 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt Segmentation and Annotation Optimisation: Controlling LLM Behaviour via Optimised Segment-Level Annotations
May 14, 2026Prompt engineering is crucial for effective interaction with generative artificial intelligence systems, yet existing optimisation methods often operate over an unstructured and vast prompt space, leading to high computational costs and potential distortions of the original intent. We introduce Prompt Segmentation and Annotation Optimisation (PSAO), a structured prompt optimisation framework designed to improve prompt optimisation controllability and efficiency. PSAO decomposes a prompt into interpretable segments (e.g., sentences) and augments each with human-readable annotations (e.g., {not important}, {important}, {very important}). These annotations guide large language models (LLMs) in allocating focus and clarifying confusion during response generation. We formally define the segmentations and annotations and demonstrate that optimised segment-level annotations can lead to improved LLM responses, with the original prompt retained as a candidate in the optimisation space to prevent performance degradation. Empirical evaluations indicate that PSAO benefits from annotations in terms of improved reasoning accuracy and self-consistency. However, developing efficient methods for identifying optimal segmentations and annotations remains challenging and is reserved for future investigation. This work is intended as a proof of concept, demonstrating the feasibility and potential of segment-level annotation optimisation.
SPAD: Seven-Source Token Probability Attribution with Syntactic Aggregation for Detecting Hallucinations in RAG
Dec 08, 2025Detecting hallucinations in Retrieval-Augmented Generation (RAG) remains a challenge. Prior approaches attribute hallucinations to a binary conflict between internal knowledge (stored in FFNs) and retrieved context. However, this perspective is incomplete, failing to account for the impact of other components in the generative process, such as the user query, previously generated tokens, the current token