 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Lossy Audio Compression Identification
Jul 31, 2024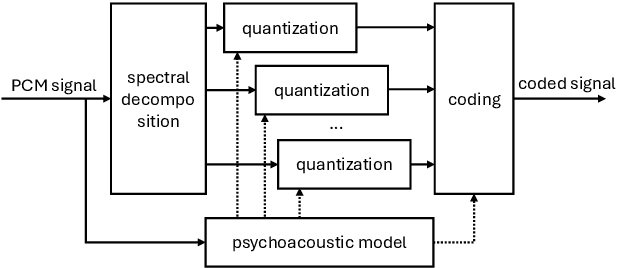

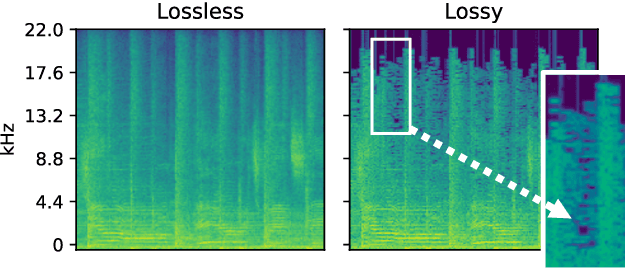

Previous research contributions on blind lossy compression identification report near perfect performance metrics on their test set, across a variety of codecs and bit rates. However, we show that such results can be deceptive and may not accurately represent true ability of the system to tackle the task at hand. In this article, we present an investigation into the robustness and generalisation capability of a lossy audio identification model. Our contributions are as follows. (1) We show the lack of robustness to codec parameter variations of a model equivalent to prior art. In particular, when naively training a lossy compression detection model on a dataset of music recordings processed with a range of codecs and their lossless counterparts, we obtain near perfect performance metrics on the held-out test set, but severely degraded performance on lossy tracks produced with codec parameters not seen in training. (2) We propose and show the effectiveness of an improved training strategy to significantly increase the robustness and generalisation capability of the model beyond codec configurations seen during training. Namely we apply a random mask to the input spectrogram to encourage the model not to rely solely on the training set's codec cutoff frequency.
Serenade: A Model for Human-in-the-loop Automatic Chord Estimation
Oct 17, 2023



