 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Rules for Online Failure Prediction: A Case Study on the Metro do Porto dataset
Feb 11, 2025Due to their high predictive performance, predictive maintenance applications have increasingly been approached with Deep Learning techniques in recent years. However, as in other real-world application scenarios, the need for explainability is often stated but not sufficiently addressed. This study will focus on predicting failures on Metro trains in Porto, Portugal. While recent works have found high-performing deep neural network architectures that feature a parallel explainability pipeline, the generated explanations are fairly complicated and need help explaining why the failures are happening. This work proposes a simple online rule-based explainability approach with interpretable features that leads to straightforward, interpretable rules. We showcase our approach on MetroPT2 and find that three specific sensors on the Metro do Porto trains suffice to predict the failures present in the dataset with simple rules.
Histogram approaches for imbalanced data streams regression
Jan 29, 2025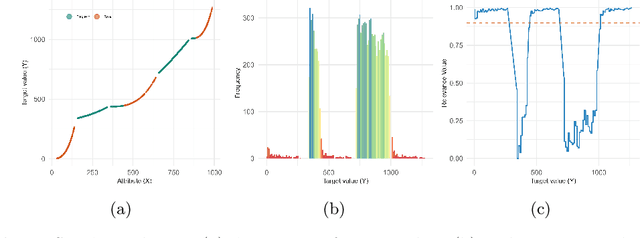
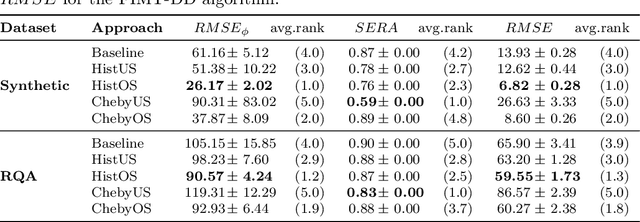
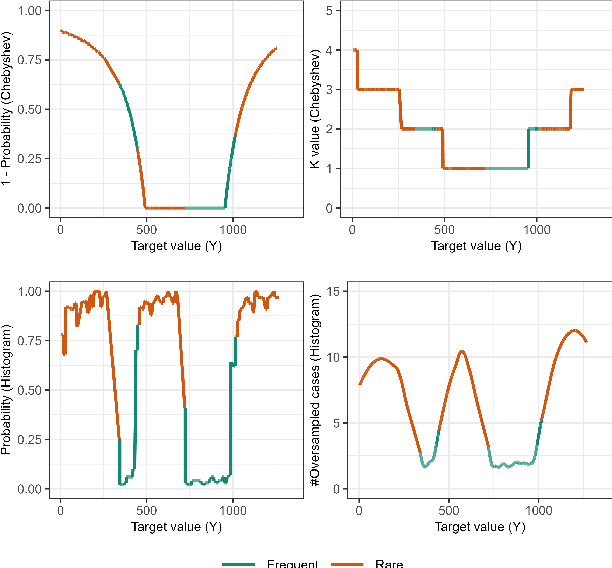
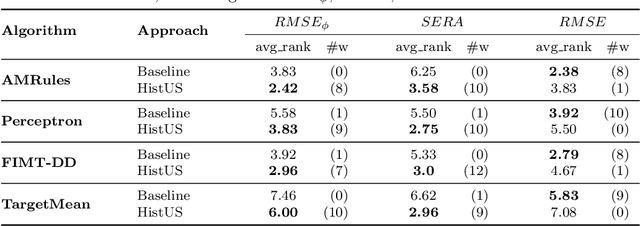
Handling imbalanced data streams in regression tasks presents a significant challenge, as rare instances can appear anywhere in the target distribution rather than being confined to its extreme values. In this paper, we introduce novel data-level sampling strategies, \texttt{HistUS} and \texttt{HistOS}, that utilize histogram-based approaches to dynamically balance data streams. Unlike previous methods based on Chebyshev\textquotesingle s inequality, our proposed techniques identify and handle rare cases across the entire distribution effectively. We demonstrate that \texttt{HistUS} and \texttt{HistOS} outperform traditional methods through extensive experiments on synthetic and real-world datasets, leading to more accurate and robust regression models in streaming environments.