itself, and the final LayerNorm adjustment. To address this, we introduce SPAD. First, we mathematically attribute each token's probability into seven distinct sources: Query, RAG, Past, Current Token, FFN, Final LayerNorm, and Initial Embedding. This attribution quantifies how each source contributes to the generation of the current token. Then, we aggregate these scores by POS tags to quantify how different components drive specific linguistic categories. By identifying anomalies, such as Nouns relying on Final LayerNorm, SPAD effectively detects hallucinations. Extensive experiments demonstrate that SPAD achieves state-of-the-art performance
Autonomous Concept Drift Threshold Determination
Nov 13, 2025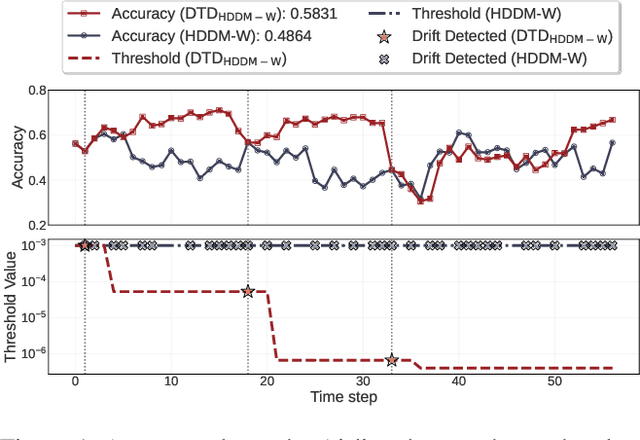
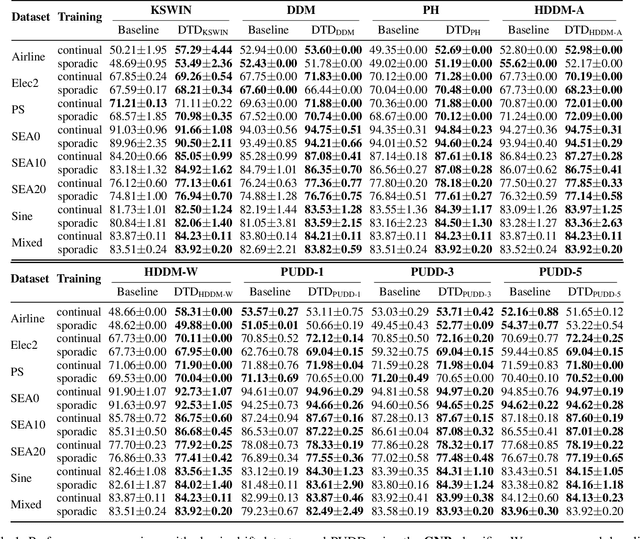
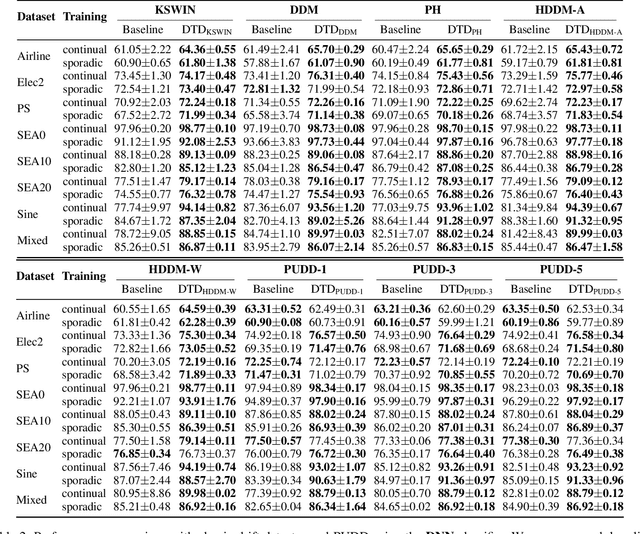
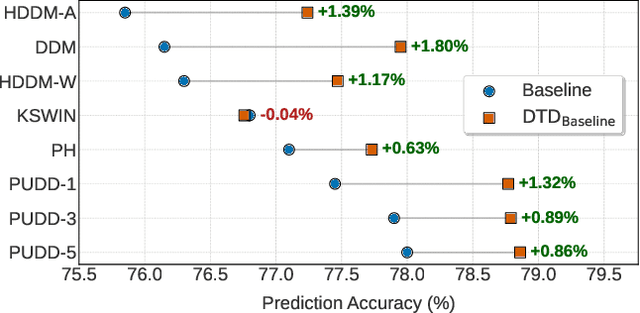
Existing drift detection methods focus on designing sensitive test statistics. They treat the detection threshold as a fixed hyperparameter, set once to balance false alarms and late detections, and applied uniformly across all datasets and over time. However, maintaining model performance is the key objective from the perspective of machine learning, and we observe that model performance is highly sensitive to this threshold. This observation inspires us to investigate whether a dynamic threshold could be provably better. In this paper, we prove that a threshold that adapts over time can outperform any single fixed threshold. The main idea of the proof is that a dynamic strategy, constructed by combining the best threshold from each individual data segment, is guaranteed to outperform any single threshold that apply to all segments. Based on the theorem, we propose a Dynamic Threshold Determination algorithm. It enhances existing drift detection frameworks with a novel comparison phase to inform how the threshold should be adjusted. Extensive experiments on a wide range of synthetic and real-world datasets, including both image and tabular data, validate that our approach substantially enhances the performance of state-of-the-art drift detectors.
