance of music in various industries and trace the evolution of AI in music. By delineating the modalities targeted by foundation models, we discover many of the music representations are underexplored in FM development. Then, emphasis is placed on the lack of versatility of previous methods on diverse music applications, along with the potential of FMs in music understanding, generation and medical application. By comprehensively exploring the details of the model pre-training paradigm, architectural choices, tokenisation, finetuning methodologies and controllability, we emphasise the important topics that should have been well explored, like instruction tuning and in-context learning, scaling law and emergent ability, as well as long-sequence modelling etc. A dedicated section presents insights into music agents, accompanied by a thorough analysis of datasets and evaluations essential for pre-training and downstream tasks. Finally, by underscoring the vital importance of ethical considerations, we advocate that following research on FM for music should focus more on such issues as interpretability, transparency, human responsibility, and copyright issues. The paper offers insights into future challenges and trends on FMs for music, aiming to shape the trajectory of human-AI collaboration in the music realm.
Real-time Timbre Remapping with Differentiable DSP
Jul 05, 2024



Timbre is a primary mode of expression in diverse musical contexts. However, prevalent audio-driven synthesis methods predominantly rely on pitch and loudness envelopes, effectively flattening timbral expression from the input. Our approach draws on the concept of timbre analogies and investigates how timbral expression from an input signal can be mapped onto controls for a synthesizer. Leveraging differentiable digital signal processing, our method facilitates direct optimization of synthesizer parameters through a novel feature difference loss. This loss function, designed to learn relative timbral differences between musical events, prioritizes the subtleties of graded timbre modulations within phrases, allowing for meaningful translations in a timbre space. Using snare drum performances as a case study, where timbral expression is central, we demonstrate real-time timbre remapping from acoustic snare drums to a differentiable synthesizer modeled after the Roland TR-808.
MoralBERT: Detecting Moral Values in Social Discourse
Mar 12, 2024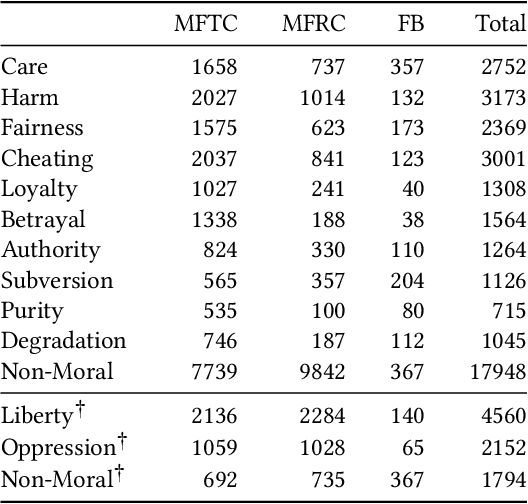
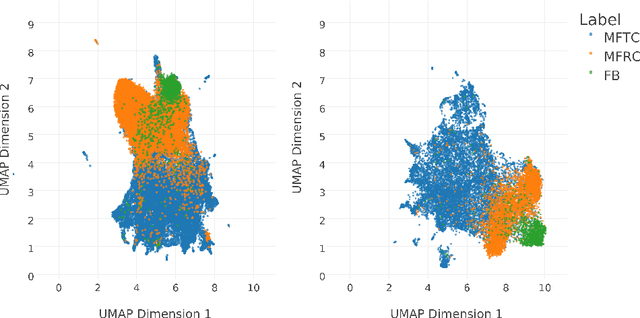
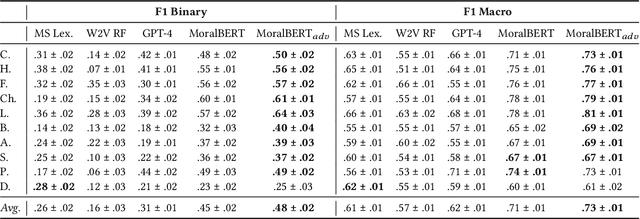
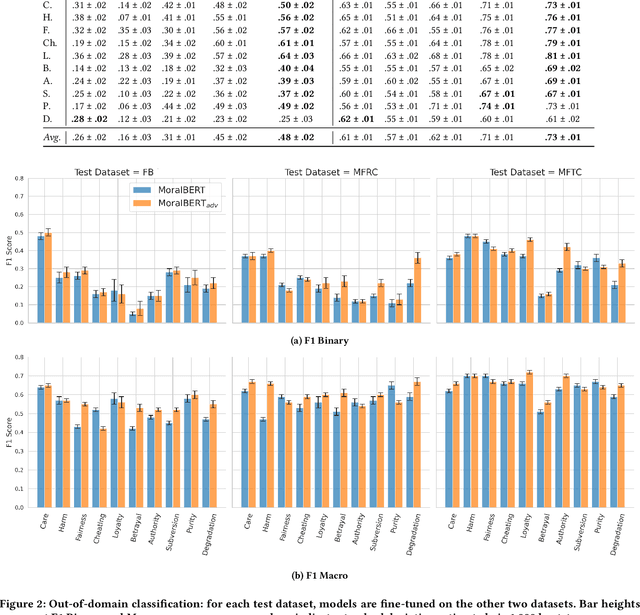
