 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo LLMs Act Like Rational Agents? Measuring Belief Coherence in Probabilistic Decision Making
Feb 06, 2026Large language models (LLMs) are increasingly deployed as agents in high-stakes domains where optimal actions depend on both uncertainty about the world and consideration of utilities of different outcomes, yet their decision logic remains difficult to interpret. We study whether LLMs are rational utility maximizers with coherent beliefs and stable preferences. We consider behaviors of models for diagnosis challenge problems. The results provide insights about the relationship of LLM inferences to ideal Bayesian utility maximization for elicited probabilities and observed actions. Our approach provides falsifiable conditions under which the reported probabilities \emph{cannot} correspond to the true beliefs of any rational agent. We apply this methodology to multiple medical diagnostic domains with evaluations across several LLMs. We discuss implications of the results and directions forward for uses of LLMs in guiding high-stakes decisions.
Predicting Language Models' Success at Zero-Shot Probabilistic Prediction
Sep 18, 2025Recent work has investigated the capabilities of large language models (LLMs) as zero-shot models for generating individual-level characteristics (e.g., to serve as risk models or augment survey datasets). However, when should a user have confidence that an LLM will provide high-quality predictions for their particular task? To address this question, we conduct a large-scale empirical study of LLMs' zero-shot predictive capabilities across a wide range of tabular prediction tasks. We find that LLMs' performance is highly variable, both on tasks within the same dataset and across different datasets. However, when the LLM performs well on the base prediction task, its predicted probabilities become a stronger signal for individual-level accuracy. Then, we construct metrics to predict LLMs' performance at the task level, aiming to distinguish between tasks where LLMs may perform well and where they are likely unsuitable. We find that some of these metrics, each of which are assessed without labeled data, yield strong signals of LLMs' predictive performance on new tasks.
Towards An Integrated Approach for Expressive Piano Performance Synthesis from Music Scores
Jan 17, 2025


This paper presents an integrated system that transforms symbolic music scores into expressive piano performance audio. By combining a Transformer-based Expressive Performance Rendering (EPR) model with a fine-tuned neural MIDI synthesiser, our approach directly generates expressive audio performances from score inputs. To the best of our knowledge, this is the first system to offer a streamlined method for converting score MIDI files lacking expression control into rich, expressive piano performances. We conducted experiments using subsets of the ATEPP dataset, evaluating the system with both objective metrics and subjective listening tests. Our system not only accurately reconstructs human-like expressiveness, but also captures the acoustic ambience of environments such as concert halls and recording studios. Additionally, the proposed system demonstrates its ability to achieve musical expressiveness while ensuring good audio quality in its outputs.
Composer Style-specific Symbolic Music Generation Using Vector Quantized Discrete Diffusion Models
Oct 21, 2023



Emerging Denoising Diffusion Probabilistic Models (DDPM) have become increasingly utilised because of promising results they have achieved in diverse generative tasks with continuous data, such as image and sound synthesis. Nonetheless, the success of diffusion models has not been fully extended to discrete symbolic music. We propose to combine a vector quantized variational autoencoder (VQ-VAE) and discrete diffusion models for the generation of symbolic music with desired composer styles. The trained VQ-VAE can represent symbolic music as a sequence of indexes that correspond to specific entries in a learned codebook. Subsequently, a discrete diffusion model is used to model the VQ-VAE's discrete latent space. The diffusion model is trained to generate intermediate music sequences consisting of codebook indexes, which are then decoded to symbolic music using the VQ-VAE's decoder. The results demonstrate our model can generate symbolic music with target composer styles that meet the given conditions with a high accuracy of 72.36%.
Pianist Identification Using Convolutional Neural Networks
Oct 01, 2023



This paper presents a comprehensive study of automatic performer identification in expressive piano performances using convolutional neural networks (CNNs) and expressive features. Our work addresses the challenging multi-class classification task of identifying virtuoso pianists, which has substantial implications for building dynamic musical instruments with intelligence and smart musical systems. Incorporating recent advancements, we leveraged large-scale expressive piano performance datasets and deep learning techniques. We refined the scores by expanding repetitions and ornaments for more accurate feature extraction. We demonstrated the capability of one-dimensional CNNs for identifying pianists based on expressive features and analyzed the impact of the input sequence lengths and different features. The proposed model outperforms the baseline, achieving 85.3% accuracy in a 6-way identification task. Our refined dataset proved more apt for training a robust pianist identifier, making a substantial contribution to the field of automatic performer identification. Our codes have been released at https://github.com/BetsyTang/PID-CNN.
JAZZVAR: A Dataset of Variations found within Solo Piano Performances of Jazz Standards for Music Overpainting
Jul 18, 2023



Jazz pianists often uniquely interpret jazz standards. Passages from these interpretations can be viewed as sections of variation. We manually extracted such variations from solo jazz piano performances. The JAZZVAR dataset is a collection of 502 pairs of Variation and Original MIDI segments. Each Variation in the dataset is accompanied by a corresponding Original segment containing the melody and chords from the original jazz standard. Our approach differs from many existing jazz datasets in the music information retrieval (MIR) community, which often focus on improvisation sections within jazz performances. In this paper, we outline the curation process for obtaining and sorting the repertoire, the pipeline for creating the Original and Variation pairs, and our analysis of the dataset. We also introduce a new generative music task, Music Overpainting, and present a baseline Transformer model trained on the JAZZVAR dataset for this task. Other potential applications of our dataset include expressive performance analysis and performer identification.
Reconstructing Human Expressiveness in Piano Performances with a Transformer Network
Jun 09, 2023



