 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Optimization Layer for Real-Time Bidding Advertising Campaigns
Aug 07, 2018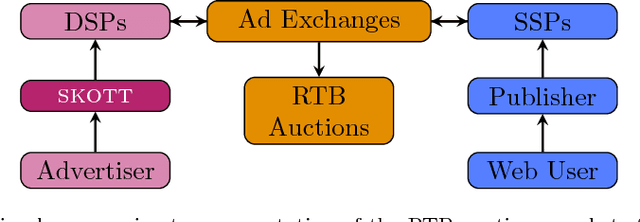
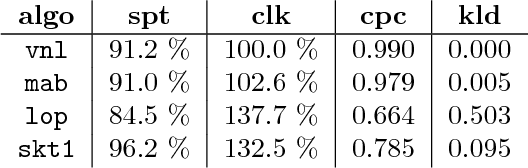
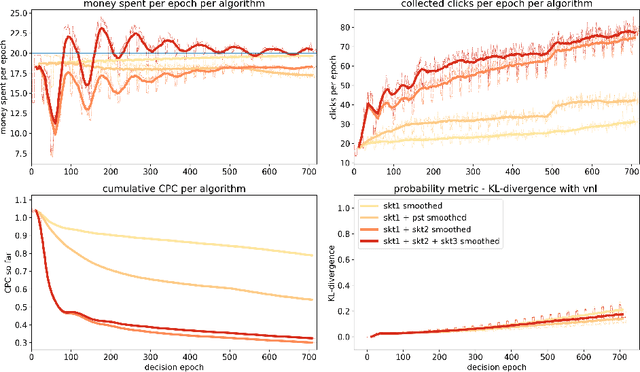
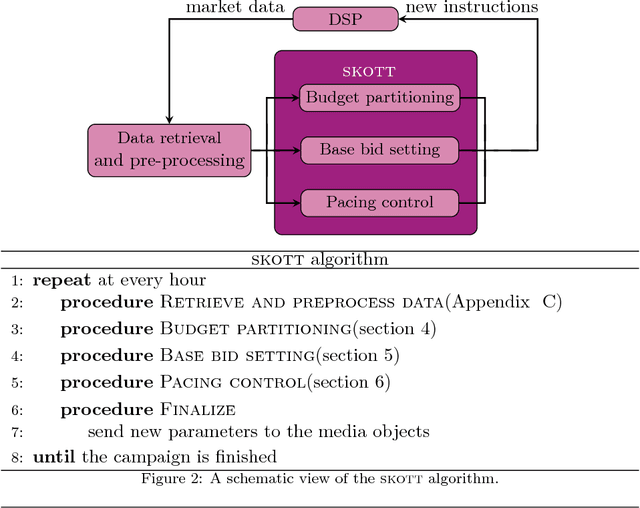
While it is relatively easy to start an online advertising campaign, obtaining a high Key Performance Indicator (KPI) can be challenging. A large body of work on this subject has already been performed and platforms known as DSPs are available on the market that deal with such an optimization. From the advertiser's point of view, each DSP is a different black box, with its pros and cons, that needs to be configured. In order to take advantage of the pros of every DSP, advertisers are well-advised to use a combination of them when setting up their campaigns. In this paper, we propose an algorithm for advertisers to add an optimization layer on top of DSPs. The algorithm we introduce, called SKOTT, maximizes the chosen KPI by optimally configuring the DSPs and putting them in competition with each other. SKOTT is a highly specialized iterative algorithm loosely based on gradient descent that is made up of three independent sub-routines, each dealing with a different problem: partitioning the budget, setting the desired average bid, and preventing under-delivery. In particular, one of the novelties of our approach lies in our taking the perspective of the advertisers rather than the DSPs. Synthetic market data is used to evaluate the efficiency of SKOTT against other state-of-the-art approaches adapted from similar problems. The results illustrate the benefits of our proposals, which greatly outperforms the other methods.
