 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-level SSL Feature Gating for Audio Deepfake Detection
Sep 03, 2025Recent advancements in generative AI, particularly in speech synthesis, have enabled the generation of highly natural-sounding synthetic speech that closely mimics human voices. While these innovations hold promise for applications like assistive technologies, they also pose significant risks, including misuse for fraudulent activities, identity theft, and security threats. Current research on spoofing detection countermeasures remains limited by generalization to unseen deepfake attacks and languages. To address this, we propose a gating mechanism extracting relevant feature from the speech foundation XLS-R model as a front-end feature extractor. For downstream back-end classifier, we employ Multi-kernel gated Convolution (MultiConv) to capture both local and global speech artifacts. Additionally, we introduce Centered Kernel Alignment (CKA) as a similarity metric to enforce diversity in learned features across different MultiConv layers. By integrating CKA with our gating mechanism, we hypothesize that each component helps improving the learning of distinct synthetic speech patterns. Experimental results demonstrate that our approach achieves state-of-the-art performance on in-domain benchmarks while generalizing robustly to out-of-domain datasets, including multilingual speech samples. This underscores its potential as a versatile solution for detecting evolving speech deepfake threats.
WikiNER-fr-gold: A Gold-Standard NER Corpus
Oct 29, 2024


We address in this article the the quality of the WikiNER corpus, a multilingual Named Entity Recognition corpus, and provide a consolidated version of it. The annotation of WikiNER was produced in a semi-supervised manner i.e. no manual verification has been carried out a posteriori. Such corpus is called silver-standard. In this paper we propose WikiNER-fr-gold which is a revised version of the French proportion of WikiNER. Our corpus consists of randomly sampled 20% of the original French sub-corpus (26,818 sentences with 700k tokens). We start by summarizing the entity types included in each category in order to define an annotation guideline, and then we proceed to revise the corpus. Finally we present an analysis of errors and inconsistency observed in the WikiNER-fr corpus, and we discuss potential future work directions.
