 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-Master: Unleashing the Potential of Software Engineering Agents via Post-Training
Feb 03, 2026In this technical report, we present SWE-Master, an open-source and fully reproducible post-training framework for building effective software engineering agents. SWE-Master systematically explores the complete agent development pipeline, including teacher-trajectory synthesis and data curation, long-horizon SFT, RL with real execution feedback, and inference framework design. Starting from an open-source base model with limited initial SWE capability, SWE-Master demonstrates how systematical optimization method can elicit strong long-horizon SWE task solving abilities. We evaluate SWE-Master on SWE-bench Verified, a standard benchmark for realistic software engineering tasks. Under identical experimental settings, our approach achieves a resolve rate of 61.4\% with Qwen2.5-Coder-32B, substantially outperforming existing open-source baselines. By further incorporating test-time scaling~(TTS) with LLM-based environment feedback, SWE-Master reaches 70.8\% at TTS@8, demonstrating a strong performance potential. SWE-Master provides a practical and transparent foundation for advancing reproducible research on software engineering agents. The code is available at https://github.com/RUCAIBox/SWE-Master.
SWE-World: Building Software Engineering Agents in Docker-Free Environments
Feb 03, 2026Recent advances in large language models (LLMs) have enabled software engineering agents to tackle complex code modification tasks. Most existing approaches rely on execution feedback from containerized environments, which require dependency-complete setup and physical execution of programs and tests. While effective, this paradigm is resource-intensive and difficult to maintain, substantially complicating agent training and limiting scalability. We propose SWE-World, a Docker-free framework that replaces physical execution environments with a learned surrogate for training and evaluating software engineering agents. SWE-World leverages LLM-based models trained on real agent-environment interaction data to predict intermediate execution outcomes and final test feedback, enabling agents to learn without interacting with physical containerized environments. This design preserves the standard agent-environment interaction loop while eliminating the need for costly environment construction and maintenance during agent optimization and evaluation. Furthermore, because SWE-World can simulate the final evaluation outcomes of candidate trajectories without real submission, it enables selecting the best solution among multiple test-time attempts, thereby facilitating effective test-time scaling (TTS) in software engineering tasks. Experiments on SWE-bench Verified demonstrate that SWE-World raises Qwen2.5-Coder-32B from 6.2\% to 52.0\% via Docker-free SFT, 55.0\% with Docker-free RL, and 68.2\% with further TTS. The code is available at https://github.com/RUCAIBox/SWE-World
LLM-in-Sandbox Elicits General Agentic Intelligence
Jan 22, 2026We introduce LLM-in-Sandbox, enabling LLMs to explore within a code sandbox (i.e., a virtual computer), to elicit general intelligence in non-code domains. We first demonstrate that strong LLMs, without additional training, exhibit generalization capabilities to leverage the code sandbox for non-code tasks. For example, LLMs spontaneously access external resources to acquire new knowledge, leverage the file system to handle long contexts, and execute scripts to satisfy formatting requirements. We further show that these agentic capabilities can be enhanced through LLM-in-Sandbox Reinforcement Learning (LLM-in-Sandbox-RL), which uses only non-agentic data to train models for sandbox exploration. Experiments demonstrate that LLM-in-Sandbox, in both training-free and post-trained settings, achieves robust generalization spanning mathematics, physics, chemistry, biomedicine, long-context understanding, and instruction following. Finally, we analyze LLM-in-Sandbox's efficiency from computational and system perspectives, and open-source it as a Python package to facilitate real-world deployment.
R1-Searcher++: Incentivizing the Dynamic Knowledge Acquisition of LLMs via Reinforcement Learning
May 22, 2025Large Language Models (LLMs) are powerful but prone to hallucinations due to static knowledge. Retrieval-Augmented Generation (RAG) helps by injecting external information, but current methods often are costly, generalize poorly, or ignore the internal knowledge of the model. In this paper, we introduce R1-Searcher++, a novel framework designed to train LLMs to adaptively leverage both internal and external knowledge sources. R1-Searcher++ employs a two-stage training strategy: an initial SFT Cold-start phase for preliminary format learning, followed by RL for Dynamic Knowledge Acquisition. The RL stage uses outcome-supervision to encourage exploration, incorporates a reward mechanism for internal knowledge utilization, and integrates a memorization mechanism to continuously assimilate retrieved information, thereby enriching the model's internal knowledge. By leveraging internal knowledge and external search engine, the model continuously improves its capabilities, enabling efficient retrieval-augmented reasoning. Our experiments demonstrate that R1-Searcher++ outperforms previous RAG and reasoning methods and achieves efficient retrieval. The code is available at https://github.com/RUCAIBox/R1-Searcher-plus.
SimpleDeepSearcher: Deep Information Seeking via Web-Powered Reasoning Trajectory Synthesis
May 22, 2025



