 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLive Music Models
Aug 06, 2025We introduce a new class of generative models for music called live music models that produce a continuous stream of music in real-time with synchronized user control. We release Magenta RealTime, an open-weights live music model that can be steered using text or audio prompts to control acoustic style. On automatic metrics of music quality, Magenta RealTime outperforms other open-weights music generation models, despite using fewer parameters and offering first-of-its-kind live generation capabilities. We also release Lyria RealTime, an API-based model with extended controls, offering access to our most powerful model with wide prompt coverage. These models demonstrate a new paradigm for AI-assisted music creation that emphasizes human-in-the-loop interaction for live music performance.
Augment, Drop & Swap: Improving Diversity in LLM Captions for Efficient Music-Text Representation Learning
Sep 17, 2024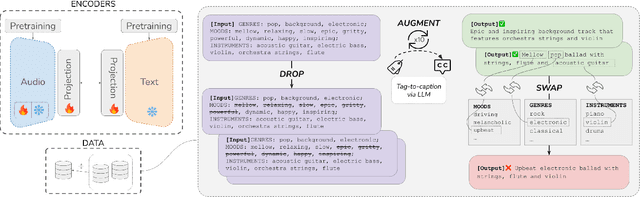
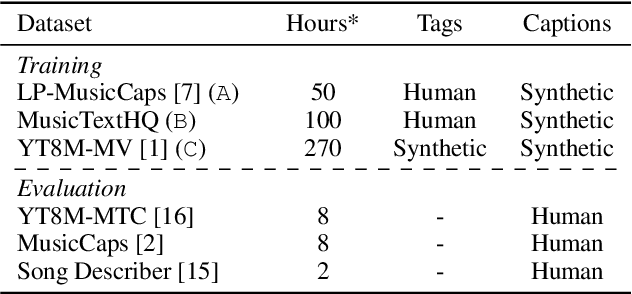
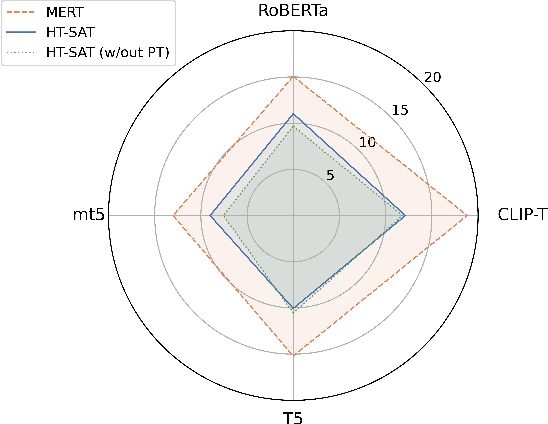

Audio-text contrastive models have become a powerful approach in music representation learning. Despite their empirical success, however, little is known about the influence of key design choices on the quality of music-text representations learnt through this framework. In this work, we expose these design choices within the constraints of limited data and computation budgets, and establish a more solid understanding of their impact grounded in empirical observations along three axes: the choice of base encoders, the level of curation in training data, and the use of text augmentation. We find that data curation is the single most important factor for music-text contrastive training in resource-constrained scenarios. Motivated by this insight, we introduce two novel techniques, Augmented View Dropout and TextSwap, which increase the diversity and descriptiveness of text inputs seen in training. Through our experiments we demonstrate that these are effective at boosting performance across different pre-training regimes, model architectures, and downstream data distributions, without incurring higher computational costs or requiring additional training data.