Time Elastic Neural Networks
May 27, 2024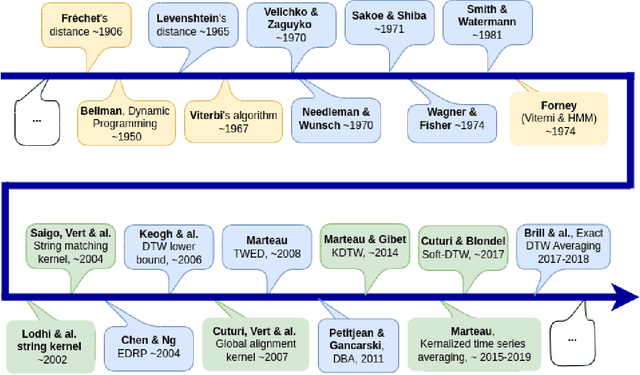

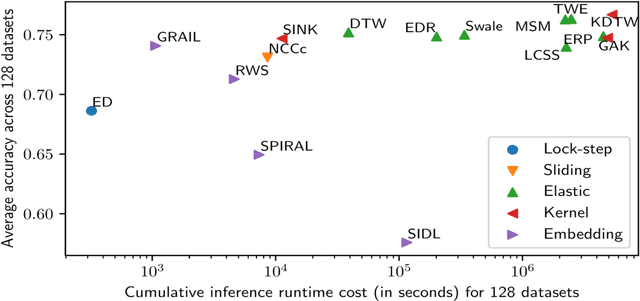
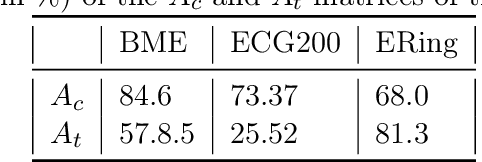
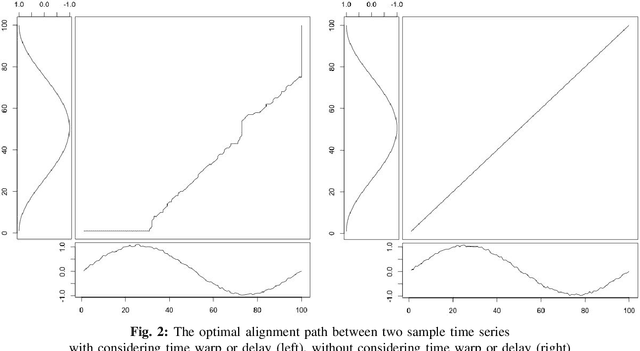
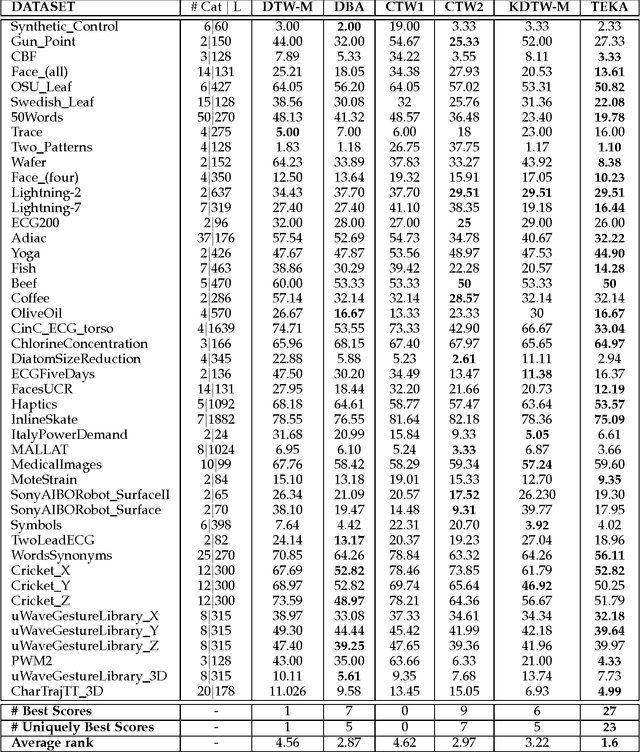
We introduce and detail an atypical neural network architecture, called time elastic neural network (teNN), for multivariate time series classification. The novelty compared to classical neural network architecture is that it explicitly incorporates time warping ability, as well as a new way of considering attention. In addition, this architecture is capable of learning a dropout strategy, thus optimizing its own architecture.Behind the design of this architecture, our overall objective is threefold: firstly, we are aiming at improving the accuracy of instance based classification approaches that shows quite good performances as far as enough training data is available. Secondly we seek to reduce the computational complexity inherent to these methods to improve their scalability. Ideally, we seek to find an acceptable balance between these first two criteria. And finally, we seek to enhance the explainability of the decision provided by this kind of neural architecture.The experiment demonstrates that the stochastic gradient descent implemented to train a teNN is quite effective. To the extent that the selection of some critical meta-parameters is correct, convergence is generally smooth and fast.While maintaining good accuracy, we get a drastic gain in scalability by first reducing the required number of reference time series, i.e. the number of teNN cells required. Secondly, we demonstrate that, during the training process, the teNN succeeds in reducing the number of neurons required within each cell. Finally, we show that the analysis of the activation and attention matrices as well as the reference time series after training provides relevant information to interpret and explain the classification results.The comparative study that we have carried out and which concerns around thirty diverse and multivariate datasets shows that the teNN obtains results comparable to those of the state of the art, in particular similar to those of a network mixing LSTM and CNN architectures for example.