Retrieval-augmented generation (RAG) systems have advanced large language models (LLMs) in complex deep search scenarios requiring multi-step reasoning and iterative information retrieval. However, existing approaches face critical limitations that lack high-quality training trajectories or suffer from the distributional mismatches in simulated environments and prohibitive computational costs for real-world deployment. This paper introduces SimpleDeepSearcher, a lightweight yet effective framework that bridges this gap through strategic data engineering rather than complex training paradigms. Our approach synthesizes high-quality training data by simulating realistic user interactions in live web search environments, coupled with a multi-criteria curation strategy that optimizes the diversity and quality of input and output side. Experiments on five benchmarks across diverse domains demonstrate that SFT on only 871 curated samples yields significant improvements over RL-based baselines. Our work establishes SFT as a viable pathway by systematically addressing the data-scarce bottleneck, offering practical insights for efficient deep search systems. Our code is available at https://github.com/RUCAIBox/SimpleDeepSearcher.
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
Mar 07, 2025



Existing Large Reasoning Models (LRMs) have shown the potential of reinforcement learning (RL) to enhance the complex reasoning capabilities of Large Language Models~(LLMs). While they achieve remarkable performance on challenging tasks such as mathematics and coding, they often rely on their internal knowledge to solve problems, which can be inadequate for time-sensitive or knowledge-intensive questions, leading to inaccuracies and hallucinations. To address this, we propose \textbf{R1-Searcher}, a novel two-stage outcome-based RL approach designed to enhance the search capabilities of LLMs. This method allows LLMs to autonomously invoke external search systems to access additional knowledge during the reasoning process. Our framework relies exclusively on RL, without requiring process rewards or distillation for a cold start. % effectively generalizing to out-of-domain datasets and supporting both Base and Instruct models. Our experiments demonstrate that our method significantly outperforms previous strong RAG methods, even when compared to the closed-source GPT-4o-mini.
YuLan-Mini: An Open Data-efficient Language Model
Dec 24, 2024



Effective pre-training of large language models (LLMs) has been challenging due to the immense resource demands and the complexity of the technical processes involved. This paper presents a detailed technical report on YuLan-Mini, a highly capable base model with 2.42B parameters that achieves top-tier performance among models of similar parameter scale. Our pre-training approach focuses on enhancing training efficacy through three key technical contributions: an elaborate data pipeline combines data cleaning with data schedule strategies, a robust optimization method to mitigate training instability, and an effective annealing approach that incorporates targeted data selection and long context training. Remarkably, YuLan-Mini, trained on 1.08T tokens, achieves performance comparable to industry-leading models that require significantly more data. To facilitate reproduction, we release the full details of the data composition for each training phase. Project details can be accessed at the following link: https://github.com/RUC-GSAI/YuLan-Mini.
Imitate, Explore, and Self-Improve: A Reproduction Report on Slow-thinking Reasoning Systems
Dec 12, 2024


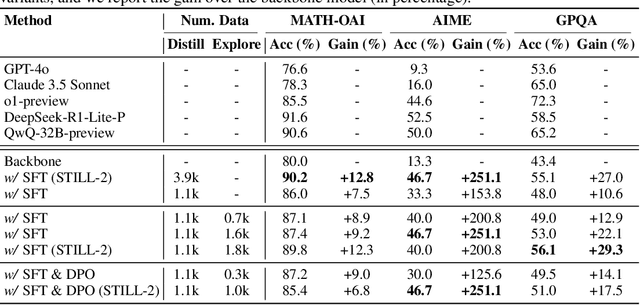
Recently, slow-thinking reasoning systems, such as o1, have demonstrated remarkable capabilities in solving complex reasoning tasks. These systems typically engage in an extended thinking process before responding to a query, allowing them to generate more thorough, accurate, and well-reasoned solutions. These systems are primarily developed and maintained by industry, with their core techniques not publicly disclosed. In response, an increasing number of studies from the research community aim to explore the technical foundations underlying these powerful reasoning systems. Building on these prior efforts, this paper presents a reproduction report on implementing o1-like reasoning systems. We introduce an "imitate, explore, and self-improve" framework as our primary technical approach to train the reasoning model. In the initial phase, we use distilled long-form thought data to fine-tune the reasoning model, enabling it to invoke a slow-thinking mode. The model is then encouraged to explore challenging problems by generating multiple rollouts, which can result in increasingly more high-quality trajectories that lead to correct answers. Furthermore, the model undergoes self-improvement by iteratively refining its training dataset. To verify the effectiveness of this approach, we conduct extensive experiments on three challenging benchmarks. The experimental results demonstrate that our approach achieves competitive performance compared to industry-level reasoning systems on these benchmarks.