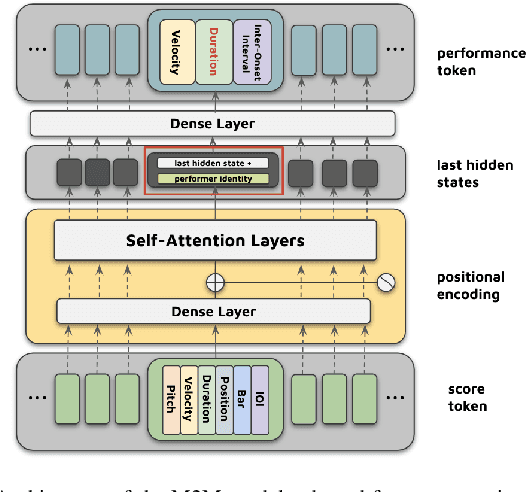
Capturing intricate and subtle variations in human expressiveness in music performance using computational approaches is challenging. In this paper, we propose a novel approach for reconstructing human expressiveness in piano performance with a multi-layer bi-directional Transformer encoder. To address the needs for large amounts of accurately captured and score-aligned performance data in training neural networks, we use transcribed scores obtained from an existing transcription model to train our model. We integrate pianist identities to control the sampling process and explore the ability of our system to model variations in expressiveness for different pianists. The system is evaluated through statistical analysis of generated expressive performances and a listening test. Overall, the results suggest that our method achieves state-of-the-art in generating human-like piano performances from transcribed scores, while fully and consistently reconstructing human expressiveness poses further challenges.
ProSTformer: Pre-trained Progressive Space-Time Self-attention Model for Traffic Flow Forecasting
Nov 03, 2021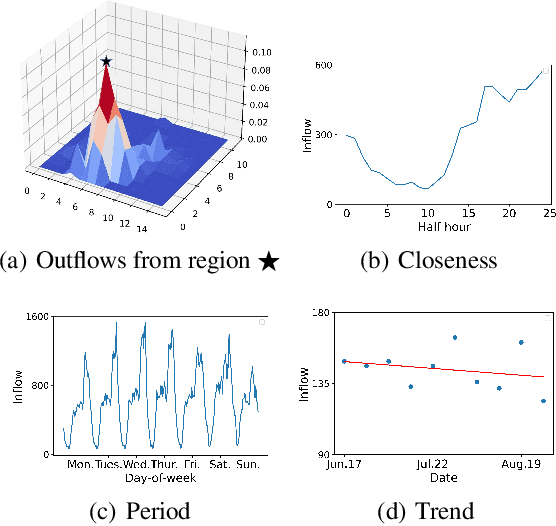
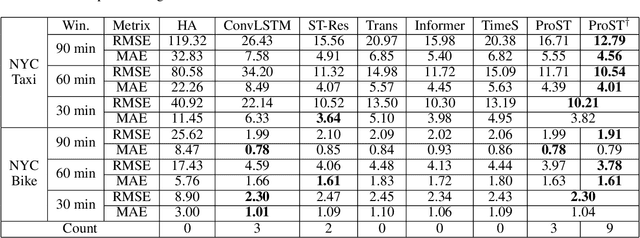
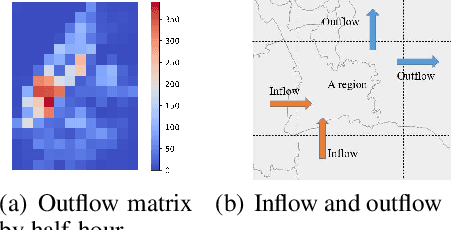
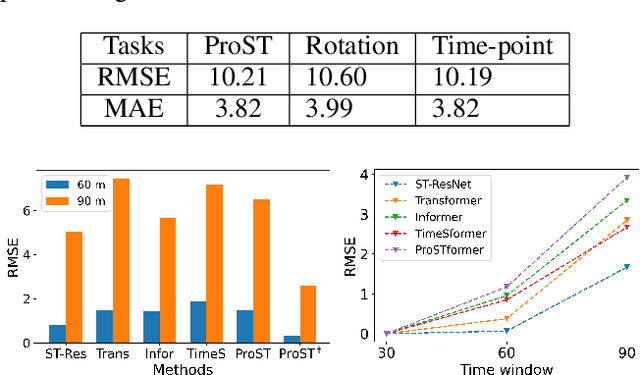
Traffic flow forecasting is essential and challenging to intelligent city management and public safety. Recent studies have shown the potential of convolution-free Transformer approach to extract the dynamic dependencies among complex influencing factors. However, two issues prevent the approach from being effectively applied in traffic flow forecasting. First, it ignores the spatiotemporal structure of the traffic flow videos. Second, for a long sequence, it is hard to focus on crucial attention due to the quadratic times dot-product computation. To address the two issues, we first factorize the dependencies and then design a progressive space-time self-attention mechanism named ProSTformer. It has two distinctive characteristics: (1) corresponding to the factorization, the self-attention mechanism progressively focuses on spatial dependence from local to global regions, on temporal dependence from inside to outside fragment (i.e., closeness, period, and trend), and finally on external dependence such as weather, temperature, and day-of-week; (2) by incorporating the spatiotemporal structure into the self-attention mechanism, each block in ProSTformer highlights the unique dependence by aggregating the regions with spatiotemporal positions to significantly decrease the computation. We evaluate ProSTformer on two traffic datasets, and each dataset includes three separate datasets with big, medium, and small scales. Despite the radically different design compared to the convolutional architectures for traffic flow forecasting, ProSTformer performs better or the same on the big scale datasets than six state-of-the-art baseline methods by RMSE. When pre-trained on the big scale datasets and transferred to the medium and small scale datasets, ProSTformer achieves a significant enhancement and behaves best.