 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrokking From Abstraction to Intelligence
Mar 31, 2026Grokking in modular arithmetic has established itself as the quintessential fruit fly experiment, serving as a critical domain for investigating the mechanistic origins of model generalization. Despite its significance, existing research remains narrowly focused on specific local circuits or optimization tuning, largely overlooking the global structural evolution that fundamentally drives this phenomenon. We propose that grokking originates from a spontaneous simplification of internal model structures governed by the principle of parsimony. We integrate causal, spectral, and algorithmic complexity measures alongside Singular Learning Theory to reveal that the transition from memorization to generalization corresponds to the physical collapse of redundant manifolds and deep information compression, offering a novel perspective for understanding the mechanisms of model overfitting and generalization.
Spontaneous Functional Differentiation in Large Language Models: A Brain-Like Intelligence Economy
Mar 31, 2026The evolution of intelligence in artificial systems provides a unique opportunity to identify universal computational principles. Here we show that large language models spontaneously develop synergistic cores where information integration exceeds individual parts remarkably similar to the human brain. Using Integrated Information Decomposition across multiple architectures we find that middle layers exhibit synergistic processing while early and late layers rely on redundancy. This organization is dynamic and emerges as a physical phase transition as task difficulty increases. Crucially ablating synergistic components causes catastrophic performance loss confirming their role as the physical entity of abstract reasoning and bridging artificial and biological intelligence.
PVI: Plug-in Visual Injection for Vision-Language-Action Models
Mar 13, 2026VLA architectures that pair a pretrained VLM with a flow-matching action expert have emerged as a strong paradigm for language-conditioned manipulation. Yet the VLM, optimized for semantic abstraction and typically conditioned on static visual observations, tends to attenuate fine-grained geometric cues and often lacks explicit temporal evidence for the action expert. Prior work mitigates this by injecting auxiliary visual features, but existing approaches either focus on static spatial representations or require substantial architectural modifications to accommodate temporal inputs, leaving temporal information underexplored. We propose Plug-in Visual Injection (PVI), a lightweight, encoder-agnostic module that attaches to a pretrained action expert and injects auxiliary visual representations via zero-initialized residual pathways, preserving pretrained behavior with only single-stage fine-tuning. Using PVI, we obtain consistent gains over the base policy and a range of competitive alternative injection strategies, and our controlled study shows that temporal video features (V-JEPA2) outperform strong static image features (DINOv2), with the largest gains on multi-phase tasks requiring state tracking and coordination. Real-robot experiments on long-horizon bimanual cloth folding further demonstrate the practicality of PVI beyond simulation.
DriveMamba: Task-Centric Scalable State Space Model for Efficient End-to-End Autonomous Driving
Feb 09, 2026Recent advances towards End-to-End Autonomous Driving (E2E-AD) have been often devoted on integrating modular designs into a unified framework for joint optimization e.g. UniAD, which follow a sequential paradigm (i.e., perception-prediction-planning) based on separable Transformer decoders and rely on dense BEV features to encode scene representations. However, such manual ordering design can inevitably cause information loss and cumulative errors, lacking flexible and diverse relation modeling among different modules and sensors. Meanwhile, insufficient training of image backbone and quadratic-complexity of attention mechanism also hinder the scalability and efficiency of E2E-AD system to handle spatiotemporal input. To this end, we propose DriveMamba, a Task-Centric Scalable paradigm for efficient E2E-AD, which integrates dynamic task relation modeling, implicit view correspondence learning and long-term temporal fusion into a single-stage Unified Mamba decoder. Specifically, both extracted image features and expected task outputs are converted into token-level sparse representations in advance, which are then sorted by their instantiated positions in 3D space. The linear-complexity operator enables efficient long-context sequential token modeling to capture task-related inter-dependencies simultaneously. Additionally, a bidirectional trajectory-guided "local-to-global" scan method is designed to preserve spatial locality from ego-perspective, thus facilitating the ego-planning. Extensive experiments conducted on nuScenes and Bench2Drive datasets demonstrate the superiority, generalizability and great efficiency of DriveMamba.
MDL: A Unified Multi-Distribution Learner in Large-scale Industrial Recommendation through Tokenization
Feb 07, 2026Industrial recommender systems increasingly adopt multi-scenario learning (MSL) and multi-task learning (MTL) to handle diverse user interactions and contexts, but existing approaches suffer from two critical drawbacks: (1) underutilization of large-scale model parameters due to limited interaction with complex feature modules, and (2) difficulty in jointly modeling scenario and task information in a unified framework. To address these challenges, we propose a unified \textbf{M}ulti-\textbf{D}istribution \textbf{L}earning (MDL) framework, inspired by the "prompting" paradigm in large language models (LLMs). MDL treats scenario and task information as specialized tokens rather than auxiliary inputs or gating signals. Specifically, we introduce a unified information tokenization module that transforms features, scenarios, and tasks into a unified tokenized format. To facilitate deep interaction, we design three synergistic mechanisms: (1) feature token self-attention for rich feature interactions, (2) domain-feature attention for scenario/task-adaptive feature activation, and (3) domain-fused aggregation for joint distribution prediction. By stacking these interactions, MDL enables scenario and task information to "prompt" and activate the model's vast parameter space in a bottom-up, layer-wise manner. Extensive experiments on real-world industrial datasets demonstrate that MDL significantly outperforms state-of-the-art MSL and MTL baselines. Online A/B testing on Douyin Search platform over one month yields +0.0626\% improvement in LT30 and -0.3267\% reduction in change query rate. MDL has been fully deployed in production, serving hundreds of millions of users daily.