Bayesian Federated Learning: A Survey
Apr 26, 2023Federated learning (FL) demonstrates its advantages in integrating distributed infrastructure, communication, computing and learning in a privacy-preserving manner. However, the robustness and capabilities of existing FL methods are challenged by limited and dynamic data and conditions, complexities including heterogeneities and uncertainties, and analytical explainability. Bayesian federated learning (BFL) has emerged as a promising approach to address these issues. This survey presents a critical overview of BFL, including its basic concepts, its relations to Bayesian learning in the context of FL, and a taxonomy of BFL from both Bayesian and federated perspectives. We categorize and discuss client- and server-side and FL-based BFL methods and their pros and cons. The limitations of the existing BFL methods and the future directions of BFL research further address the intricate requirements of real-life FL applications.
Modeling Events and Interactions through Temporal Processes -- A Survey
Mar 10, 2023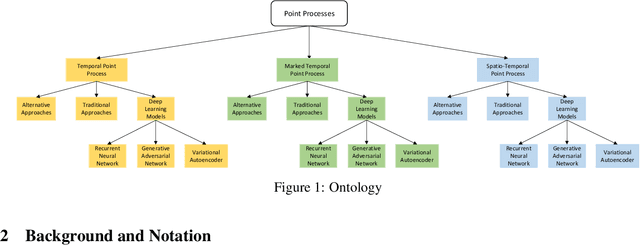
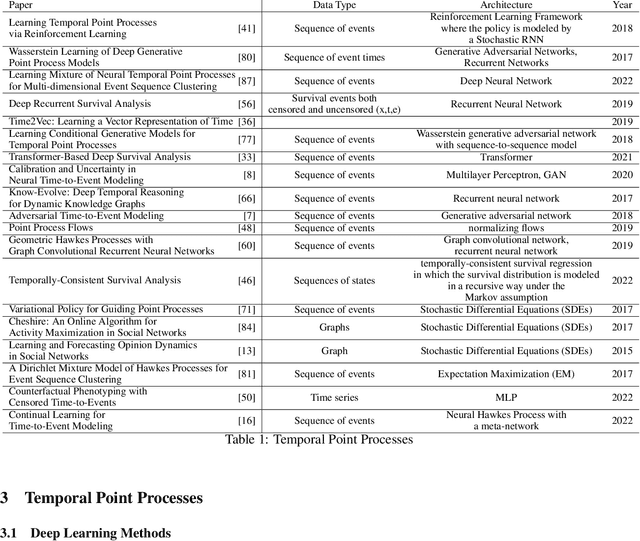
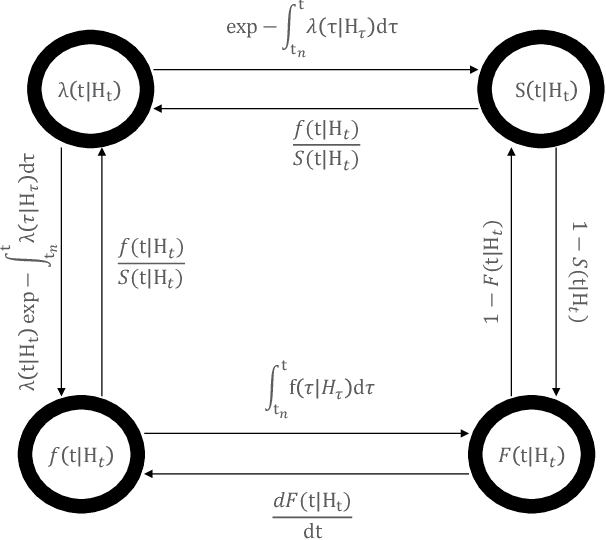
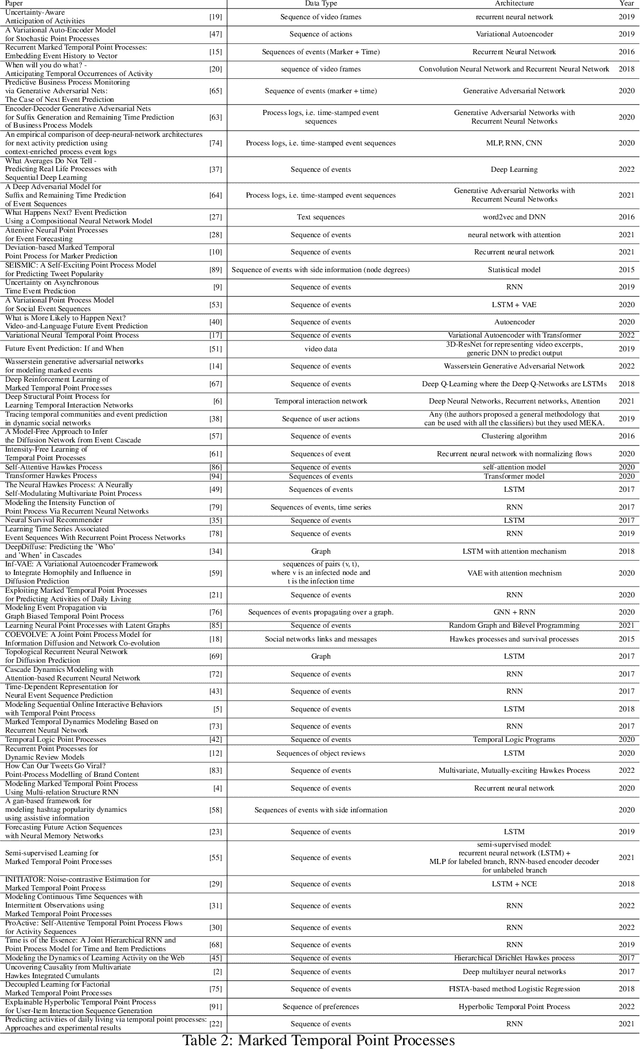
In real-world scenario, many phenomena produce a collection of events that occur in continuous time. Point Processes provide a natural mathematical framework for modeling these sequences of events. In this survey, we investigate probabilistic models for modeling event sequences through temporal processes. We revise