Open challenges for Machine Learning based Early Decision-Making research
Apr 27, 2022
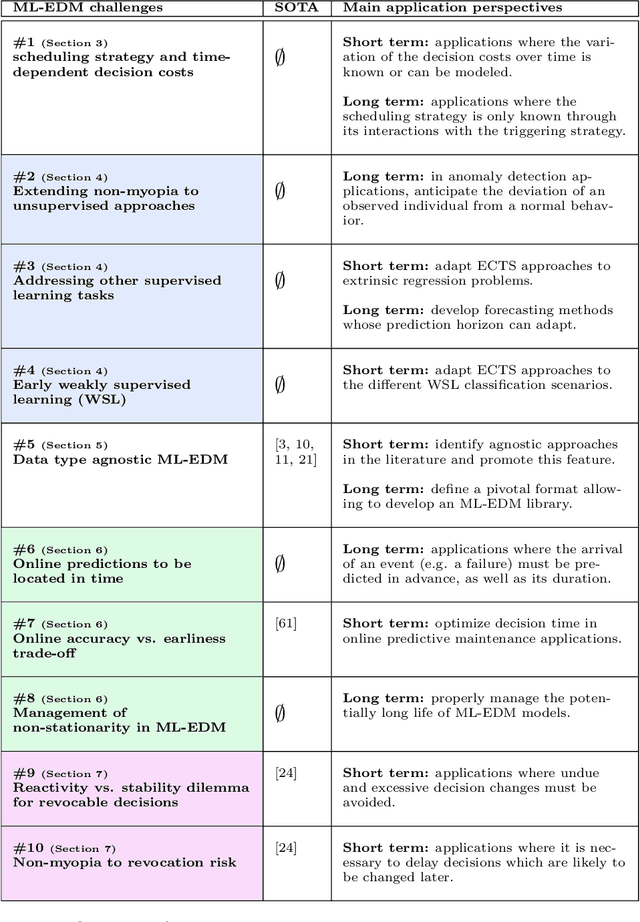
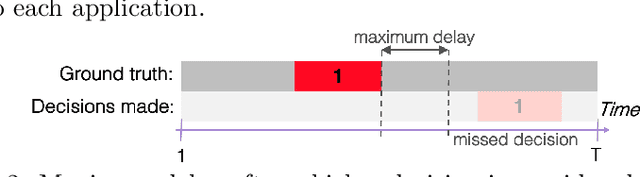
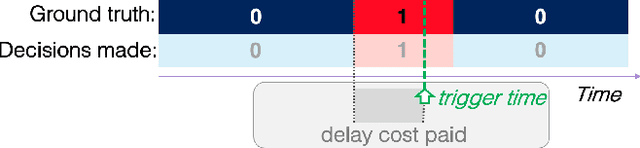
More and more applications require early decisions, i.e. taken as soon as possible from partially observed data. However, the later a decision is made, the more its accuracy tends to improve, since the description of the problem to hand is enriched over time. Such a compromise between the earliness and the accuracy of decisions has been particularly studied in the field of Early Time Series Classification. This paper introduces a more general problem, called Machine Learning based Early Decision Making (ML-EDM), which consists in optimizing the decision times of models in a wide range of settings where data is collected over time. After defining the ML-EDM problem, ten challenges are identified and proposed to the scientific community to further research in this area. These challenges open important application perspectives, discussed in this paper.
Sparsification of the Alignment Path Search Space in Dynamic Time Warping
Nov 13, 2017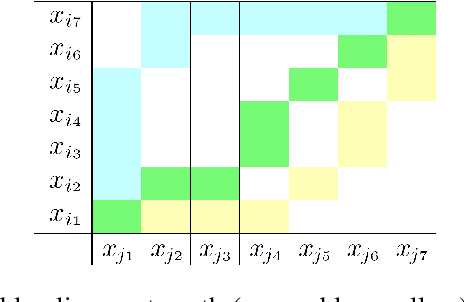
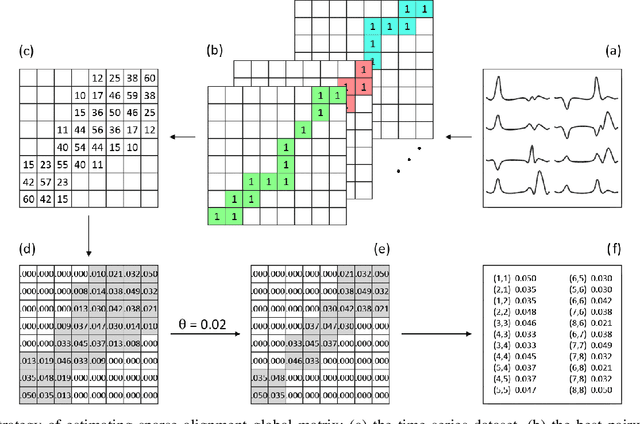
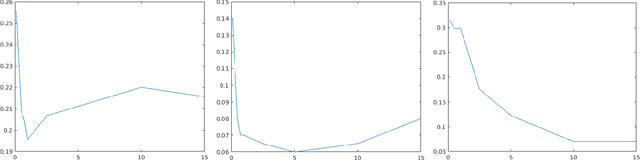
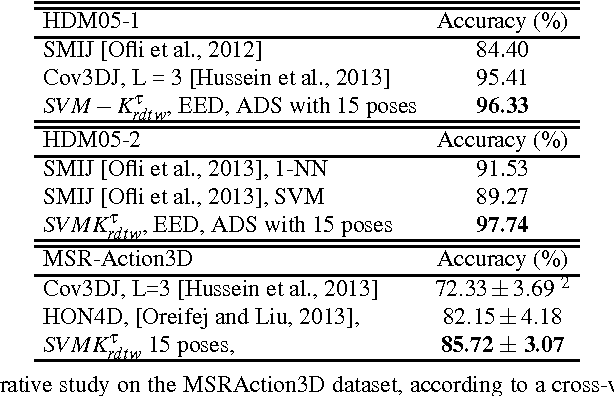
Temporal data are naturally everywhere, especially in the digital era that sees the advent of big data and internet of things. One major challenge that arises during temporal data analysis and mining is the comparison of time series or sequences, which requires to determine a proper distance or (dis)similarity measure. In this context, the Dynamic Time Warping (DTW) has enjoyed success in many domains, due to its 'temporal elasticity', a property particularly useful when matching temporal data. Unfortunately this dissimilarity measure suffers from a quadratic computational cost, which prohibits its use for large scale applications. This work addresses the sparsification of the alignment path search