Morality plays a fundamental role in how we perceive information while greatly influencing our decisions and judgements. Controversial topics, including vaccination, abortion, racism, and sexuality, often elicit opinions and attitudes that are not solely based on evidence but rather reflect moral worldviews. Recent advances in natural language processing have demonstrated that moral values can be gauged in human-generated textual content. Here, we design a range of language representation models fine-tuned to capture exactly the moral nuances in text, called MoralBERT. We leverage annotated moral data from three distinct sources: Twitter, Reddit, and Facebook user-generated content covering various socially relevant topics. This approach broadens linguistic diversity and potentially enhances the models' ability to comprehend morality in various contexts. We also explore a domain adaptation technique and compare it to the standard fine-tuned BERT model, using two different frameworks for moral prediction: single-label and multi-label. We compare in-domain approaches with conventional models relying on lexicon-based techniques, as well as a Machine Learning classifier with Word2Vec representation. Our results showed that in-domain prediction models significantly outperformed traditional models. While the single-label setting reaches a higher accuracy than previously achieved for the task when using BERT pretrained models. Experiments in an out-of-domain setting, instead, suggest that further work is needed for existing domain adaptation techniques to generalise between different social media platforms, especially for the multi-label task. The investigations and outcomes from this study pave the way for further exploration, enabling a more profound comprehension of moral narratives about controversial social issues.
Composer Style-specific Symbolic Music Generation Using Vector Quantized Discrete Diffusion Models
Oct 21, 2023



Emerging Denoising Diffusion Probabilistic Models (DDPM) have become increasingly utilised because of promising results they have achieved in diverse generative tasks with continuous data, such as image and sound synthesis. Nonetheless, the success of diffusion models has not been fully extended to discrete symbolic music. We propose to combine a vector quantized variational autoencoder (VQ-VAE) and discrete diffusion models for the generation of symbolic music with desired composer styles. The trained VQ-VAE can represent symbolic music as a sequence of indexes that correspond to specific entries in a learned codebook. Subsequently, a discrete diffusion model is used to model the VQ-VAE's discrete latent space. The diffusion model is trained to generate intermediate music sequences consisting of codebook indexes, which are then decoded to symbolic music using the VQ-VAE's decoder. The results demonstrate our model can generate symbolic music with target composer styles that meet the given conditions with a high accuracy of 72.36%.