Early Concept Drift Detection via Prediction Uncertainty
Dec 15, 2024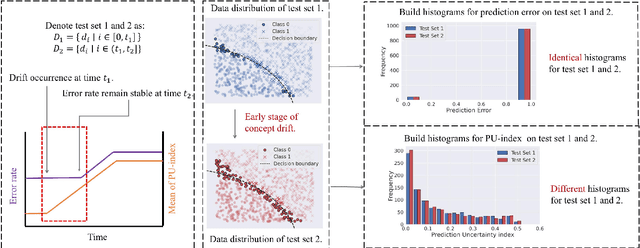
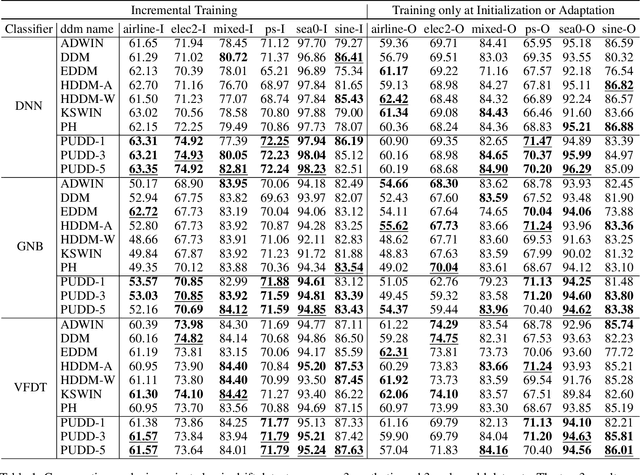
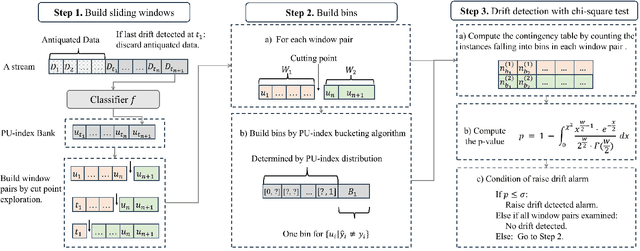
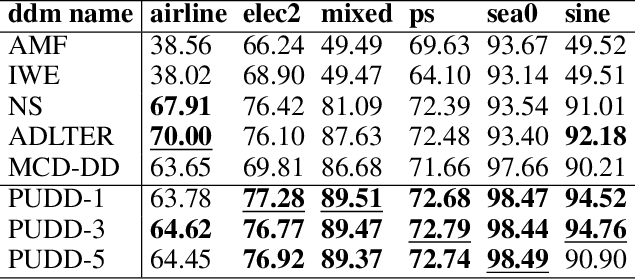
Concept drift, characterized by unpredictable changes in data distribution over time, poses significant challenges to machine learning models in streaming data scenarios. Although error rate-based concept drift detectors are widely used, they often fail to identify drift in the early stages when the data distribution changes but error rates remain constant. This paper introduces the Prediction Uncertainty Index (PU-index), derived from the prediction uncertainty of the classifier, as a superior alternative to the error rate for drift detection. Our theoretical analysis demonstrates that: (1) The PU-index can detect drift even when error rates remain stable. (2) Any change in the error rate will lead to a corresponding change in the PU-index. These properties make the PU-index a more sensitive and robust indicator for drift detection compared to existing methods. We also propose a PU-index-based Drift Detector (PUDD) that employs a novel Adaptive PU-index Bucketing algorithm for detecting drift. Empirical evaluations on both synthetic and real-world datasets demonstrate PUDD's efficacy in detecting drift in structured and image data.