space for DTW-like measures, essentially to lower their computational cost without loosing on the quality of the measure. As a result of our sparsification approach, two new (dis)similarity measures, namely SP-DTW (Sparsified-Paths search space DTW) and its kernelization SP-K rdtw (Sparsified-Paths search space K rdtw kernel) are proposed for time series comparison. A wide range of public datasets is used to evaluate the efficiency (estimated in term of speed-up ratio and classification accuracy) of the proposed (dis)similarity measures on the 1-Nearest Neighbor (1-NN) and the Support Vector Machine (SVM) classification algorithms. Our experiment shows that our proposed measures provide a significant speed-up without loosing on accuracy. Furthermore, at the cost of a slight reduction of the speedup they significantly outperform on the accuracy criteria the old but well known Sakoe-Chiba approach that reduces the DTW path search space using a symmetric corridor.
Hybrid Isolation Forest - Application to Intrusion Detection
May 10, 2017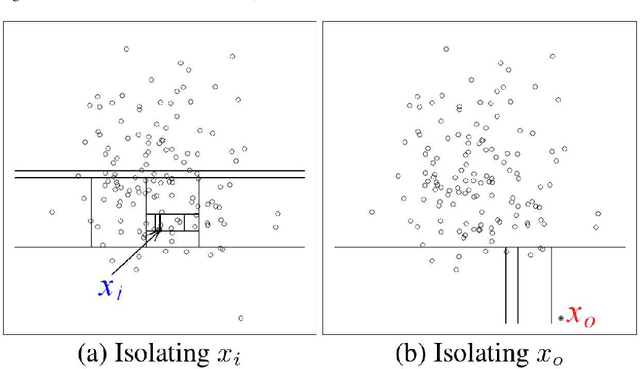
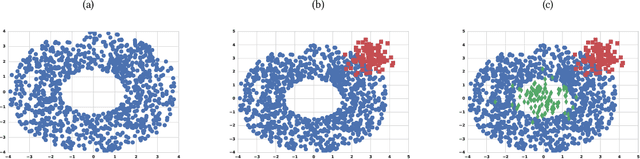
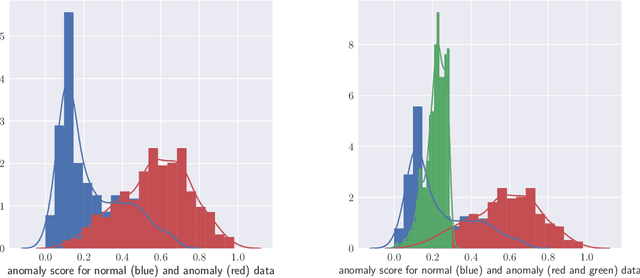
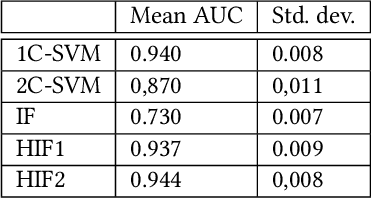
From the identification of a drawback in the Isolation Forest (IF) algorithm that limits its use in the scope of anomaly detection, we propose two extensions that allow to firstly overcome the previously mention limitation and secondly to provide it with some supervised learning capability. The resulting Hybrid Isolation Forest (HIF) that we propose is first evaluated on a synthetic dataset to analyze the effect of the new meta-parameters that are introduced and verify that the addressed limitation of the IF algorithm is effectively overcame. We hen compare the two algorithms on the ISCX benchmark dataset, in the context of a network intrusion detection application. Our experiments show that HIF outperforms IF, but also challenges the 1-class and 2-classes SVM baselines with computational efficiency.