the notion of event modeling and provide the mathematical foundations that characterize the literature on the topic. We define an ontology to categorize the existing approaches in terms of three families: simple, marked, and spatio-temporal point processes. For each family, we systematically review the existing approaches based based on deep learning. Finally, we analyze the scenarios where the proposed techniques can be used for addressing prediction and modeling aspects.
Open challenges for Machine Learning based Early Decision-Making research
Apr 27, 2022
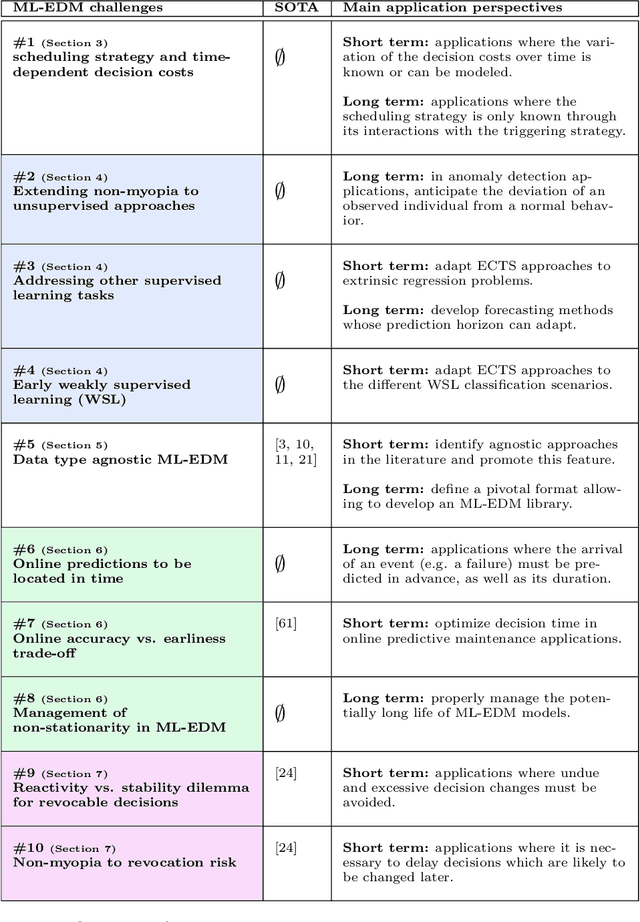
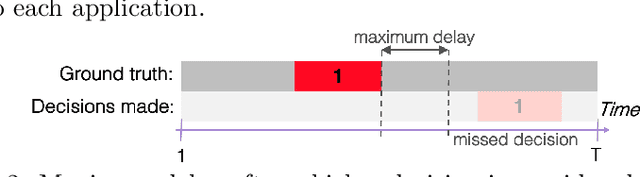
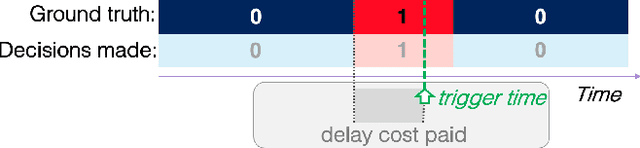
More and more applications require early decisions, i.e. taken as soon as possible from partially observed data. However, the later a decision is made, the more its accuracy tends to improve, since the description of the problem to hand is enriched over time. Such a compromise between the earliness and the accuracy of decisions has been particularly studied in the field of Early Time Series Classification. This paper introduces a more general problem, called Machine Learning based Early Decision Making (ML-EDM), which consists in optimizing the decision times of models in a wide range of settings where data is collected over time. After defining the ML-EDM problem, ten challenges are identified and proposed to the scientific community to further research in this area. These challenges open important application perspectives, discussed in this paper.