Learning Bounds for Open-Set Learning
Jun 30, 2021
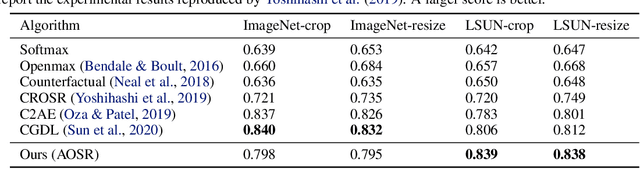

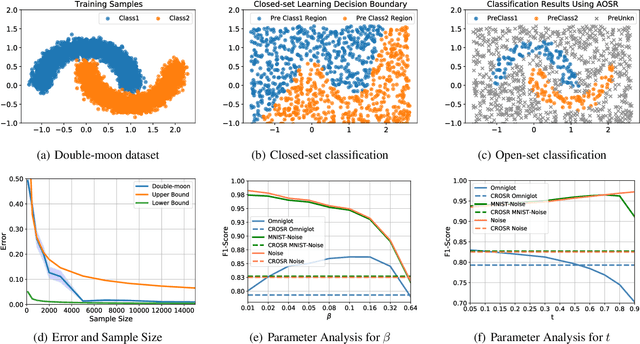
Traditional supervised learning aims to train a classifier in the closed-set world, where training and test samples share the same label space. In this paper, we target a more challenging and realistic setting: open-set learning (OSL), where there exist test samples from the classes that are unseen during training. Although researchers have designed many methods from the algorithmic perspectives, there are few methods that provide generalization guarantees on their ability to achieve consistent performance on different training samples drawn from the same distribution. Motivated by the transfer learning and probably approximate correct (PAC) theory, we make a bold attempt to study OSL by proving its generalization error-given training samples with size n, the estimation error will get close to order O_p(1/\sqrt{n}). This is the first study to provide a generalization bound for OSL, which we do by theoretically investigating the risk of the target classifier on unknown classes. According to our theory, a novel algorithm, called auxiliary open-set risk (AOSR) is proposed to address the OSL problem. Experiments verify the efficacy of AOSR. The code is available at github.com/Anjin-Liu/Openset_Learning_AOSR.
Concept Drift Detection: Dealing with MissingValues via Fuzzy Distance Estimations
Aug 09, 2020In data streams, the data distribution of arriving observations at different time points may change - a phenomenon called concept drift. While detecting concept drift is a relatively mature area of study, solutions to the uncertainty introduced by observations with missing values have only been studied in isolation. No one has yet explored whether or how these solutions might impact drift detection performance. We, however, believe that data imputation methods may actually increase uncertainty in the data rather than reducing it. We also conjecture that imputation can introduce bias into the process of estimating distribution changes during drift detection, which can make it more difficult to train a learning model. Our idea is to focus on estimating the distance between observations rather than estimating the missing values, and to define membership functions that allocate observations to histogram bins according to the estimation errors. Our solution comprises a novel masked distance learning (MDL) algorithm to reduce the cumulative errors caused by iteratively estimating each missing value in an observation and a fuzzy-weighted frequency (FWF) method for identifying discrepancies in the data distribution. The concept drift detection algorithm proposed in this paper is a singular and unified algorithm that can handle missing values, but not an imputation algorithm combined with a concept drift detection algorithm. Experiments on both synthetic and real-world data sets demonstrate the advantages of this method and show its robustness in detecting drift in data with missing values. These findings reveal that missing values exert a profound impact on concept drift detection, but using fuzzy set theory to model observations can produce more reliable results than imputation.
Diverse Instances-Weighting Ensemble based on Region Drift Disagreement for Concept Drift Adaptation
Apr 13, 2020



Concept drift refers to changes in the distribution of underlying data and is an inherent property of evolving data streams. Ensemble learning, with dynamic classifiers, has proved to be an efficient method of handling concept drift. However, the best way to create and maintain ensemble diversity with evolving streams is still a challenging problem. In contrast to estimating diversity via inputs, outputs, or classifier parameters, we propose a diversity measurement based on whether the ensemble members agree on the probability of a regional distribution change. In our method, estimations over regional distribution changes are used as instance weights. Constructing different region sets through different schemes will lead to different drift estimation results, thereby creating diversity. The classifiers that disagree the most are selected to maximize diversity. Accordingly, an instance-based ensemble learning algorithm, called the diverse instance weighting ensemble (DiwE), is developed to address concept drift for data stream classification problems. Evaluations of various synthetic and real-world data stream benchmarks show the effectiveness and advantages of the proposed algorithm.