Foundation Models for Music: A Survey
Aug 27, 2024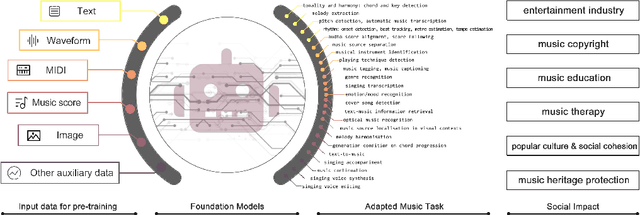

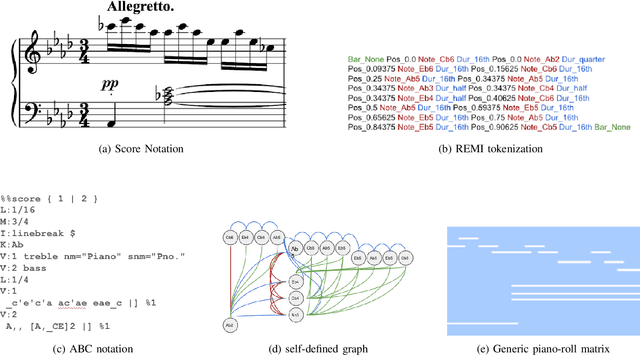
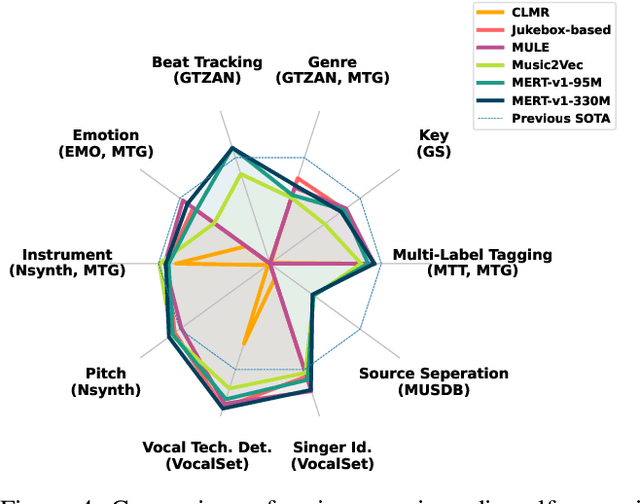
In recent years, foundation models (FMs) such as large language models (LLMs) and latent diffusion models (LDMs) have profoundly impacted diverse sectors, including music. This comprehensive review examines state-of-the-art (SOTA) pre-trained models and foundation models in music, spanning from representation learning, generative learning and multimodal learning. We first contextualise the significance of music in various industries and trace the evolution of AI in music. By delineating the modalities targeted by foundation models, we discover many of the music representations are underexplored in FM development. Then, emphasis is placed on the lack of versatility of previous methods on diverse music applications, along with the potential of FMs in music understanding, generation and medical application. By comprehensively exploring the details of the model pre-training paradigm, architectural choices, tokenisation, finetuning methodologies and controllability, we emphasise the important topics that should have been well explored, like instruction tuning and in-context learning, scaling law and emergent ability, as well as long-sequence modelling etc. A dedicated section presents insights into music agents, accompanied by a thorough analysis of datasets and evaluations essential for pre-training and downstream tasks. Finally, by underscoring the vital importance of ethical considerations, we advocate that following research on FM for music should focus more on such issues as interpretability, transparency, human responsibility, and copyright issues. The paper offers insights into future challenges and trends on FMs for music, aiming to shape the trajectory of human-AI collaboration in the music realm.