Times series averaging and denoising from a probabilistic perspective on time-elastic kernels
Apr 24, 2017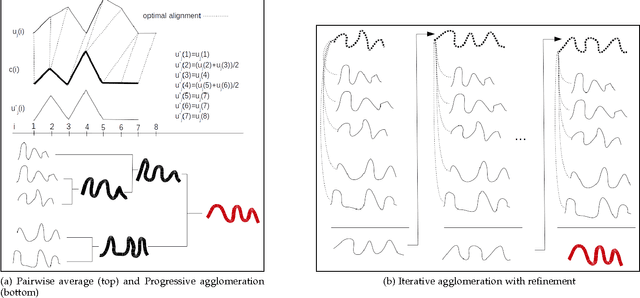
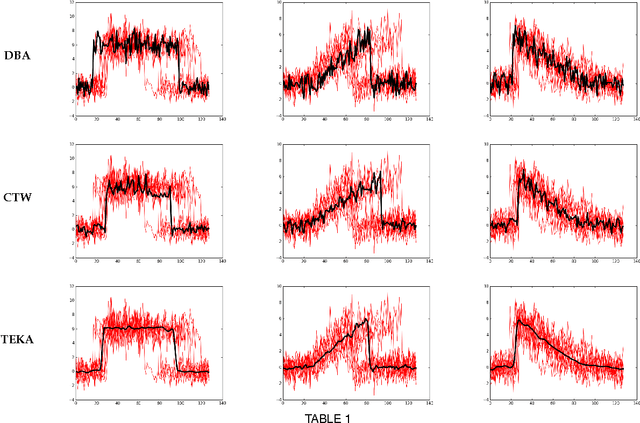
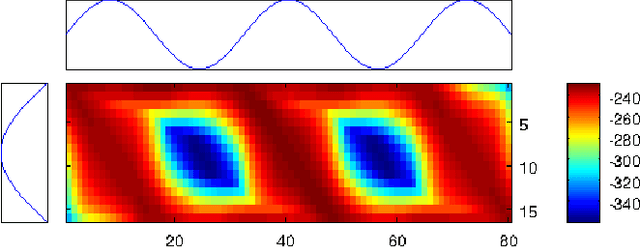
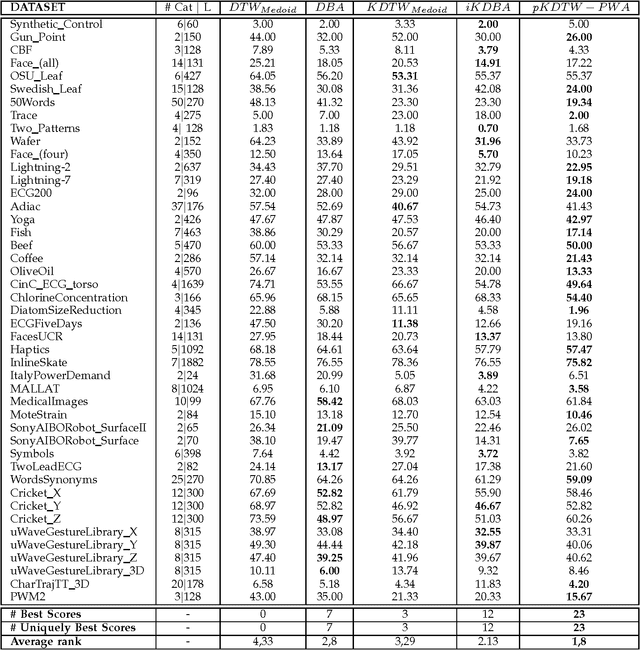
In the light of regularized dynamic time warping kernels, this paper re-considers the concept of time elastic centroid for a setof time series. We derive a new algorithm based on a probabilistic interpretation of kernel alignment matrices. This algorithm expressesthe averaging process in terms of a stochastic alignment automata. It uses an iterative agglomerative heuristic method for averagingthe aligned samples, while also averaging the times of occurrence of the aligned samples. By comparing classification accuracies for45 heterogeneous time series datasets obtained by first nearest centroid/medoid classifiers we show that: i) centroid-basedapproaches significantly outperform medoid-based approaches, ii) for the considered datasets, our algorithm that combines averagingin the sample space and along the time axes, emerges as the most significantly robust model for time-elastic averaging with apromising noise reduction capability. We also demonstrate its benefit in an isolated gesture recognition experiment and its ability tosignificantly reduce the size of training instance sets. Finally we highlight its denoising capability using demonstrative synthetic data:we show that it is possible to retrieve, from few noisy instances, a signal whose components are scattered in a wide spectral band.
