 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Cross-task Transfer of Large Language Models via Activation Steering
Jul 17, 2025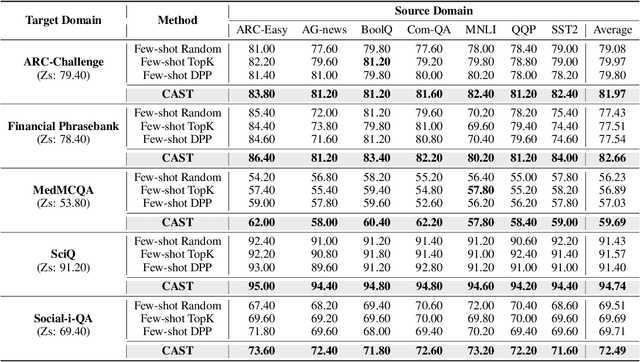
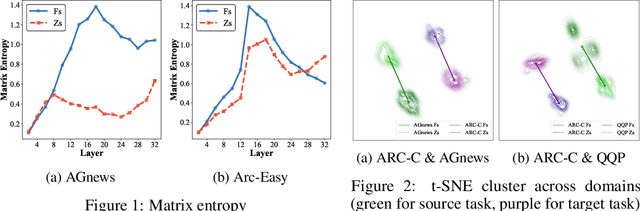

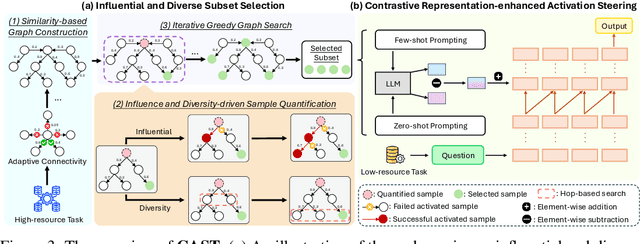
Large language models (LLMs) have shown impressive abilities in leveraging pretrained knowledge through prompting, but they often struggle with unseen tasks, particularly in data-scarce scenarios. While cross-task in-context learning offers a direct solution for transferring knowledge across tasks, it still faces critical challenges in terms of robustness, scalability, and efficiency. In this paper, we investigate whether cross-task transfer can be achieved via latent space steering without parameter updates or input expansion. Through an analysis of activation patterns in the latent space of LLMs, we observe that the enhanced activations induced by in-context examples have consistent patterns across different tasks. Inspired by these findings, we propose CAST, a novel Cross-task Activation Steering Transfer framework that enables effective transfer by manipulating the model's internal activation states. Our approach first selects influential and diverse samples from high-resource tasks, then utilizes their contrastive representation-enhanced activations to adapt LLMs to low-resource tasks. Extensive experiments across both cross-domain and cross-lingual transfer settings show that our method outperforms competitive baselines and demonstrates superior scalability and lower computational costs.
Incentivizing Dual Process Thinking for Efficient Large Language Model Reasoning
May 22, 2025Large reasoning models (LRMs) have demonstrated strong performance on complex reasoning tasks, but often suffer from overthinking, generating redundant content regardless of task difficulty. Inspired by the dual process theory in cognitive science, we propose Adaptive Cognition Policy Optimization (ACPO), a reinforcement learning framework that enables LRMs to achieve efficient reasoning through adaptive cognitive allocation and dynamic system switch. ACPO incorporates two key components: (1) introducing system-aware reasoning tokens to explicitly represent the thinking modes thereby making the model's cognitive process transparent, and (2) integrating online difficulty estimation and token length budget to guide adaptive system switch and reasoning during reinforcement learning. To this end, we propose a two-stage training strategy. The first stage begins with supervised fine-tuning to cold start the model, enabling it to generate reasoning paths with explicit thinking modes. In the second stage, we apply ACPO to further enhance adaptive system switch for difficulty-aware reasoning. Experimental results demonstrate that ACPO effectively reduces redundant reasoning while adaptively adjusting cognitive allocation based on task complexity, achieving efficient hybrid reasoning.
Think More, Hallucinate Less: Mitigating Hallucinations via Dual Process of Fast and Slow Thinking
Jan 03, 2025Large language models (LLMs) demonstrate exceptional capabilities, yet still face the hallucination issue. Typical text generation approaches adopt an auto-regressive generation without deliberate reasoning, which often results in untrustworthy and factually inaccurate responses. In this paper, we propose HaluSearch, a novel framework that incorporates tree search-based algorithms (e.g. MCTS) to enable an explicit slow thinking generation process for mitigating hallucinations of LLMs during inference. Specifically, HaluSearch frames text generation as a step-by-step reasoning process, using a self-evaluation reward model to score each generation step and guide the tree search towards the most reliable generation pathway for fully exploiting the internal knowledge of LLMs. To balance efficiency and quality, we introduce a hierarchical thinking system switch mechanism inspired by the dual process theory in cognitive science, which dynamically alternates between fast and slow thinking modes at both the instance and step levels, adapting to the complexity of questions and reasoning states. We conduct extensive experiments on both English and Chinese datasets and the results show that our approach significantly outperforms baseline approaches.
Imitate, Explore, and Self-Improve: A Reproduction Report on Slow-thinking Reasoning Systems
Dec 12, 2024


