 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-DeepResearch Benchmark: Rethinking Visual and Textual Search for Multimodal Large Language Models
Feb 02, 2026Multimodal Large Language Models (MLLMs) have advanced VQA and now support Vision-DeepResearch systems that use search engines for complex visual-textual fact-finding. However, evaluating these visual and textual search abilities is still difficult, and existing benchmarks have two major limitations. First, existing benchmarks are not visual search-centric: answers that should require visual search are often leaked through cross-textual cues in the text questions or can be inferred from the prior world knowledge in current MLLMs. Second, overly idealized evaluation scenario: On the image-search side, the required information can often be obtained via near-exact matching against the full image, while the text-search side is overly direct and insufficiently challenging. To address these issues, we construct the Vision-DeepResearch benchmark (VDR-Bench) comprising 2,000 VQA instances. All questions are created via a careful, multi-stage curation pipeline and rigorous expert review, designed to assess the behavior of Vision-DeepResearch systems under realistic real-world conditions. Moreover, to address the insufficient visual retrieval capabilities of current MLLMs, we propose a simple multi-round cropped-search workflow. This strategy is shown to effectively improve model performance in realistic visual retrieval scenarios. Overall, our results provide practical guidance for the design of future multimodal deep-research systems. The code will be released in https://github.com/Osilly/Vision-DeepResearch.
NSC-SL: A Bandwidth-Aware Neural Subspace Compression for Communication-Efficient Split Learning
Feb 02, 2026The expanding scale of neural networks poses a major challenge for distributed machine learning, particularly under limited communication resources. While split learning (SL) alleviates client computational burden by distributing model layers between clients and server, it incurs substantial communication overhead from frequent transmission of intermediate activations and gradients. To tackle this issue, we propose NSC-SL, a bandwidth-aware adaptive compression algorithm for communication-efficient SL. NSC-SL first dynamically determines the optimal rank of low-rank approximation based on the singular value distribution for adapting real-time bandwidth constraints. Then, NSC-SL performs error-compensated tensor factorization using alternating orthogonal iteration with residual feedback, effectively minimizing truncation loss. The collaborative mechanisms enable NSC-SL to achieve high compression ratios while preserving semantic-rich information essential for convergence. Extensive experiments demonstrate the superb performance of NSC-SL.
Vision-DeepResearch: Incentivizing DeepResearch Capability in Multimodal Large Language Models
Jan 29, 2026Multimodal large language models (MLLMs) have achieved remarkable success across a broad range of vision tasks. However, constrained by the capacity of their internal world knowledge, prior work has proposed augmenting MLLMs by ``reasoning-then-tool-call'' for visual and textual search engines to obtain substantial gains on tasks requiring extensive factual information. However, these approaches typically define multimodal search in a naive setting, assuming that a single full-level or entity-level image query and few text query suffices to retrieve the key evidence needed to answer the question, which is unrealistic in real-world scenarios with substantial visual noise. Moreover, they are often limited in the reasoning depth and search breadth, making it difficult to solve complex questions that require aggregating evidence from diverse visual and textual sources. Building on this, we propose Vision-DeepResearch, which proposes one new multimodal deep-research paradigm, i.e., performs multi-turn, multi-entity and multi-scale visual and textual search to robustly hit real-world search engines under heavy noise. Our Vision-DeepResearch supports dozens of reasoning steps and hundreds of engine interactions, while internalizing deep-research capabilities into the MLLM via cold-start supervision and RL training, resulting in a strong end-to-end multimodal deep-research MLLM. It substantially outperforming existing multimodal deep-research MLLMs, and workflows built on strong closed-source foundation model such as GPT-5, Gemini-2.5-pro and Claude-4-Sonnet. The code will be released in https://github.com/Osilly/Vision-DeepResearch.