MuChoMusic: Evaluating Music Understanding in Multimodal Audio-Language Models
Aug 02, 2024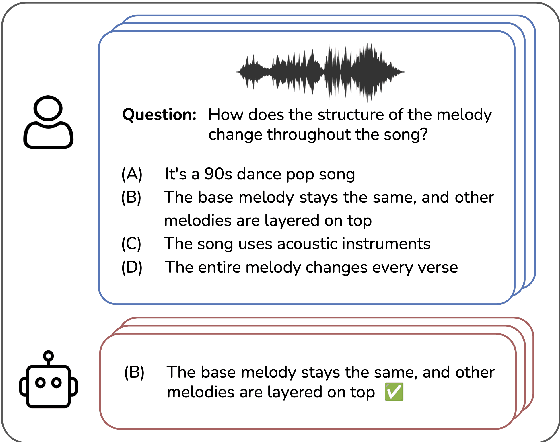
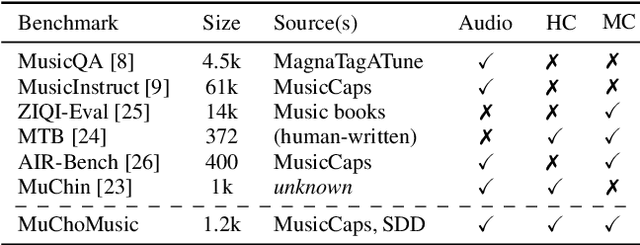
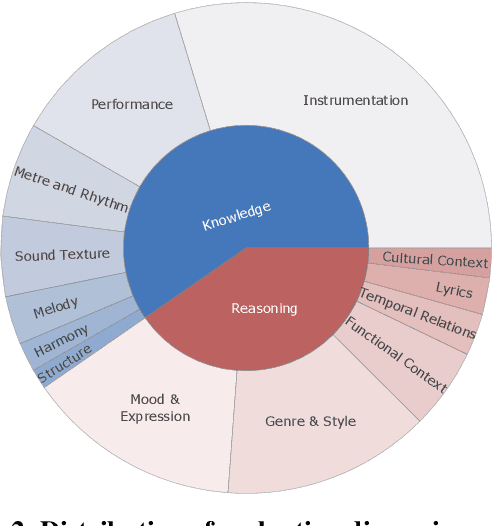

Multimodal models that jointly process audio and language hold great promise in audio understanding and are increasingly being adopted in the music domain. By allowing users to query via text and obtain information about a given audio input, these models have the potential to enable a variety of music understanding tasks via language-based interfaces. However, their evaluation poses considerable challenges, and it remains unclear how to effectively assess their ability to correctly interpret music-related inputs with current methods. Motivated by this, we introduce MuChoMusic, a benchmark for evaluating music understanding in multimodal language models focused on audio. MuChoMusic comprises 1,187 multiple-choice questions, all validated by human annotators, on 644 music tracks sourced from two publicly available music datasets, and covering a wide variety of genres. Questions in the benchmark are crafted to assess knowledge and reasoning abilities across several dimensions that cover fundamental musical concepts and their relation to cultural and functional contexts. Through the holistic analysis afforded by the benchmark, we evaluate five open-source models and identify several pitfalls, including an over-reliance on the language modality, pointing to a need for better multimodal integration. Data and code are open-sourced.
The Song Describer Dataset: a Corpus of Audio Captions for Music-and-Language Evaluation
Nov 22, 2023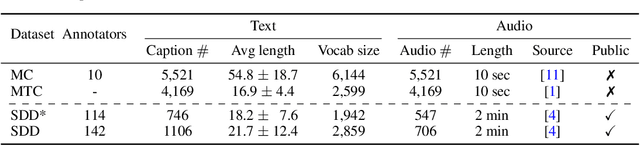
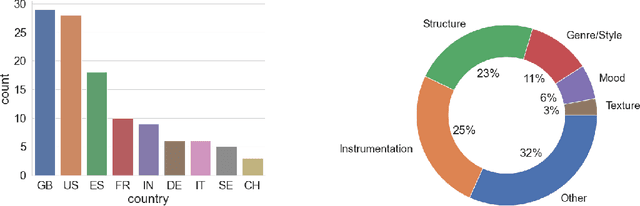


We introduce the Song Describer dataset (SDD), a new crowdsourced corpus of high-quality audio-caption pairs, designed for the evaluation of music-and-language models. The dataset consists of 1.1k human-written natural language descriptions of 706 music recordings, all publicly accessible and released under Creative Common licenses. To showcase the use of our dataset, we benchmark popular models on three key music-and-language tasks (music captioning, text-to-music generation and music-language retrieval). Our experiments highlight the importance of cross-dataset evaluation and offer insights into how researchers can use SDD to gain a broader understanding of model performance.