Learning under Concept Drift: A Review
Apr 13, 2020
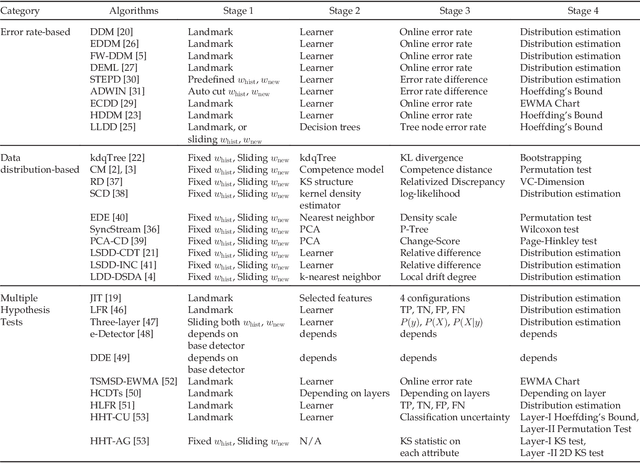
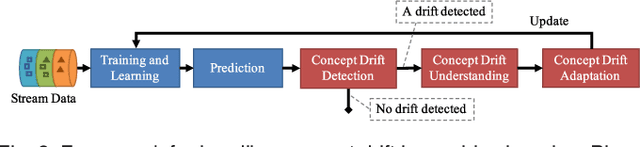
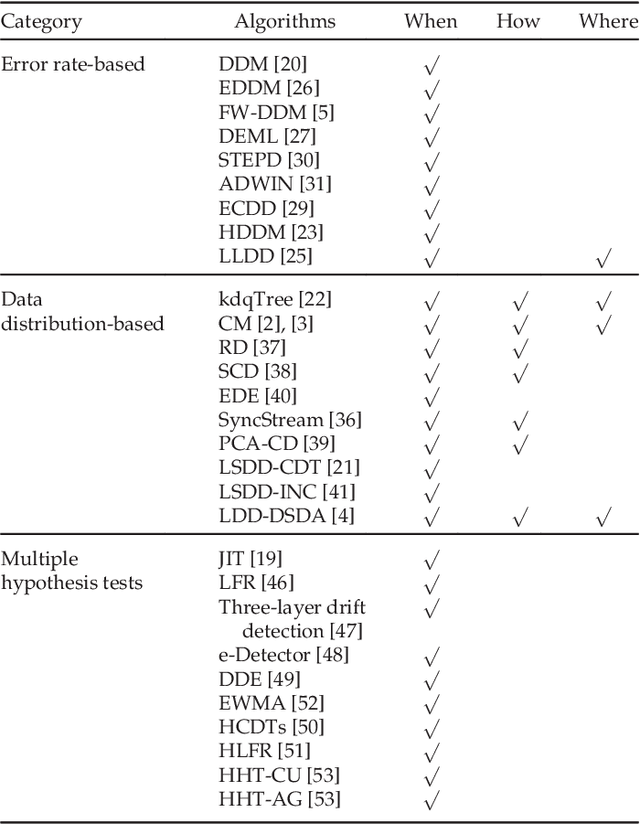
Concept drift describes unforeseeable changes in the underlying distribution of streaming data over time. Concept drift research involves the development of methodologies and techniques for drift detection, understanding and adaptation. Data analysis has revealed that machine learning in a concept drift environment will result in poor learning results if the drift is not addressed. To help researchers identify which research topics are significant and how to apply related techniques in data analysis tasks, it is necessary that a high quality, instructive review of current research developments and trends in the concept drift field is conducted. In addition, due to the rapid development of concept drift in recent years, the methodologies of learning under concept drift have become noticeably systematic, unveiling a framework which has not been mentioned in literature. This paper reviews over 130 high quality publications in concept drift related research areas, analyzes up-to-date developments in methodologies and techniques, and establishes a framework of learning under concept drift including three main components: concept drift detection, concept drift understanding, and concept drift adaptation. This paper lists and discusses 10 popular synthetic datasets and 14 publicly available benchmark datasets used for evaluating the performance of learning algorithms aiming at handling concept drift. Also, concept drift related research directions are covered and discussed. By providing state-of-the-art knowledge, this survey will directly support researchers in their understanding of research developments in the field of learning under concept drift.