How Do Transformers Learn to Associate Tokens: Gradient Leading Terms Bring Mechanistic Interpretability
Jan 27, 2026Semantic associations such as the link between "bird" and "flew" are foundational for language modeling as they enable models to go beyond memorization and instead generalize and generate coherent text. Understanding how these associations are learned and represented in language models is essential for connecting deep learning with linguistic theory and developing a mechanistic foundation for large language models. In this work, we analyze how these associations emerge from natural language data in attention-based language models through the lens of training dynamics. By leveraging a leading-term approximation of the gradients, we develop closed-form expressions for the weights at early stages of training that explain how semantic associations first take shape. Through our analysis, we reveal that each set of weights of the transformer has closed-form expressions as simple compositions of three basis functions (bigram, token-interchangeability, and context mappings), reflecting the statistics of the text corpus and uncovering how each component of the transformer captures semantic associations based on these compositions. Experiments on real-world LLMs demonstrate that our theoretical weight characterizations closely match the learned weights, and qualitative analyses further show how our theorem shines light on interpreting the learned associations in transformers.
Beyond In-Domain Detection: SpikeScore for Cross-Domain Hallucination Detection
Jan 27, 2026Hallucination detection is critical for deploying large language models (LLMs) in real-world applications. Existing hallucination detection methods achieve strong performance when the training and test data come from the same domain, but they suffer from poor cross-domain generalization. In this paper, we study an important yet overlooked problem, termed generalizable hallucination detection (GHD), which aims to train hallucination detectors on data from a single domain while ensuring robust performance across diverse related domains. In studying GHD, we simulate multi-turn dialogues following LLMs initial response and observe an interesting phenomenon: hallucination-initiated multi-turn dialogues universally exhibit larger uncertainty fluctuations than factual ones across different domains. Based on the phenomenon, we propose a new score SpikeScore, which quantifies abrupt fluctuations in multi-turn dialogues. Through both theoretical analysis and empirical validation, we demonstrate that SpikeScore achieves strong cross-domain separability between hallucinated and non-hallucinated responses. Experiments across multiple LLMs and benchmarks demonstrate that the SpikeScore-based detection method outperforms representative baselines in cross-domain generalization and surpasses advanced generalization-oriented methods, verifying the effectiveness of our method in cross-domain hallucination detection.
UniCorn: Towards Self-Improving Unified Multimodal Models through Self-Generated Supervision
Jan 08, 2026While Unified Multimodal Models (UMMs) have achieved remarkable success in cross-modal comprehension, a significant gap persists in their ability to leverage such internal knowledge for high-quality generation. We formalize this discrepancy as Conduction Aphasia, a phenomenon where models accurately interpret multimodal inputs but struggle to translate that understanding into faithful and controllable synthesis. To address this, we propose UniCorn, a simple yet elegant self-improvement framework that eliminates the need for external data or teacher supervision. By partitioning a single UMM into three collaborative roles: Proposer, Solver, and Judge, UniCorn generates high-quality interactions via self-play and employs cognitive pattern reconstruction to distill latent understanding into explicit generative signals. To validate the restoration of multimodal coherence, we introduce UniCycle, a cycle-consistency benchmark based on a Text to Image to Text reconstruction loop. Extensive experiments demonstrate that UniCorn achieves comprehensive and substantial improvements over the base model across six general image generation benchmarks. Notably, it achieves SOTA performance on TIIF(73.8), DPG(86.8), CompBench(88.5), and UniCycle while further delivering substantial gains of +5.0 on WISE and +6.5 on OneIG. These results highlight that our method significantly enhances T2I generation while maintaining robust comprehension, demonstrating the scalability of fully self-supervised refinement for unified multimodal intelligence.