Serenade: A Model for Human-in-the-loop Automatic Chord Estimation
Oct 17, 2023



Computational harmony analysis is important for MIR tasks such as automatic segmentation, corpus analysis and automatic chord label estimation. However, recent research into the ambiguous nature of musical harmony, causing limited inter-rater agreement, has made apparent that there is a glass ceiling for common metrics such as accuracy. Commonly, these issues are addressed either in the training data itself by creating majority-rule annotations or during the training phase by learning soft targets. We propose a novel alternative approach in which a human and an autoregressive model together co-create a harmonic annotation for an audio track. After automatically generating harmony predictions, a human sparsely annotates parts with low model confidence and the model then adjusts its predictions following human guidance. We evaluate our model on a dataset of popular music and we show that, with this human-in-the-loop approach, harmonic analysis performance improves over a model-only approach. The human contribution is amplified by the second, constrained prediction of the model.
Contrastive Audio-Language Learning for Music
Aug 25, 2022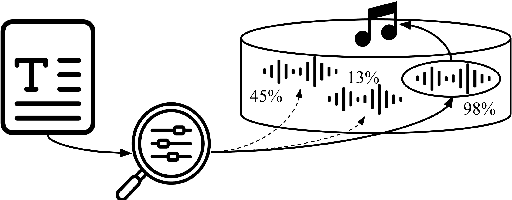

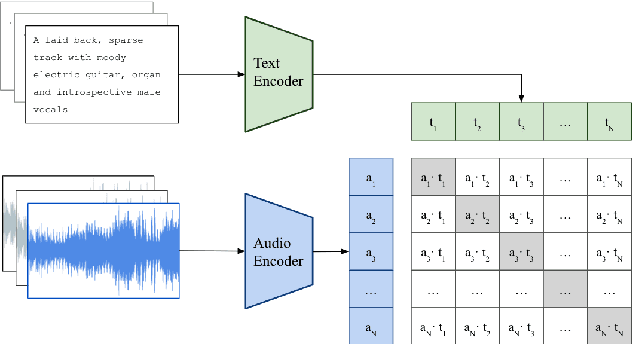
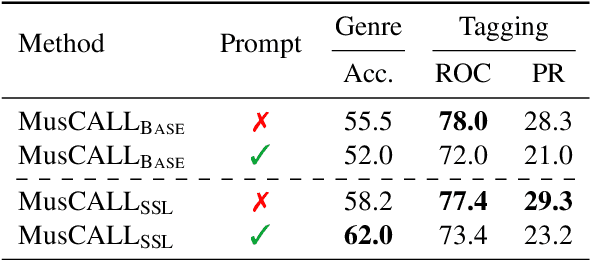
As one of the most intuitive interfaces known to humans, natural language has the potential to mediate many tasks that involve human-computer interaction, especially in application-focused fields like Music Information Retrieval. In this work, we explore cross-modal learning in an attempt to bridge audio and language in the music domain. To this end, we propose MusCALL, a framework for Music Contrastive Audio-Language Learning. Our approach consists of a dual-encoder architecture that learns the alignment between pairs of music audio and descriptive sentences, producing multimodal embeddings that can be used for text-to-audio and audio-to-text retrieval out-of-the-box. Thanks to this property, MusCALL can be transferred to virtually any task that can be cast as text-based retrieval. Our experiments show that our method performs significantly better than the baselines at retrieving audio that matches a textual description and, conversely, text that matches an audio query. We also demonstrate that the multimodal alignment capability of our model can be successfully extended to the zero-shot transfer scenario for genre classification and auto-tagging on two public datasets.