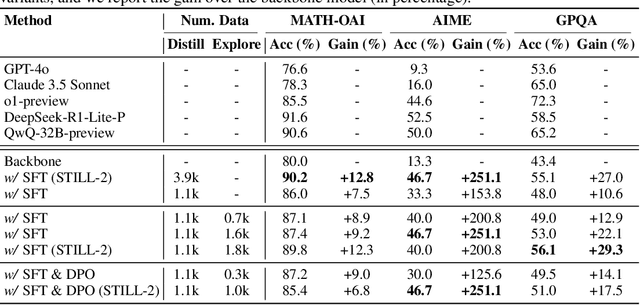
Recently, slow-thinking reasoning systems, such as o1, have demonstrated remarkable capabilities in solving complex reasoning tasks. These systems typically engage in an extended thinking process before responding to a query, allowing them to generate more thorough, accurate, and well-reasoned solutions. These systems are primarily developed and maintained by industry, with their core techniques not publicly disclosed. In response, an increasing number of studies from the research community aim to explore the technical foundations underlying these powerful reasoning systems. Building on these prior efforts, this paper presents a reproduction report on implementing o1-like reasoning systems. We introduce an "imitate, explore, and self-improve" framework as our primary technical approach to train the reasoning model. In the initial phase, we use distilled long-form thought data to fine-tune the reasoning model, enabling it to invoke a slow-thinking mode. The model is then encouraged to explore challenging problems by generating multiple rollouts, which can result in increasingly more high-quality trajectories that lead to correct answers. Furthermore, the model undergoes self-improvement by iteratively refining its training dataset. To verify the effectiveness of this approach, we conduct extensive experiments on three challenging benchmarks. The experimental results demonstrate that our approach achieves competitive performance compared to industry-level reasoning systems on these benchmarks.
Technical Report: Enhancing LLM Reasoning with Reward-guided Tree Search
Nov 18, 2024