Sparsification of the Alignment Path Search Space in Dynamic Time Warping
Nov 13, 2017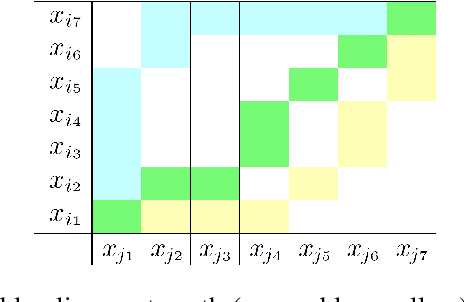
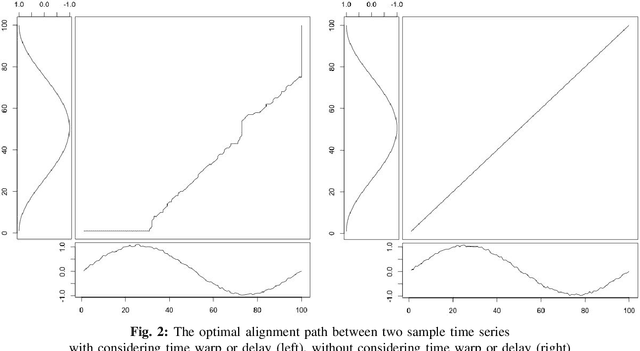
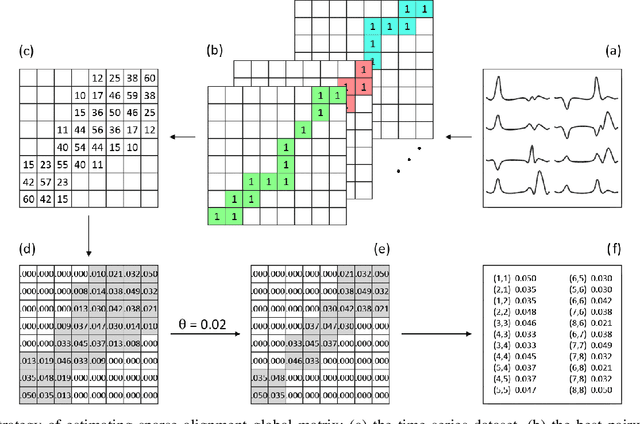
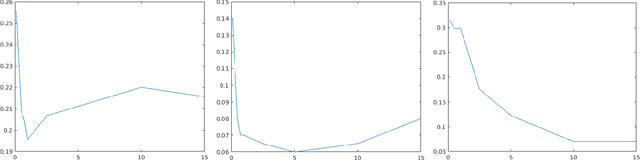
Temporal data are naturally everywhere, especially in the digital era that sees the advent of big data and internet of things. One major challenge that arises during temporal data analysis and mining is the comparison of time series or sequences, which requires to determine a proper distance or (dis)similarity measure. In this context, the Dynamic Time Warping (DTW) has enjoyed success in many domains, due to its 'temporal elasticity', a property particularly useful when matching temporal data. Unfortunately this dissimilarity measure suffers from a quadratic computational cost, which prohibits its use for large scale applications. This work addresses the sparsification of the alignment path search space for DTW-like measures, essentially to lower their computational cost without loosing on the quality of the measure. As a result of our sparsification approach, two new (dis)similarity measures, namely SP-DTW (Sparsified-Paths search space DTW) and its kernelization SP-K rdtw (Sparsified-Paths search space K rdtw kernel) are proposed for time series comparison. A wide range of public datasets is used to evaluate the efficiency (estimated in term of speed-up ratio and classification accuracy) of the proposed (dis)similarity measures on the 1-Nearest Neighbor (1-NN) and the Support Vector Machine (SVM) classification algorithms. Our experiment shows that our proposed measures provide a significant speed-up without loosing on accuracy. Furthermore, at the cost of a slight reduction of the speedup they significantly outperform on the accuracy criteria the old but well known Sakoe-Chiba approach that reduces the DTW path search space using a symmetric corridor.
Hybrid Isolation Forest - Application to Intrusion Detection
May 10, 2017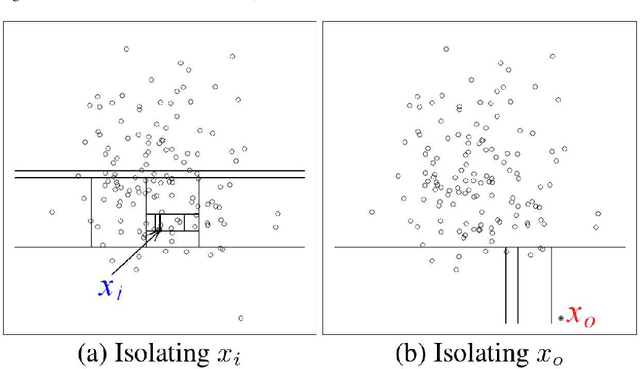
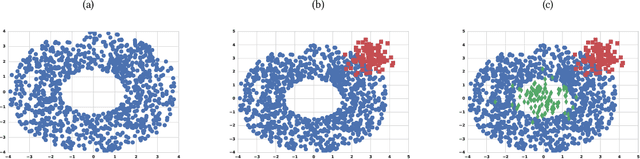
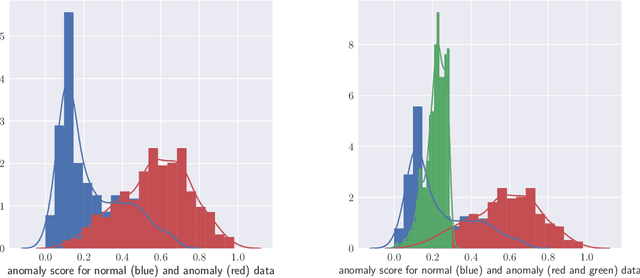
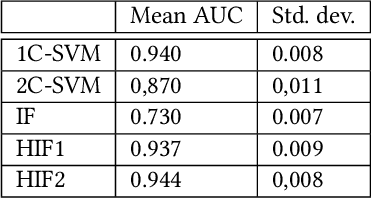
From the identification of a drawback in the Isolation Forest (IF) algorithm that limits its use in the scope of anomaly detection, we propose two extensions that allow to firstly overcome the previously mention limitation and secondly to provide it with some supervised learning capability. The resulting Hybrid Isolation Forest (HIF) that we propose is first evaluated on a synthetic dataset to analyze the effect of the new meta-parameters that are introduced and verify that the addressed limitation of the IF algorithm is effectively overcame. We hen compare the two algorithms on the ISCX benchmark dataset, in the context of a network intrusion detection application. Our experiments show that HIF outperforms IF, but also challenges the 1-class and 2-classes SVM baselines with computational efficiency.