Learning Robust Spectral Dynamics for Temporal Domain Generalization
May 19, 2025
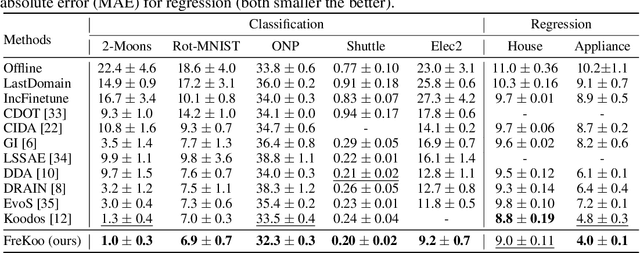
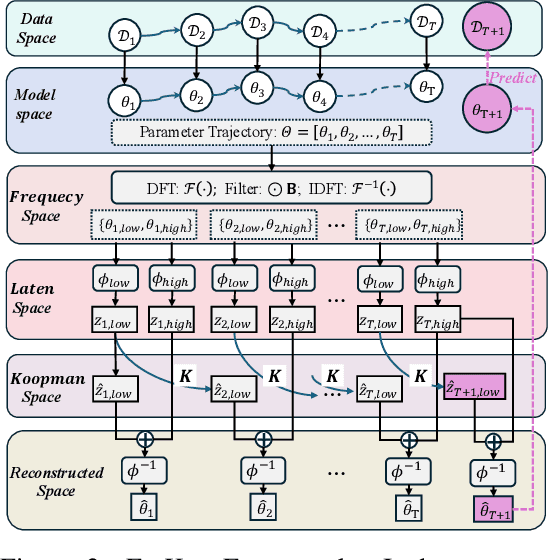

Modern machine learning models struggle to maintain performance in dynamic environments where temporal distribution shifts, \emph{i.e., concept drift}, are prevalent. Temporal Domain Generalization (TDG) seeks to enable model generalization across evolving domains, yet existing approaches typically assume smooth incremental changes, struggling with complex real-world drifts involving long-term structure (incremental evolution/periodicity) and local uncertainties. To overcome these limitations, we introduce FreKoo, which tackles these challenges via a novel frequency-domain analysis of parameter trajectories. It leverages the Fourier transform to disentangle parameter evolution into distinct spectral bands. Specifically, low-frequency component with dominant dynamics are learned and extrapolated using the Koopman operator, robustly capturing diverse drift patterns including both incremental and periodicity. Simultaneously, potentially disruptive high-frequency variations are smoothed via targeted temporal regularization, preventing overfitting to transient noise and domain uncertainties. In addition, this dual spectral strategy is rigorously grounded through theoretical analysis, providing stability guarantees for the Koopman prediction, a principled Bayesian justification for the high-frequency regularization, and culminating in a multiscale generalization bound connecting spectral dynamics to improved generalization. Extensive experiments demonstrate FreKoo's significant superiority over SOTA TDG approaches, particularly excelling in real-world streaming scenarios with complex drifts and uncertainties.
Provable Ordering and Continuity in Vision-Language Pretraining for Generalizable Embodied Agents
Feb 03, 2025Pre-training vision-language representations on human action videos has emerged as a promising approach to reduce reliance on large-scale expert demonstrations for training embodied agents. However, prior methods often employ time contrastive learning based on goal-reaching heuristics, progressively aligning language instructions from the initial to the final frame. This overemphasis on future frames can result in erroneous vision-language associations, as actions may terminate early or include irrelevant moments in the end. To address this issue, we propose Action Temporal Coherence Learning (AcTOL) to learn ordered and continuous vision-language representations without rigid goal-based constraint. AcTOL treats a video as a continuous trajectory where it (1) contrasts semantic differences between frames to reflect their natural ordering, and (2) imposes a local Brownian bridge constraint to ensure smooth transitions across intermediate frames. Extensive imitation learning experiments across varying numbers of demonstrations show that the pretrained features significantly enhance downstream manipulation tasks by up to 49% with high robustness to different linguistic styles of instructions, offering a viable pathway toward generalized embodied agents. The source code is included in the supplementary material for reference.
NLPrompt: Noise-Label Prompt Learning for Vision-Language Models
Dec 02, 2024



The emergence of vision-language foundation models, such as CLIP, has revolutionized image-text representation, enabling a broad range of applications via prompt learning. Despite its promise, real-world datasets often contain noisy labels that can degrade prompt learning performance. In this paper, we demonstrate that using mean absolute error (MAE) loss in prompt learning, named PromptMAE, significantly enhances robustness against noisy labels while maintaining high accuracy. Though MAE is straightforward and recognized for its robustness, it is rarely used in noisy-label learning due to its slow convergence and poor performance outside prompt learning scenarios. To elucidate the robustness of PromptMAE, we leverage feature learning theory to show that MAE can suppress the influence of noisy samples, thereby improving the signal-to-noise ratio and enhancing overall robustness. Additionally, we introduce PromptOT, a prompt-based optimal transport data purification method to enhance the robustness further. PromptOT employs text encoder representations in vision-language models as prototypes to construct an optimal transportation matrix. This matrix effectively partitions datasets into clean and noisy subsets, allowing for the application of cross-entropy loss to the clean subset and MAE loss to the noisy subset. Our Noise-Label Prompt Learning method, named NLPrompt, offers a simple and efficient approach that leverages the expressive representation and precise alignment capabilities of vision-language models for robust prompt learning. We validate NLPrompt through extensive experiments across various noise settings, demonstrating significant performance improvements.