Learning music audio representations via weak language supervision
Dec 08, 2021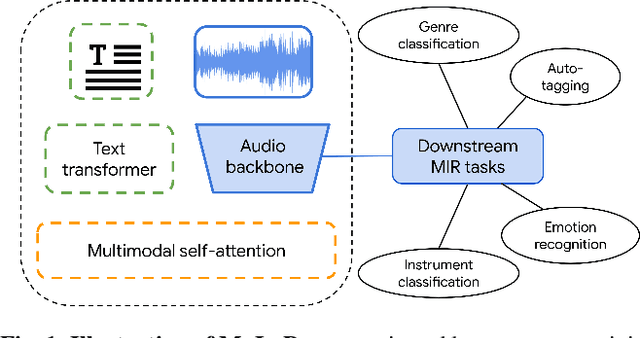
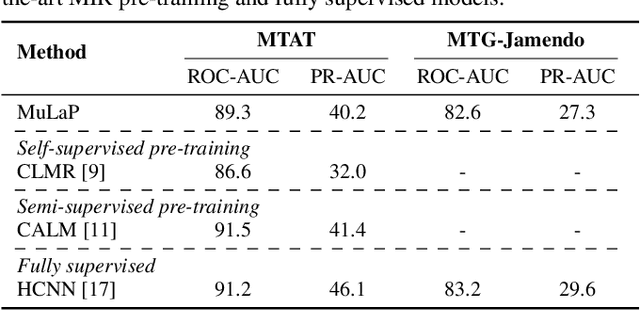
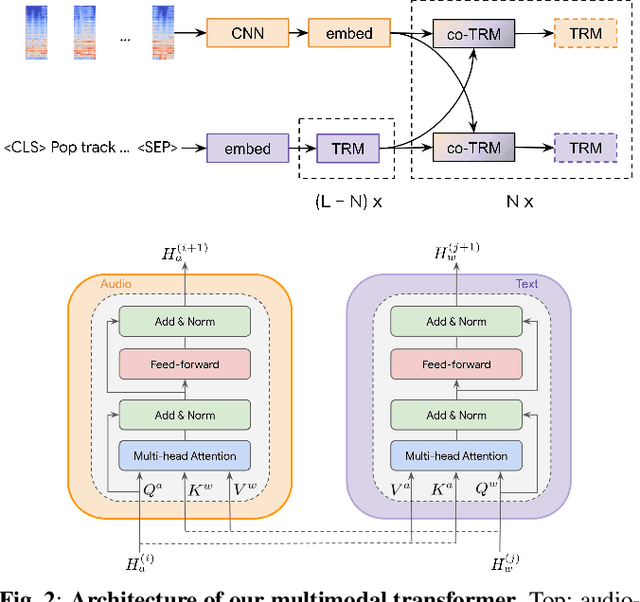
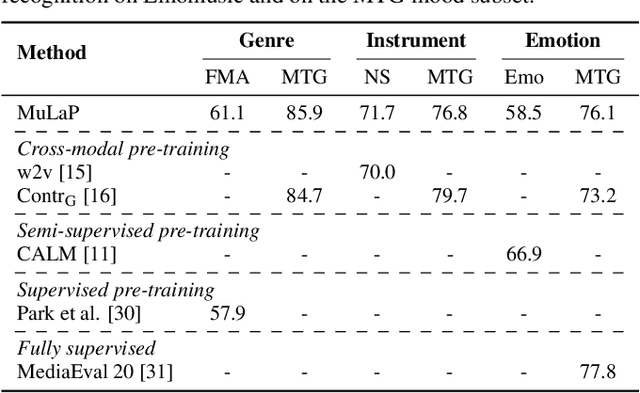
Audio representations for music information retrieval are typically learned via supervised learning in a task-specific fashion. Although effective at producing state-of-the-art results, this scheme lacks flexibility with respect to the range of applications a model can have and requires extensively annotated datasets. In this work, we pose the question of whether it may be possible to exploit weakly aligned text as the only supervisory signal to learn general-purpose music audio representations. To address this question, we design a multimodal architecture for music and language pre-training (MuLaP) optimised via a set of proxy tasks. Weak supervision is provided in the form of noisy natural language descriptions conveying the overall musical content of the track. After pre-training, we transfer the audio backbone of the model to a set of music audio classification and regression tasks. We demonstrate the usefulness of our approach by comparing the performance of audio representations produced by the same audio backbone with different training strategies and show that our pre-training method consistently achieves comparable or higher scores on all tasks and datasets considered. Our experiments also confirm that MuLaP effectively leverages audio-caption pairs to learn representations that are competitive with audio-only and cross-modal self-supervised methods in the literature.
