 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePianist Identification Using Convolutional Neural Networks
Oct 01, 2023



This paper presents a comprehensive study of automatic performer identification in expressive piano performances using convolutional neural networks (CNNs) and expressive features. Our work addresses the challenging multi-class classification task of identifying virtuoso pianists, which has substantial implications for building dynamic musical instruments with intelligence and smart musical systems. Incorporating recent advancements, we leveraged large-scale expressive piano performance datasets and deep learning techniques. We refined the scores by expanding repetitions and ornaments for more accurate feature extraction. We demonstrated the capability of one-dimensional CNNs for identifying pianists based on expressive features and analyzed the impact of the input sequence lengths and different features. The proposed model outperforms the baseline, achieving 85.3% accuracy in a 6-way identification task. Our refined dataset proved more apt for training a robust pianist identifier, making a substantial contribution to the field of automatic performer identification. Our codes have been released at https://github.com/BetsyTang/PID-CNN.
Learning music audio representations via weak language supervision
Dec 08, 2021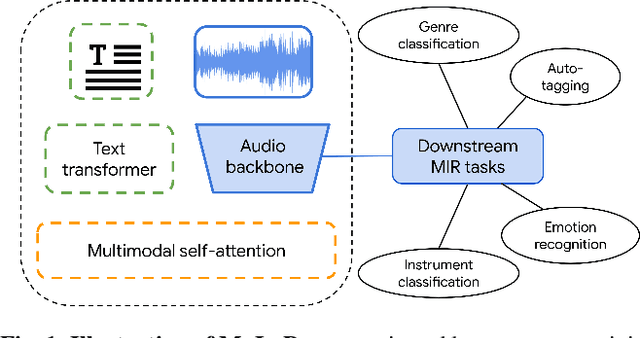
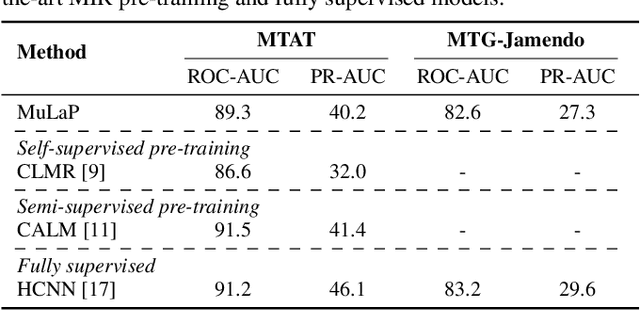
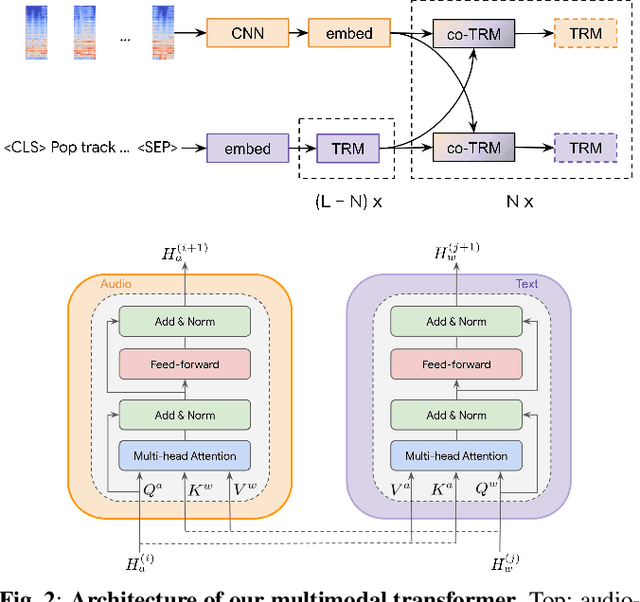
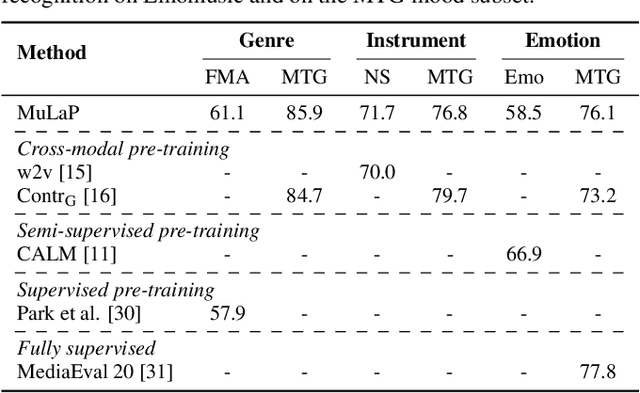
Audio representations for music information retrieval are typically learned via supervised learning in a task-specific fashion. Although effective at producing state-of-the-art results, this scheme lacks flexibility with respect to the range of applications a model can have and requires extensively annotated datasets. In this work, we pose the question of whether it may be possible to exploit weakly aligned text as the only supervisory signal to learn general-purpose music audio representations. To address this question, we design a multimodal architecture for music and language pre-training (MuLaP) optimised via a set of proxy tasks. Weak supervision is provided in the form of noisy natural language descriptions conveying the overall musical content of the track. After pre-training, we transfer the audio backbone of the model to a set of music audio classification and regression tasks. We demonstrate the usefulness of our approach by comparing the performance of audio representations produced by the same audio backbone with different training strategies and show that our pre-training method consistently achieves comparable or higher scores on all tasks and datasets considered. Our experiments also confirm that MuLaP effectively leverages audio-caption pairs to learn representations that are competitive with audio-only and cross-modal self-supervised methods in the literature.