Exclusive Style Removal for Cross Domain Novel Class Discovery
Jun 26, 2024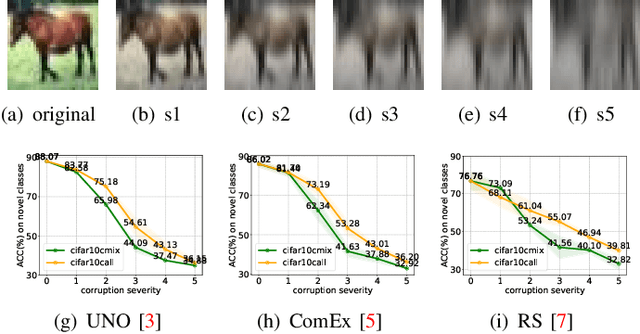
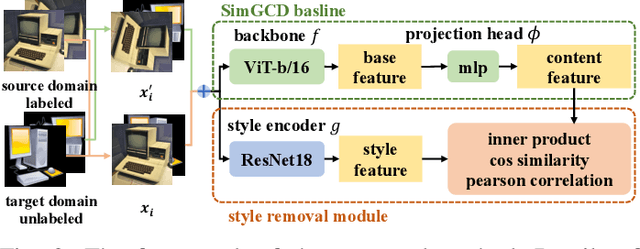
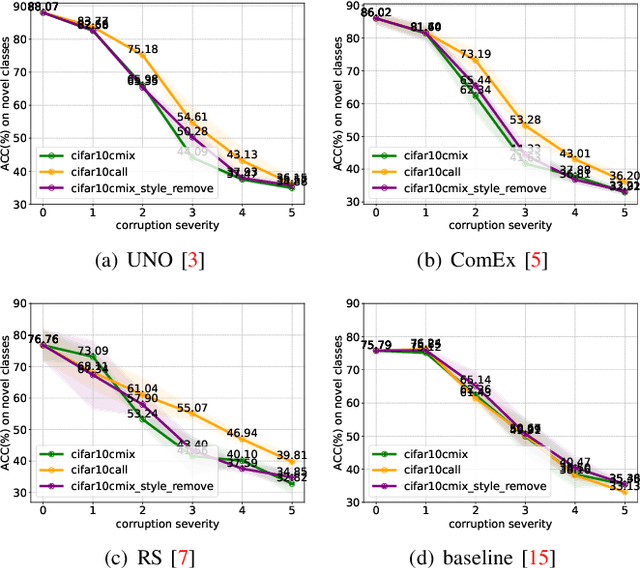

As a promising field in open-world learning, \textit{Novel Class Discovery} (NCD) is usually a task to cluster unseen novel classes in an unlabeled set based on the prior knowledge of labeled data within the same domain. However, the performance of existing NCD methods could be severely compromised when novel classes are sampled from a different distribution with the labeled ones. In this paper, we explore and establish the solvability of NCD in cross domain setting with the necessary condition that style information must be removed. Based on the theoretical analysis, we introduce an exclusive style removal module for extracting style information that is distinctive from the baseline features, thereby facilitating inference. Moreover, this module is easy to integrate with other NCD methods, acting as a plug-in to improve performance on novel classes with different distributions compared to the seen labeled set. Additionally, recognizing the non-negligible influence of different backbones and pre-training strategies on the performance of the NCD methods, we build a fair benchmark for future NCD research. Extensive experiments on three common datasets demonstrate the effectiveness of our proposed module.