Adaptive Down-Sampling and Dimension Reduction in Time Elastic Kernel Machines for Efficient Recognition of Isolated Gestures
Nov 23, 2016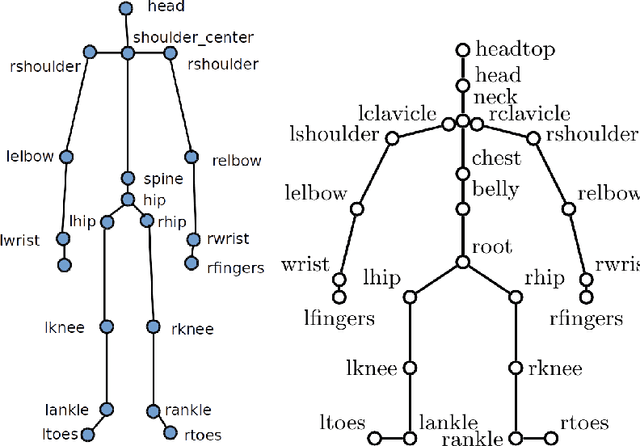
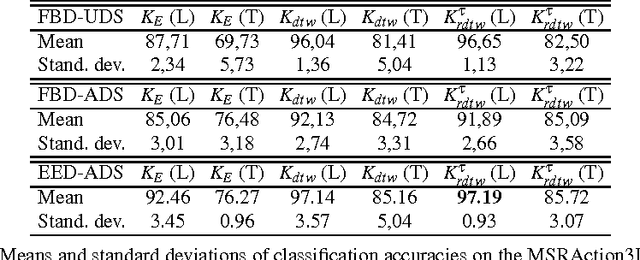
In the scope of gestural action recognition, the size of the feature vector representing movements is in general quite large especially when full body movements are considered. Furthermore, this feature vector evolves during the movement performance so that a complete movement is fully represented by a matrix M of size DxT , whose element M i, j represents the value of feature i at timestamps j. Many studies have addressed dimensionality reduction considering only the size of the feature vector lying in R D to reduce both the variability of gestural sequences expressed in the reduced space, and the computational complexity of their processing. In return, very few of these methods have explicitly addressed the dimensionality reduction along the time axis. Yet this is a major issue when considering the use of elastic distances which are characterized by a quadratic complexity along the time axis. We present in this paper an evaluation of straightforward approaches aiming at reducing the dimensionality of the matrix M for each movement, leading to consider both the dimensionality reduction of the feature vector as well as its reduction along the time axis. The dimensionality reduction of the feature vector is achieved by selecting remarkable joints in the skeleton performing the movement, basically the extremities of the articulatory chains composing the skeleton. The temporal dimen-sionality reduction is achieved using either a regular or adaptive down-sampling that seeks to minimize the reconstruction error of the movements. Elastic and Euclidean kernels are then compared through support vector machine learning. Two data sets 1 that are widely referenced in the domain of human gesture recognition, and quite distinctive in terms of quality of motion capture, are used for the experimental assessment of the proposed approaches. On these data sets we experimentally show that it is feasible, and possibly desirable, to significantly reduce simultaneously the size of the feature vector and the number of skeleton frames to represent body movements while maintaining a very good recognition rate. The method proves to give satisfactory results at a level currently reached by state-of-the-art methods on these data sets. We experimentally show that the computational complexity reduction that is obtained makes this approach eligible for real-time applications.