Learning under Concept Drift: A Review
Apr 13, 2020
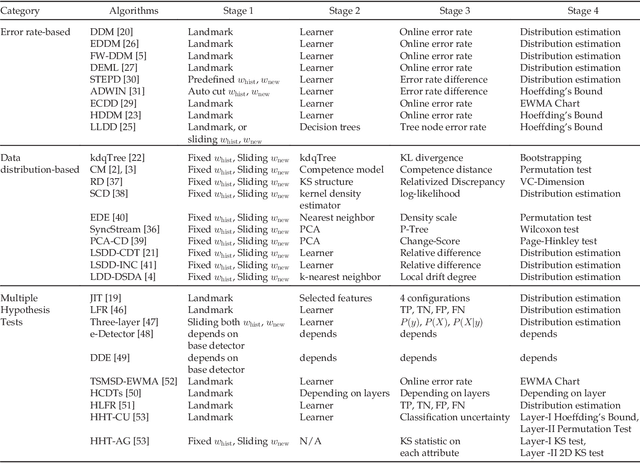
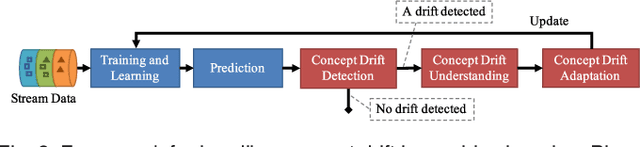
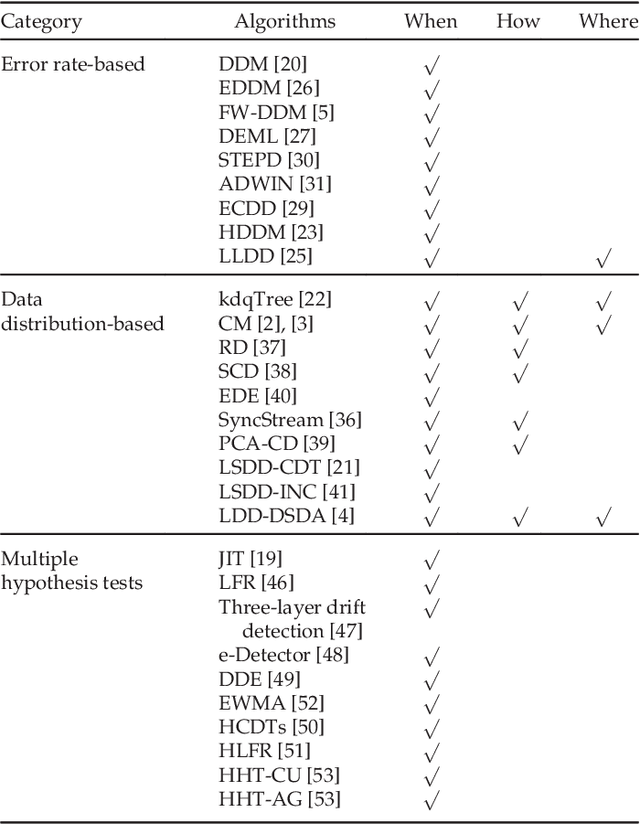
Concept drift describes unforeseeable changes in the underlying distribution of streaming data over time. Concept drift research involves the development of methodologies and techniques for drift detection, understanding and adaptation. Data analysis has revealed that machine learning in a concept drift environment will result in poor learning results if the drift is not addressed. To help researchers identify which research topics are significant and how to apply related techniques in data analysis tasks, it is necessary that a high quality, instructive review of current research developments and trends in the concept drift field is conducted. In addition, due to the rapid development of concept drift in recent years, the methodologies of learning under concept drift have become noticeably systematic, unveiling a framework which has not been mentioned in literature. This paper reviews over 130 high quality publications in concept drift related research areas, analyzes up-to-date developments in methodologies and techniques, and establishes a framework of learning under concept drift including three main components: concept drift detection, concept drift understanding, and concept drift adaptation. This paper lists and discusses 10 popular synthetic datasets and 14 publicly available benchmark datasets used for evaluating the performance of learning algorithms aiming at handling concept drift. Also, concept drift related research directions are covered and discussed. By providing state-of-the-art knowledge, this survey will directly support researchers in their understanding of research developments in the field of learning under concept drift.