Performer Identification From Symbolic Representation of Music Using Statistical Models
Aug 05, 2021
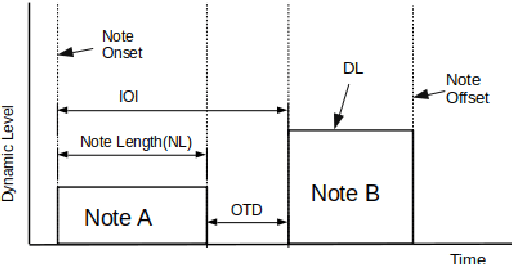
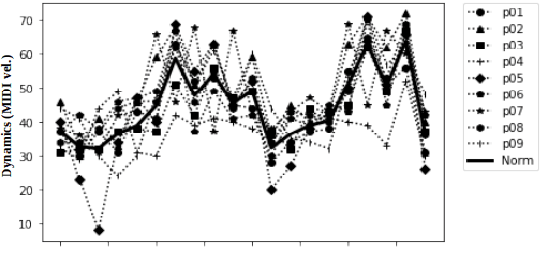
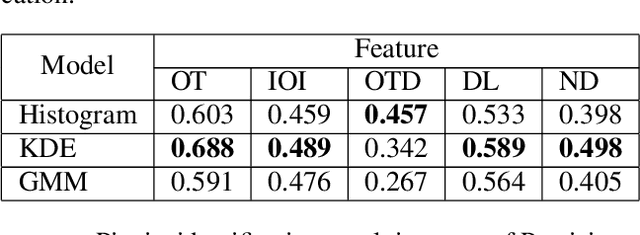
Music Performers have their own idiosyncratic way of interpreting a musical piece. A group of skilled performers playing the same piece of music would likely to inject their unique artistic styles in their performances. The variations of the tempo, timing, dynamics, articulation etc. from the actual notated music are what make the performers unique in their performances. This study presents a dataset consisting of four movements of Schubert's ``Sonata in B-flat major, D.960" performed by nine virtuoso pianists individually. We proposed and extracted a set of expressive features that are able to capture the characteristics of an individual performer's style. We then present a performer identification method based on the similarity of feature distribution, given a set of piano performances. The identification is done considering each feature individually as well as a fusion of the features. Results show that the proposed method achieved a precision of 0.903 using fusion features. Moreover, the onset time deviation feature shows promising result when considered individually.
MusCaps: Generating Captions for Music Audio
Apr 24, 2021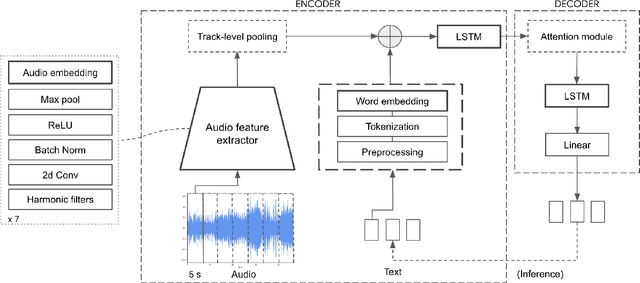
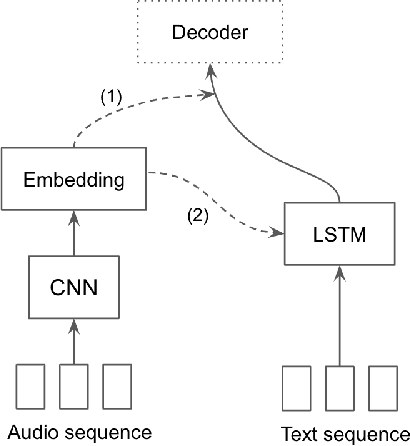
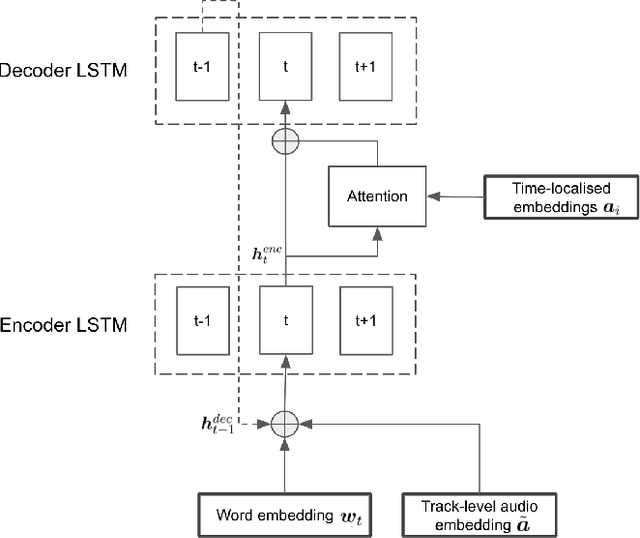

Content-based music information retrieval has seen rapid progress with the adoption of deep learning. Current approaches to high-level music description typically make use of classification models, such as in auto-tagging or genre and mood classification. In this work, we propose to address music description via audio captioning, defined as the task of generating a natural language description of music audio content in a human-like manner. To this end, we present the first music audio captioning model, MusCaps, consisting of an encoder-decoder with temporal attention. Our method combines convolutional and recurrent neural network architectures to jointly process audio-text inputs through a multimodal encoder and leverages pre-training on audio data to obtain representations that effectively capture and summarise musical features in the input. Evaluation of the generated captions through automatic metrics shows that our method outperforms a baseline designed for non-music audio captioning. Through an ablation study, we unveil that this performance boost can be mainly attributed to pre-training of the audio encoder, while other design choices - modality fusion, decoding strategy and the use of attention - contribute only marginally. Our model represents a shift away from classification-based music description and combines tasks requiring both auditory and linguistic understanding to bridge the semantic gap in music information retrieval.