Times series averaging from a probabilistic interpretation of time-elastic kernel
Jun 09, 2015
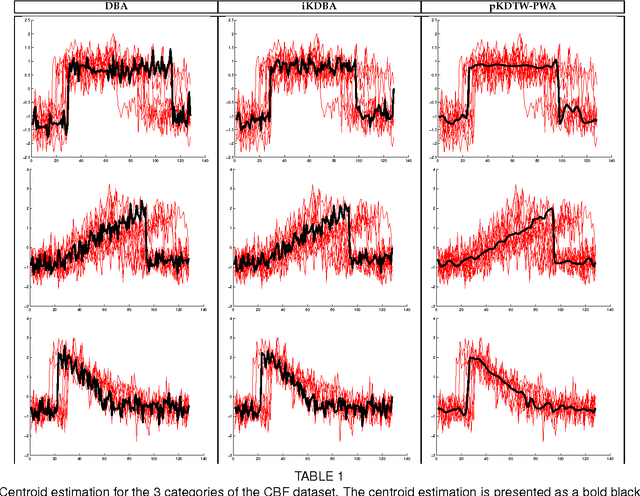
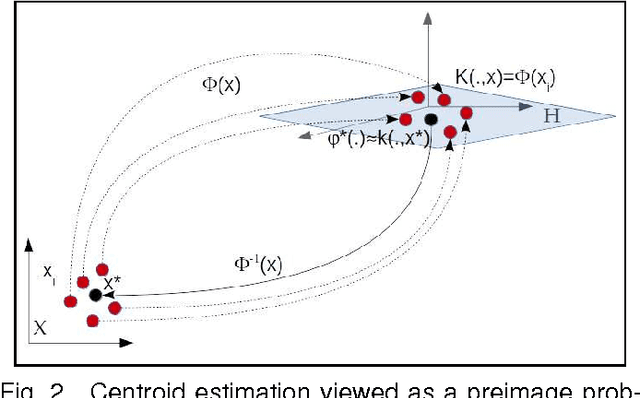
At the light of regularized dynamic time warping kernels, this paper reconsider the concept of time elastic centroid (TEC) for a set of time series. From this perspective, we show first how TEC can easily be addressed as a preimage problem. Unfortunately this preimage problem is ill-posed, may suffer from over-fitting especially for long time series and getting a sub-optimal solution involves heavy computational costs. We then derive two new algorithms based on a probabilistic interpretation of kernel alignment matrices that expresses in terms of probabilistic distributions over sets of alignment paths. The first algorithm is an iterative agglomerative heuristics inspired from the state of the art DTW barycenter averaging (DBA) algorithm proposed specifically for the Dynamic Time Warping measure. The second proposed algorithm achieves a classical averaging of the aligned samples but also implements an averaging of the time of occurrences of the aligned samples. It exploits a straightforward progressive agglomerative heuristics. An experimentation that compares for 45 time series datasets classification error rates obtained by first near neighbors classifiers exploiting a single medoid or centroid estimate to represent each categories show that: i) centroids based approaches significantly outperform medoids based approaches, ii) on the considered experience, the two proposed algorithms outperform the state of the art DBA algorithm, and iii) the second proposed algorithm that implements an averaging jointly in the sample space and along the time axes emerges as the most significantly robust time elastic averaging heuristic with an interesting noise reduction capability. Index Terms-Time series averaging Time elastic kernel Dynamic Time Warping Time series clustering and classification.