MSN: A Memory-based Sparse Activation Scaling Framework for Large-scale Industrial Recommendation
Feb 07, 2026Scaling deep learning recommendation models is an effective way to improve model expressiveness. Existing approaches often incur substantial computational overhead, making them difficult to deploy in large-scale industrial systems under strict latency constraints. Recent sparse activation scaling methods, such as Sparse Mixture-of-Experts, reduce computation by activating only a subset of parameters, but still suffer from high memory access costs and limited personalization capacity due to the large size and small number of experts. To address these challenges, we propose MSN, a memory-based sparse activation scaling framework for recommendation models. MSN dynamically retrieves personalized representations from a large parameterized memory and integrates them into downstream feature interaction modules via a memory gating mechanism, enabling fine-grained personalization with low computational overhead. To enable further expansion of the memory capacity while keeping both computational and memory access costs under control, MSN adopts a Product-Key Memory (PKM) mechanism, which factorizes the memory retrieval complexity from linear time to sub-linear complexity. In addition, normalization and over-parameterization techniques are introduced to maintain balanced memory utilization and prevent memory retrieval collapse. We further design customized Sparse-Gather operator and adopt the AirTopK operator to improve training and inference efficiency in industrial settings. Extensive experiments demonstrate that MSN consistently improves recommendation performance while maintaining high efficiency. Moreover, MSN has been successfully deployed in the Douyin Search Ranking System, achieving significant gains over deployed state-of-the-art models in both offline evaluation metrics and large-scale online A/B test.
Frequency-Aware Vision-Language Multimodality Generalization Network for Remote Sensing Image Classification
Nov 13, 2025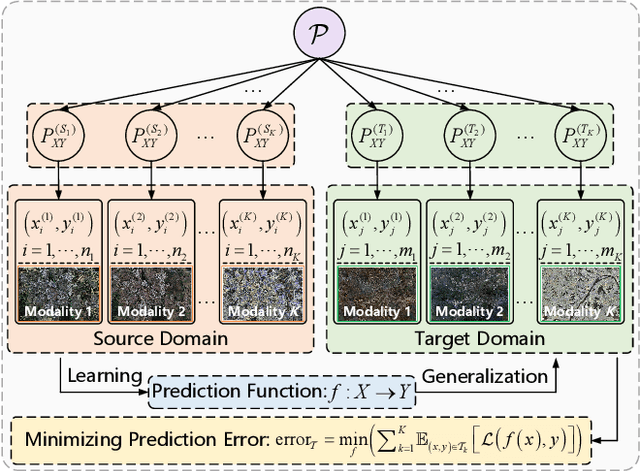
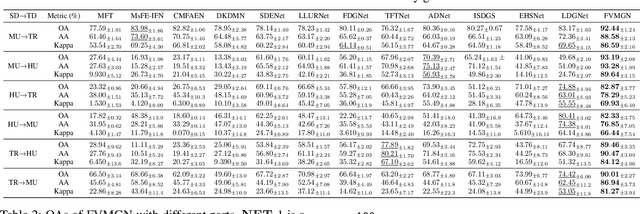
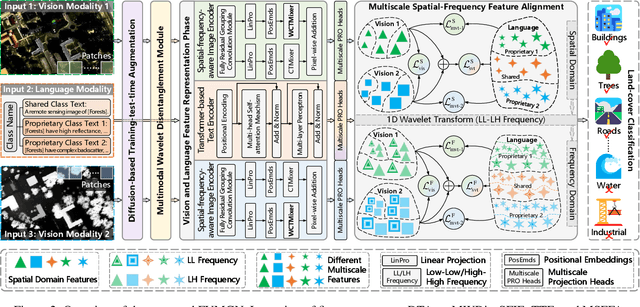
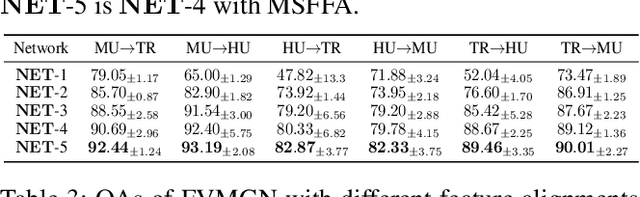
The booming remote sensing (RS) technology is giving rise to a novel multimodality generalization task, which requires the model to overcome data heterogeneity while possessing powerful cross-scene generalization ability. Moreover, most vision-language models (VLMs) usually describe surface materials in RS images using universal texts, lacking proprietary linguistic prior knowledge specific to different RS vision modalities. In this work, we formalize RS multimodality generalization (RSMG) as a learning paradigm, and propose a frequency-aware vision-language multimodality generalization network (FVMGN) for RS image classification. Specifically, a diffusion-based training-test-time augmentation (DTAug) strategy is designed to reconstruct multimodal land-cover distributions, enriching input information for FVMGN. Following that, to overcome multimodal heterogeneity, a multimodal wavelet disentanglement (MWDis) module is developed to learn cross-domain invariant features by resampling low and high frequency components in the frequency domain. Considering the characteristics of RS vision modalities, shared and proprietary class texts is designed as linguistic inputs for the transformer-based text encoder to extract diverse text features. For multimodal vision inputs, a spatial-frequency-aware image encoder (SFIE) is constructed to realize local-global feature reconstruction and representation. Finally, a multiscale spatial-frequency feature alignment (MSFFA) module is suggested to construct a unified semantic space, ensuring refined multiscale alignment of different text and vision features in spatial and frequency domains. Extensive experiments show that FVMGN has the excellent multimodality generalization ability compared with state-of-the-art (SOTA) methods.