Fast Diffusion GAN Model for Symbolic Music Generation Controlled by Emotions
Oct 21, 2023Diffusion models have shown promising results for a wide range of generative tasks with continuous data, such as image and audio synthesis. However, little progress has been made on using diffusion models to generate discrete symbolic music because this new class of generative models are not well suited for discrete data while its iterative sampling process is computationally expensive. In this work, we propose a diffusion model combined with a Generative Adversarial Network, aiming to (i) alleviate one of the remaining challenges in algorithmic music generation which is the control of generation towards a target emotion, and (ii) mitigate the slow sampling drawback of diffusion models applied to symbolic music generation. We first used a trained Variational Autoencoder to obtain embeddings of a symbolic music dataset with emotion labels and then used those to train a diffusion model. Our results demonstrate the successful control of our diffusion model to generate symbolic music with a desired emotion. Our model achieves several orders of magnitude improvement in computational cost, requiring merely four time steps to denoise while the steps required by current state-of-the-art diffusion models for symbolic music generation is in the order of thousands.
Differentiable Modelling of Percussive Audio with Transient and Spectral Synthesis
Sep 13, 2023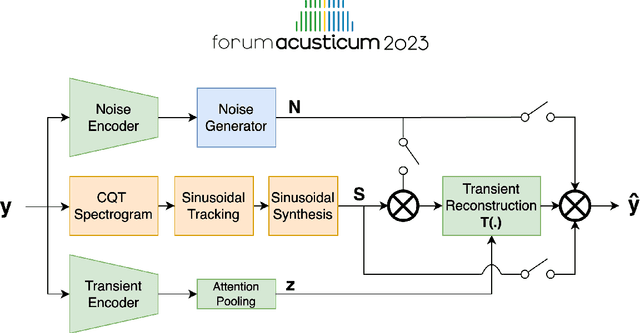
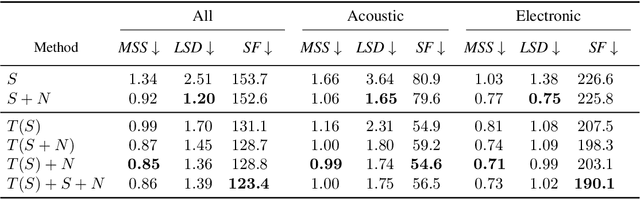
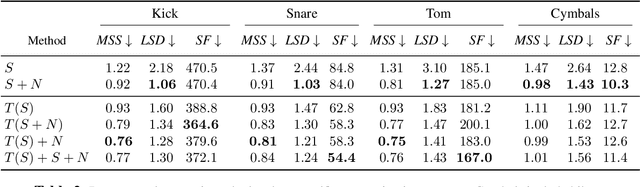
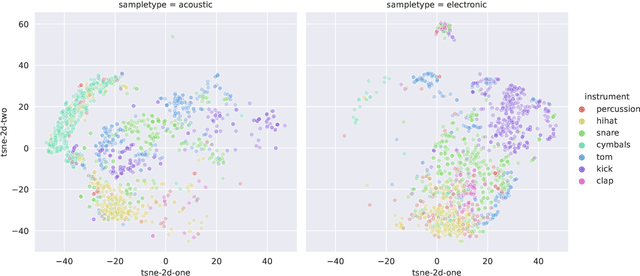
Differentiable digital signal processing (DDSP) techniques, including methods for audio synthesis, have gained attention in recent years and lend themselves to interpretability in the parameter space. However, current differentiable synthesis methods have not explicitly sought to model the transient portion of signals, which is important for percussive sounds. In this work, we present a unified synthesis framework aiming to address transient generation and percussive synthesis within a DDSP framework. To this end, we propose a model for percussive synthesis that builds on sinusoidal modeling synthesis and incorporates a modulated temporal convolutional network for transient generation. We use a modified sinusoidal peak picking algorithm to generate time-varying non-harmonic sinusoids and pair it with differentiable noise and transient encoders that are jointly trained to reconstruct drumset sounds. We compute a set of reconstruction metrics using a large dataset of acoustic and electronic percussion samples that show that our method leads to improved onset signal reconstruction for membranophone percussion instruments.