 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Multi-platform Person Re-Identification: Benchmark and Method
Mar 21, 2025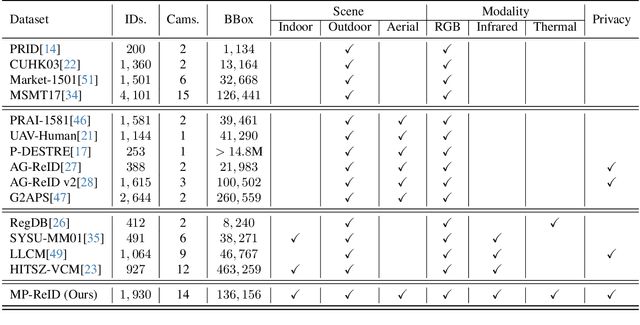

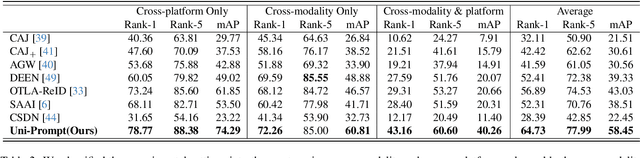
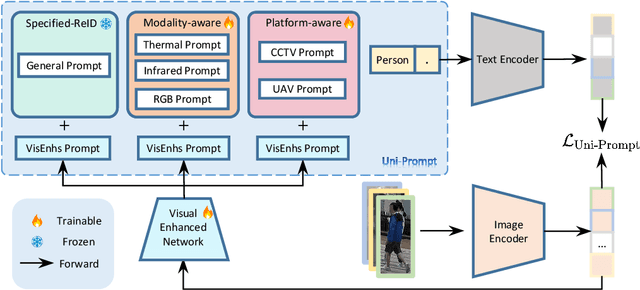
Conventional person re-identification (ReID) research is often limited to single-modality sensor data from static cameras, which fails to address the complexities of real-world scenarios where multi-modal signals are increasingly prevalent. For instance, consider an urban ReID system integrating stationary RGB cameras, nighttime infrared sensors, and UAVs equipped with dynamic tracking capabilities. Such systems face significant challenges due to variations in camera perspectives, lighting conditions, and sensor modalities, hindering effective person ReID. To address these challenges, we introduce the MP-ReID benchmark, a novel dataset designed specifically for multi-modality and multi-platform ReID. This benchmark uniquely compiles data from 1,930 identities across diverse modalities, including RGB, infrared, and thermal imaging, captured by both UAVs and ground-based cameras in indoor and outdoor environments. Building on this benchmark, we introduce Uni-Prompt ReID, a framework with specific-designed prompts, tailored for cross-modality and cross-platform scenarios. Our method consistently outperforms state-of-the-art approaches, establishing a robust foundation for future research in complex and dynamic ReID environments. Our dataset are available at:https://mp-reid.github.io/.
NLPrompt: Noise-Label Prompt Learning for Vision-Language Models
Dec 02, 2024



The emergence of vision-language foundation models, such as CLIP, has revolutionized image-text representation, enabling a broad range of applications via prompt learning. Despite its promise, real-world datasets often contain noisy labels that can degrade prompt learning performance. In this paper, we demonstrate that using mean absolute error (MAE) loss in prompt learning, named PromptMAE, significantly enhances robustness against noisy labels while maintaining high accuracy. Though MAE is straightforward and recognized for its robustness, it is rarely used in noisy-label learning due to its slow convergence and poor performance outside prompt learning scenarios. To elucidate the robustness of PromptMAE, we leverage feature learning theory to show that MAE can suppress the influence of noisy samples, thereby improving the signal-to-noise ratio and enhancing overall robustness. Additionally, we introduce PromptOT, a prompt-based optimal transport data purification method to enhance the robustness further. PromptOT employs text encoder representations in vision-language models as prototypes to construct an optimal transportation matrix. This matrix effectively partitions datasets into clean and noisy subsets, allowing for the application of cross-entropy loss to the clean subset and MAE loss to the noisy subset. Our Noise-Label Prompt Learning method, named NLPrompt, offers a simple and efficient approach that leverages the expressive representation and precise alignment capabilities of vision-language models for robust prompt learning. We validate NLPrompt through extensive experiments across various noise settings, demonstrating significant performance improvements.
Federated Learning from Vision-Language Foundation Models: Theoretical Analysis and Method
Sep 29, 2024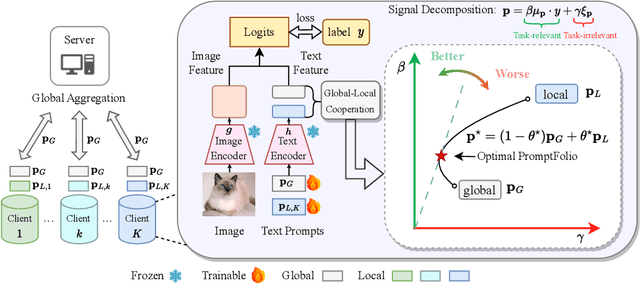

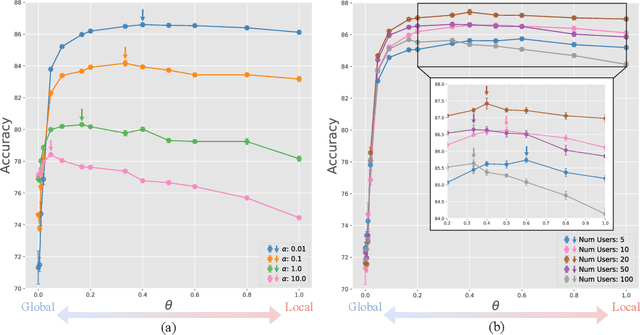
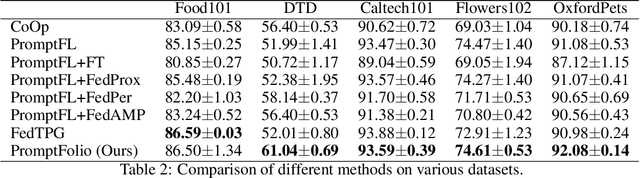
Integrating pretrained vision-language foundation models like CLIP into federated learning has attracted significant attention for enhancing generalization across diverse tasks. Typically, federated learning of vision-language models employs prompt learning to reduce communication and computational costs, i.e., prompt-based federated learning. However, there is limited theoretical analysis to understand the performance of prompt-based federated learning. In this work, we construct a theoretical analysis framework for prompt-based federated learning via feature learning theory. Specifically, we monitor the evolution of signal learning and noise memorization in prompt-based federated learning, demonstrating that performance can be assessed by the ratio of task-relevant to task-irrelevant coefficients. Furthermore, we draw an analogy between income and risk in portfolio optimization and the task-relevant and task-irrelevant terms in feature learning. Leveraging inspiration from portfolio optimization that combining two independent assets will maintain the income while reducing the risk, we introduce two prompts: global prompt and local prompt to construct a prompt portfolio to balance the generalization and personalization. Consequently, we showed the performance advantage of the prompt portfolio and derived the optimal mixing coefficient. These theoretical claims have been further supported by empirical experiments.