Recently, test-time scaling has garnered significant attention from the research community, largely due to the substantial advancements of the o1 model released by OpenAI. By allocating more computational resources during the inference phase, large language models~(LLMs) can extensively explore the solution space by generating more thought tokens or diverse solutions, thereby producing more accurate responses. However, developing an o1-like reasoning approach is challenging, and researchers have been making various attempts to advance this open area of research. In this paper, we present a preliminary exploration into enhancing the reasoning abilities of LLMs through reward-guided tree search algorithms. This framework is implemented by integrating the policy model, reward model, and search algorithm. It is primarily constructed around a tree search algorithm, where the policy model navigates a dynamically expanding tree guided by a specially trained reward model. We thoroughly explore various design considerations necessary for implementing this framework and provide a detailed report of the technical aspects. To assess the effectiveness of our approach, we focus on mathematical reasoning tasks and conduct extensive evaluations on four challenging datasets, significantly enhancing the reasoning abilities of LLMs.
LLMBox: A Comprehensive Library for Large Language Models
Jul 08, 2024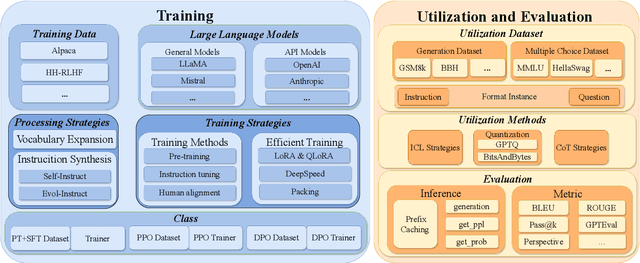
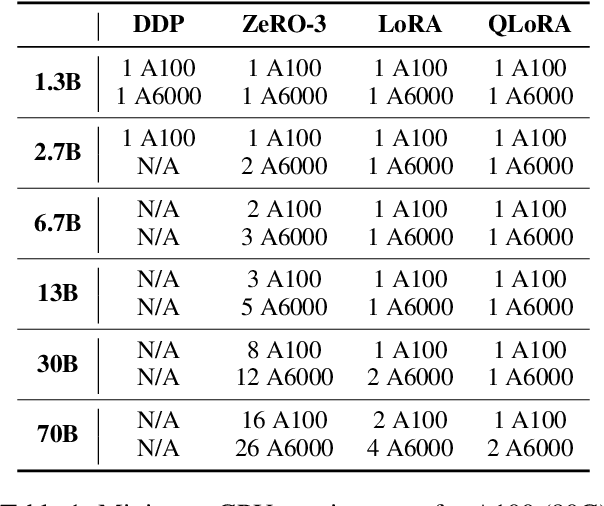


To facilitate the research on large language models (LLMs), this paper presents a comprehensive and unified library, LLMBox, to ease the development, use, and evaluation of LLMs. This library is featured with three main merits: (1) a unified data interface that supports the flexible implementation of various training strategies, (2) a comprehensive evaluation that covers extensive tasks, datasets, and models, and (3) more practical consideration, especially on user-friendliness and efficiency. With our library, users can easily reproduce existing methods, train new models, and conduct comprehensive performance comparisons. To rigorously test LLMBox, we conduct extensive experiments in a diverse coverage of evaluation settings, and experimental results demonstrate the effectiveness and efficiency of our library in supporting various implementations related to LLMs. The detailed introduction and usage guidance can be found at https://github.com/RUCAIBox/LLMBox.
YuLan: An Open-source Large Language Model
Jun 28, 2024



Large language models (LLMs) have become the foundation of many applications, leveraging their extensive capabilities in processing and understanding natural language. While many open-source LLMs have been released with technical reports, the lack of training details hinders further research and development. This paper presents the development of YuLan, a series of open-source LLMs with $12$ billion parameters. The base model of YuLan is pre-trained on approximately $1.7$T tokens derived from a diverse corpus, including massive English, Chinese, and multilingual texts. We design a three-stage pre-training method to enhance YuLan's overall capabilities. Subsequent phases of training incorporate instruction-tuning and human alignment, employing a substantial volume of high-quality synthesized data. To facilitate the learning of complex and long-tail knowledge, we devise a curriculum-learning framework throughout across these stages, which helps LLMs learn knowledge in an easy-to-hard manner. YuLan's training is finished on Jan, 2024 and has achieved performance on par with state-of-the-art LLMs across various English and Chinese benchmarks. This paper outlines a comprehensive technical roadmap for developing LLMs from scratch. Our model and codes are available at https://github.com/RUC-GSAI/YuLan-Chat.
Small Agent Can Also Rock! Empowering Small Language Models as Hallucination Detector
Jun 17, 2024