STARec: An Efficient Agent Framework for Recommender Systems via Autonomous Deliberate Reasoning
Aug 26, 2025While modern recommender systems are instrumental in navigating information abundance, they remain fundamentally limited by static user modeling and reactive decision-making paradigms. Current large language model (LLM)-based agents inherit these shortcomings through their overreliance on heuristic pattern matching, yielding recommendations prone to shallow correlation bias, limited causal inference, and brittleness in sparse-data scenarios. We introduce STARec, a slow-thinking augmented agent framework that endows recommender systems with autonomous deliberative reasoning capabilities. Each user is modeled as an agent with parallel cognitions: fast response for immediate interactions and slow reasoning that performs chain-of-thought rationales. To cultivate intrinsic slow thinking, we develop anchored reinforcement training - a two-stage paradigm combining structured knowledge distillation from advanced reasoning models with preference-aligned reward shaping. This hybrid approach scaffolds agents in acquiring foundational capabilities (preference summarization, rationale generation) while enabling dynamic policy adaptation through simulated feedback loops. Experiments on MovieLens 1M and Amazon CDs benchmarks demonstrate that STARec achieves substantial performance gains compared with state-of-the-art baselines, despite using only 0.4% of the full training data.
SimpleDeepSearcher: Deep Information Seeking via Web-Powered Reasoning Trajectory Synthesis
May 22, 2025



Retrieval-augmented generation (RAG) systems have advanced large language models (LLMs) in complex deep search scenarios requiring multi-step reasoning and iterative information retrieval. However, existing approaches face critical limitations that lack high-quality training trajectories or suffer from the distributional mismatches in simulated environments and prohibitive computational costs for real-world deployment. This paper introduces SimpleDeepSearcher, a lightweight yet effective framework that bridges this gap through strategic data engineering rather than complex training paradigms. Our approach synthesizes high-quality training data by simulating realistic user interactions in live web search environments, coupled with a multi-criteria curation strategy that optimizes the diversity and quality of input and output side. Experiments on five benchmarks across diverse domains demonstrate that SFT on only 871 curated samples yields significant improvements over RL-based baselines. Our work establishes SFT as a viable pathway by systematically addressing the data-scarce bottleneck, offering practical insights for efficient deep search systems. Our code is available at https://github.com/RUCAIBox/SimpleDeepSearcher.
Slow Thinking for Sequential Recommendation
Apr 13, 2025To develop effective sequential recommender systems, numerous methods have been proposed to model historical user behaviors. Despite the effectiveness, these methods share the same fast thinking paradigm. That is, for making recommendations, these methods typically encodes user historical interactions to obtain user representations and directly match these representations with candidate item representations. However, due to the limited capacity of traditional lightweight recommendation models, this one-step inference paradigm often leads to suboptimal performance. To tackle this issue, we present a novel slow thinking recommendation model, named STREAM-Rec. Our approach is capable of analyzing historical user behavior, generating a multi-step, deliberative reasoning process, and ultimately delivering personalized recommendations. In particular, we focus on two key challenges: (1) identifying the suitable reasoning patterns in recommender systems, and (2) exploring how to effectively stimulate the reasoning capabilities of traditional recommenders. To this end, we introduce a three-stage training framework. In the first stage, the model is pretrained on large-scale user behavior data to learn behavior patterns and capture long-range dependencies. In the second stage, we design an iterative inference algorithm to annotate suitable reasoning traces by progressively refining the model predictions. This annotated data is then used to fine-tune the model. Finally, in the third stage, we apply reinforcement learning to further enhance the model generalization ability. Extensive experiments validate the effectiveness of our proposed method.