Exploiting a comparability mapping to improve bi-lingual data categorization: a three-mode data analysis perspective
Feb 26, 2015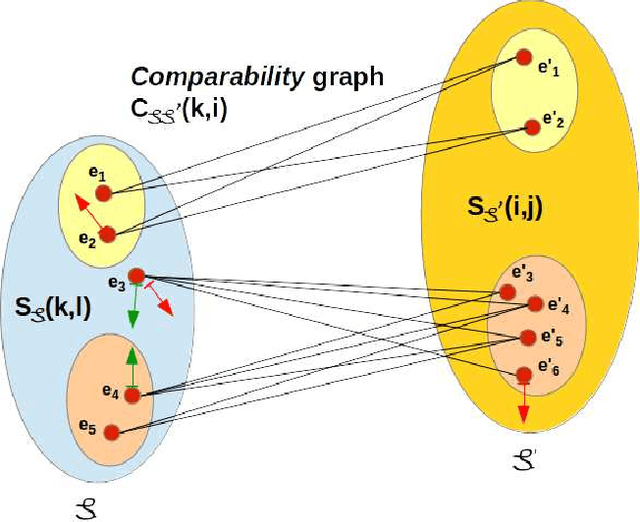
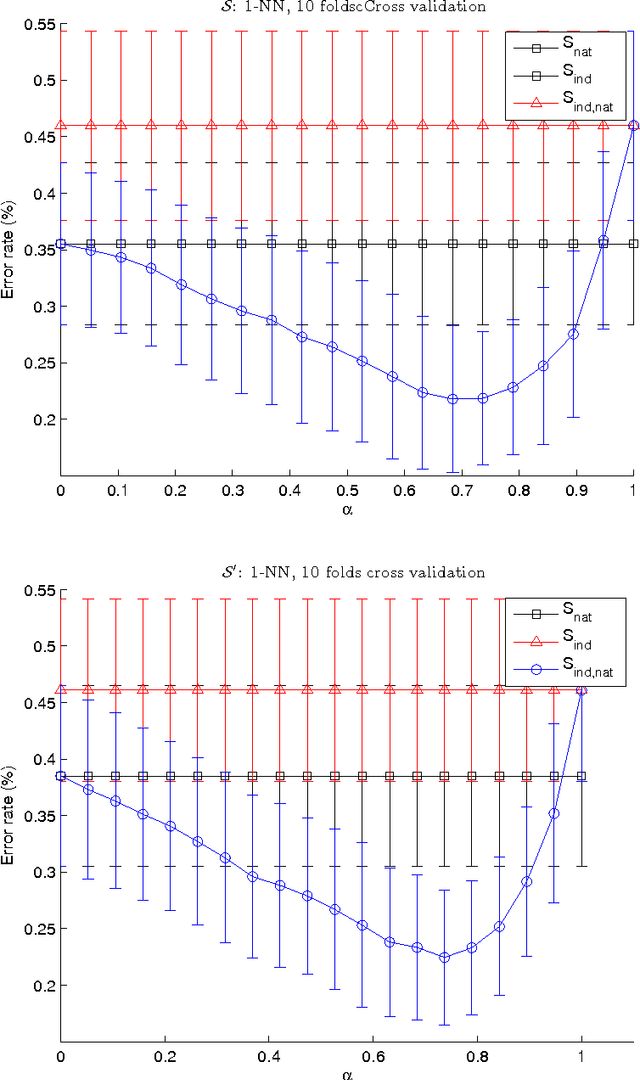
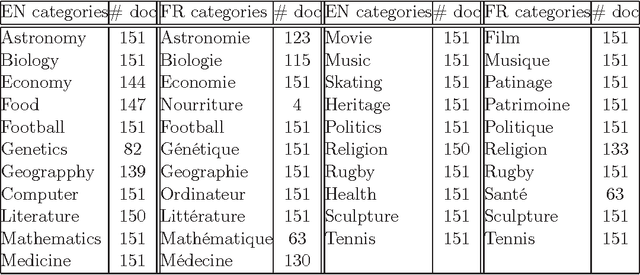
We address in this paper the co-clustering and co-classification of bilingual data laying in two linguistic similarity spaces when a comparability measure defining a mapping between these two spaces is available. A new approach that we can characterized as a three-mode analysis scheme, is proposed to mix the comparability measure with the two similarity measures. Our aim is to improve jointly the accuracy of classification and clustering tasks performed in each of the two linguistic spaces, as well as the quality of the final alignment of comparable clusters that can be obtained. We used first some purely synthetic random data sets to assess our formal similarity-comparability mixing model. We then propose two variants of the comparability measure that has been defined by (Li and Gaussier 2010) in the context of bilingual lexicon extraction to adapt it to clustering or categorizing tasks. These two variant measures are subsequently used to evaluate our similarity-comparability mixing model in the context of the co-classification and co-clustering of comparable textual data sets collected from Wikipedia categories for the English and French languages. Our experiments show clear improvements in clustering and classification accuracies when mixing comparability with similarity measures, with, as expected, a higher robustness obtained when the two comparability variant measures that we propose are used. We believe that this approach is particularly well suited for the construction of thematic comparable corpora of controllable quality.