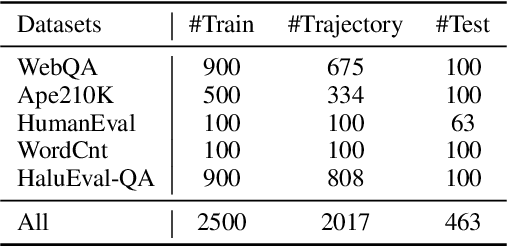

Hallucination detection is a challenging task for large language models (LLMs), and existing studies heavily rely on powerful closed-source LLMs such as GPT-4. In this paper, we propose an autonomous LLM-based agent framework, called HaluAgent, which enables relatively smaller LLMs (e.g. Baichuan2-Chat 7B) to actively select suitable tools for detecting multiple hallucination types such as text, code, and mathematical expression. In HaluAgent, we integrate the LLM, multi-functional toolbox, and design a fine-grained three-stage detection framework along with memory mechanism. To facilitate the effectiveness of HaluAgent, we leverage existing Chinese and English datasets to synthesize detection trajectories for fine-tuning, which endows HaluAgent with the capability for bilingual hallucination detection. Extensive experiments demonstrate that only using 2K samples for tuning LLMs, HaluAgent can perform hallucination detection on various types of tasks and datasets, achieving performance comparable to or even higher than GPT-4 without tool enhancements on both in-domain and out-of-domain datasets. We release our dataset and code at https://github.com/RUCAIBox/HaluAgent.
ChainLM: Empowering Large Language Models with Improved Chain-of-Thought Prompting
Mar 21, 2024
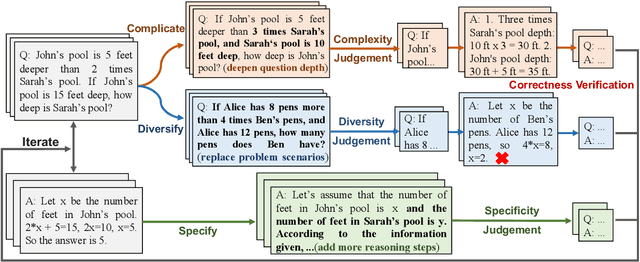


Chain-of-Thought (CoT) prompting can enhance the reasoning capabilities of large language models (LLMs), establishing itself as a primary approach to solving complex reasoning tasks. Existing CoT synthesis approaches usually focus on simpler reasoning tasks and thus result in low-quality and inconsistent CoT prompts. In response to this challenge, we present an empirical investigation of CoT prompting and introduce CoTGenius, a novel framework designed for the automatic generation of superior CoT prompts. CoTGenius is developed based on three major evolution strategies, i.e., complicate, diversify, and specify-alongside two filtering mechanisms: evolutionary success judgement and correctness verification. We further employ CoTGenius to create an extensive CoT dataset, and subsequently fine-tune the Llama 2-Chat 7B and 13B models on this dataset. We call the resulting model ChainLM. To deal with the cumulative error issue in reasoning steps, we propose a step-level debating method, wherein multiple debaters discuss each reasoning step to arrive at the correct answer. Extensive experiments demonstrate that our ChainLM models exhibit enhanced proficiency in addressing a spectrum of complex reasoning problems compared to existing models. In addition, we conduct an in-depth analysis of the impact of data categories within CoTGenius on the model performance. We release our dataset and code at https://github.com/RUCAIBox/ChainLM.
The Dawn After the Dark: An Empirical Study on Factuality Hallucination in Large Language Models
Jan 06, 2024In the era of large language models (LLMs), hallucination (i.e., the tendency to generate factually incorrect content) poses great challenge to trustworthy and reliable deployment of LLMs in real-world applications. To tackle the LLM hallucination, three key questions should be well studied: how to detect hallucinations (detection), why do LLMs hallucinate (source), and what can be done to mitigate them (mitigation). To address these challenges, this work presents a systematic empirical study on LLM hallucination, focused on the the three aspects of hallucination detection, source and mitigation. Specially, we construct a new hallucination benchmark HaluEval 2.0, and designs a simple yet effective detection method for LLM hallucination. Furthermore, we zoom into the different training or utilization stages of LLMs and extensively analyze the potential factors that lead to the LLM hallucination. Finally, we implement and examine a series of widely used techniques to mitigate the hallucinations in LLMs. Our work has led to several important findings to understand the hallucination origin and mitigate the hallucinations in LLMs. Our code and data can be accessed at https://github.com/RUCAIBox/HaluEval-2.0.