SimTensor: A synthetic tensor data generator
Dec 09, 2016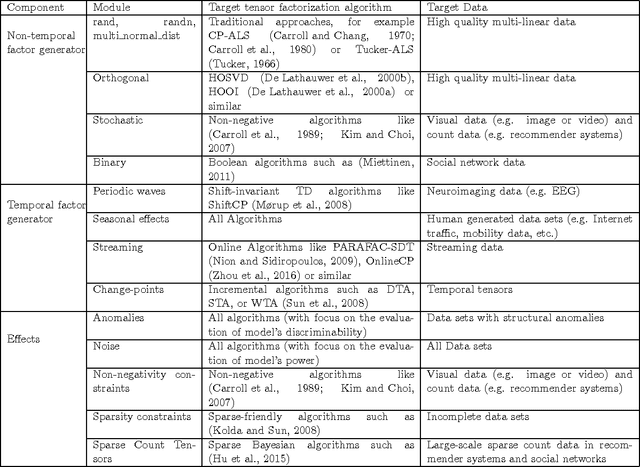
SimTensor is a multi-platform, open-source software for generating artificial tensor data (either with CP/PARAFAC or Tucker structure) for reproducible research on tensor factorization algorithms. SimTensor is a stand-alone application based on MATALB. It provides a wide range of facilities for generating tensor data with various configurations. It comes with a user-friendly graphical user interface, which enables the user to generate tensors with complicated settings in an easy way. It also has this facility to export generated data to universal formats such as CSV and HDF5, which can be imported via a wide range of programming languages (C, C++, Java, R, Fortran, MATLAB, Perl, Python, and many more). The most innovative part of SimTensor is this that can generate temporal tensors with periodic waves, seasonal effects and streaming structure. it can apply constraints such as non-negativity and different kinds of sparsity to the data. SimTensor also provides this facility to simulate different kinds of change-points and inject various types of anomalies. The source code and binary versions of SimTensor is available for download in http://www.simtensor.org.
An eigenvector-based hotspot detection
Jun 13, 2014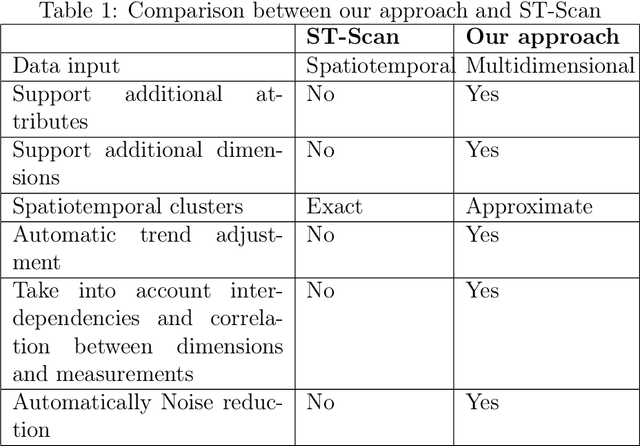

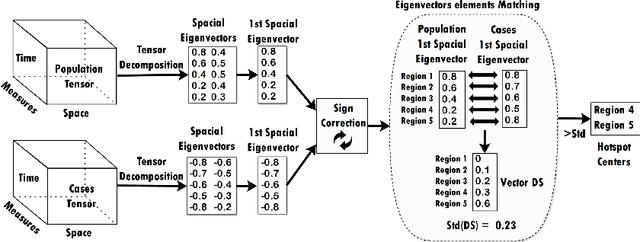

Space and time are two critical components of many real world systems. For this reason, analysis of anomalies in spatiotemporal data has been a great of interest. In this work, application of tensor decomposition and eigenspace techniques on spatiotemporal hotspot detection is investigated. An algorithm called SST-Hotspot is proposed which accounts for spatiotemporal variations in data and detect hotspots using matching of eigenvector elements of two cases and population tensors. The experimental results reveal the interesting application of tensor decomposition and eigenvector-based techniques in hotspot analysis.