MusCaps: Generating Captions for Music Audio
Apr 24, 2021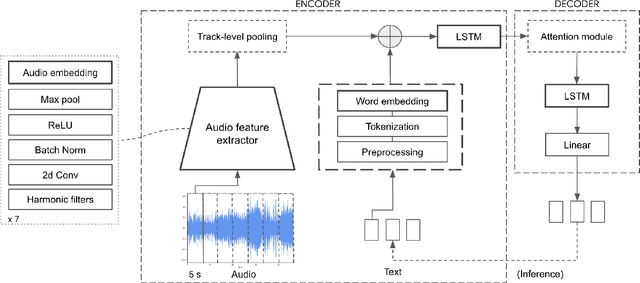
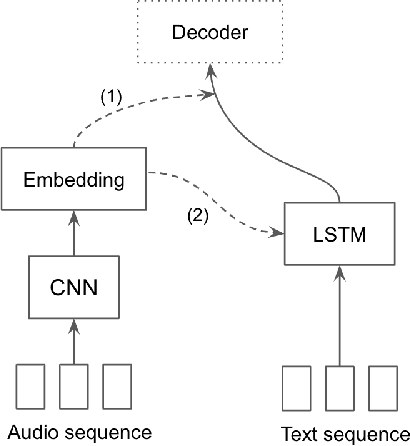
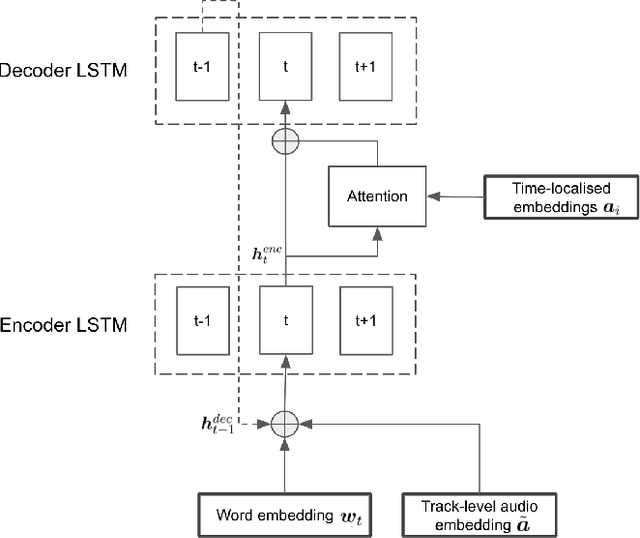

Content-based music information retrieval has seen rapid progress with the adoption of deep learning. Current approaches to high-level music description typically make use of classification models, such as in auto-tagging or genre and mood classification. In this work, we propose to address music description via audio captioning, defined as the task of generating a natural language description of music audio content in a human-like manner. To this end, we present the first music audio captioning model, MusCaps, consisting of an encoder-decoder with temporal attention. Our method combines convolutional and recurrent neural network architectures to jointly process audio-text inputs through a multimodal encoder and leverages pre-training on audio data to obtain representations that effectively capture and summarise musical features in the input. Evaluation of the generated captions through automatic metrics shows that our method outperforms a baseline designed for non-music audio captioning. Through an ablation study, we unveil that this performance boost can be mainly attributed to pre-training of the audio encoder, while other design choices - modality fusion, decoding strategy and the use of attention - contribute only marginally. Our model represents a shift away from classification-based music description and combines tasks requiring both auditory and linguistic understanding to bridge the semantic gap in music information retrieval.