Computational harmony analysis is important for MIR tasks such as automatic segmentation, corpus analysis and automatic chord label estimation. However, recent research into the ambiguous nature of musical harmony, causing limited inter-rater agreement, has made apparent that there is a glass ceiling for common metrics such as accuracy. Commonly, these issues are addressed either in the training data itself by creating majority-rule annotations or during the training phase by learning soft targets. We propose a novel alternative approach in which a human and an autoregressive model together co-create a harmonic annotation for an audio track. After automatically generating harmony predictions, a human sparsely annotates parts with low model confidence and the model then adjusts its predictions following human guidance. We evaluate our model on a dataset of popular music and we show that, with this human-in-the-loop approach, harmonic analysis performance improves over a model-only approach. The human contribution is amplified by the second, constrained prediction of the model.
Modeling Baroque Two-Part Counterpoint with Neural Machine Translation
Jun 29, 2020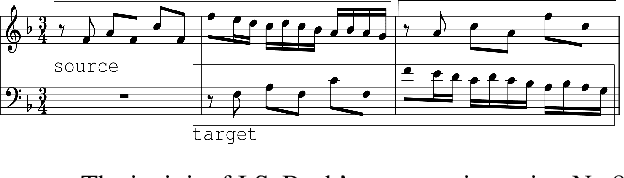
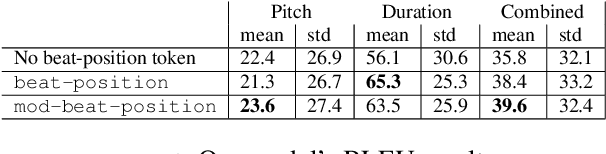
We propose a system for contrapuntal music generation based on a Neural Machine Translation (NMT) paradigm. We consider Baroque counterpoint and are interested in modeling the interaction between any two given parts as a mapping between a given source material and an appropriate target material. Like in translation, the former imposes some constraints on the latter, but doesn't define it completely. We collate and edit a bespoke dataset of Baroque pieces, use it to train an attention-based neural network model, and evaluate the generated output via BLEU score and musicological analysis. We show that our model is able to respond with some idiomatic trademarks, such as imitation and appropriate rhythmic offset, although it falls short of having learned stylistically correct contrapuntal motion (e.g., avoidance of parallel fifths) or stricter imitative rules, such as canon.
A New Optimization Layer for Real-Time Bidding Advertising Campaigns
Aug 07, 2018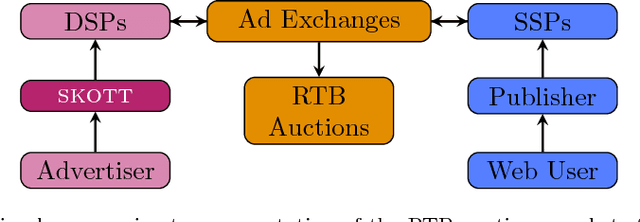
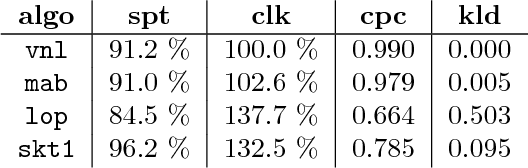
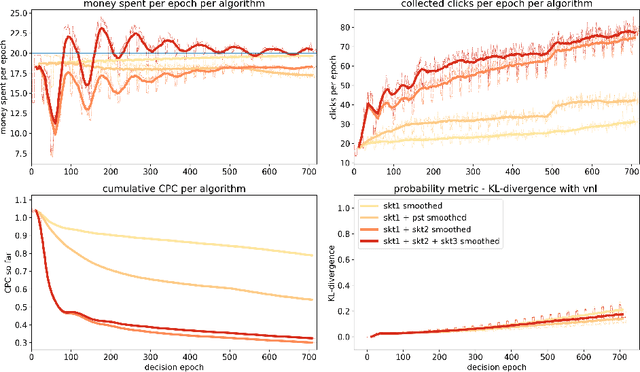
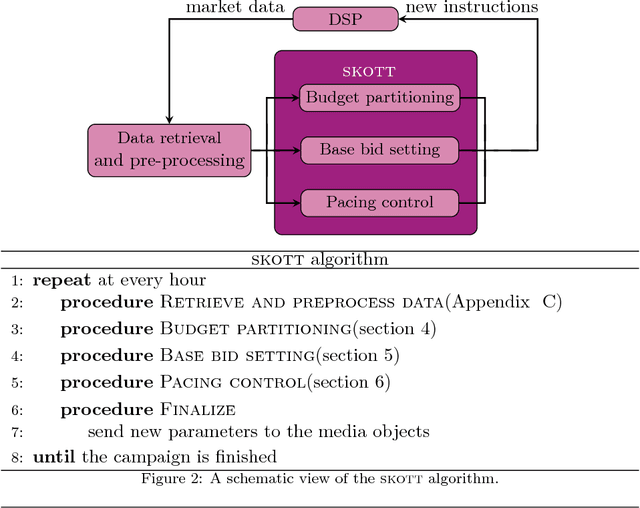
While it is relatively easy to start an online advertising campaign, obtaining a high Key Performance Indicator (KPI) can be challenging. A large body of work on this subject has already been performed and platforms known as DSPs are available on the market that deal with such an optimization. From the advertiser's point of view, each DSP is a different black box, with its pros and cons, that needs to be configured. In order to take advantage of the pros of every DSP, advertisers are well-advised to use a combination of them when setting up their campaigns. In this paper, we propose an algorithm for advertisers to add an optimization layer on top of DSPs. The algorithm we introduce, called SKOTT, maximizes the chosen KPI by optimally configuring the DSPs and putting them in competition with each other. SKOTT is a highly specialized iterative algorithm loosely based on gradient descent that is made up of three independent sub-routines, each dealing with a different problem: partitioning the budget, setting the desired average bid, and preventing under-delivery. In particular, one of the novelties of our approach lies in our taking the perspective of the advertisers rather than the DSPs. Synthetic market data is used to evaluate the efficiency of SKOTT against other state-of-the-art approaches adapted from similar problems. The results illustrate the benefits of our proposals, which greatly outperforms the other methods.