 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-World: Building Software Engineering Agents in Docker-Free Environments
Feb 03, 2026Recent advances in large language models (LLMs) have enabled software engineering agents to tackle complex code modification tasks. Most existing approaches rely on execution feedback from containerized environments, which require dependency-complete setup and physical execution of programs and tests. While effective, this paradigm is resource-intensive and difficult to maintain, substantially complicating agent training and limiting scalability. We propose SWE-World, a Docker-free framework that replaces physical execution environments with a learned surrogate for training and evaluating software engineering agents. SWE-World leverages LLM-based models trained on real agent-environment interaction data to predict intermediate execution outcomes and final test feedback, enabling agents to learn without interacting with physical containerized environments. This design preserves the standard agent-environment interaction loop while eliminating the need for costly environment construction and maintenance during agent optimization and evaluation. Furthermore, because SWE-World can simulate the final evaluation outcomes of candidate trajectories without real submission, it enables selecting the best solution among multiple test-time attempts, thereby facilitating effective test-time scaling (TTS) in software engineering tasks. Experiments on SWE-bench Verified demonstrate that SWE-World raises Qwen2.5-Coder-32B from 6.2\% to 52.0\% via Docker-free SFT, 55.0\% with Docker-free RL, and 68.2\% with further TTS. The code is available at https://github.com/RUCAIBox/SWE-World
SWE-Master: Unleashing the Potential of Software Engineering Agents via Post-Training
Feb 03, 2026In this technical report, we present SWE-Master, an open-source and fully reproducible post-training framework for building effective software engineering agents. SWE-Master systematically explores the complete agent development pipeline, including teacher-trajectory synthesis and data curation, long-horizon SFT, RL with real execution feedback, and inference framework design. Starting from an open-source base model with limited initial SWE capability, SWE-Master demonstrates how systematical optimization method can elicit strong long-horizon SWE task solving abilities. We evaluate SWE-Master on SWE-bench Verified, a standard benchmark for realistic software engineering tasks. Under identical experimental settings, our approach achieves a resolve rate of 61.4\% with Qwen2.5-Coder-32B, substantially outperforming existing open-source baselines. By further incorporating test-time scaling~(TTS) with LLM-based environment feedback, SWE-Master reaches 70.8\% at TTS@8, demonstrating a strong performance potential. SWE-Master provides a practical and transparent foundation for advancing reproducible research on software engineering agents. The code is available at https://github.com/RUCAIBox/SWE-Master.
Sticker-TTS: Learn to Utilize Historical Experience with a Sticker-driven Test-Time Scaling Framework
Sep 05, 2025Large reasoning models (LRMs) have exhibited strong performance on complex reasoning tasks, with further gains achievable through increased computational budgets at inference. However, current test-time scaling methods predominantly rely on redundant sampling, ignoring the historical experience utilization, thereby limiting computational efficiency. To overcome this limitation, we propose Sticker-TTS, a novel test-time scaling framework that coordinates three collaborative LRMs to iteratively explore and refine solutions guided by historical attempts. At the core of our framework are distilled key conditions-termed stickers-which drive the extraction, refinement, and reuse of critical information across multiple rounds of reasoning. To further enhance the efficiency and performance of our framework, we introduce a two-stage optimization strategy that combines imitation learning with self-improvement, enabling progressive refinement. Extensive evaluations on three challenging mathematical reasoning benchmarks, including AIME-24, AIME-25, and OlymMATH, demonstrate that Sticker-TTS consistently surpasses strong baselines, including self-consistency and advanced reinforcement learning approaches, under comparable inference budgets. These results highlight the effectiveness of sticker-guided historical experience utilization. Our code and data are available at https://github.com/RUCAIBox/Sticker-TTS.
ManuSearch: Democratizing Deep Search in Large Language Models with a Transparent and Open Multi-Agent Framework
May 23, 2025Recent advances in web-augmented large language models (LLMs) have exhibited strong performance in complex reasoning tasks, yet these capabilities are mostly locked in proprietary systems with opaque architectures. In this work, we propose \textbf{ManuSearch}, a transparent and modular multi-agent framework designed to democratize deep search for LLMs. ManuSearch decomposes the search and reasoning process into three collaborative agents: (1) a solution planning agent that iteratively formulates sub-queries, (2) an Internet search agent that retrieves relevant documents via real-time web search, and (3) a structured webpage reading agent that extracts key evidence from raw web content. To rigorously evaluate deep reasoning abilities, we introduce \textbf{ORION}, a challenging benchmark focused on open-web reasoning over long-tail entities, covering both English and Chinese. Experimental results show that ManuSearch substantially outperforms prior open-source baselines and even surpasses leading closed-source systems. Our work paves the way for reproducible, extensible research in open deep search systems. We release the data and code in https://github.com/RUCAIBox/ManuSearch
SimpleDeepSearcher: Deep Information Seeking via Web-Powered Reasoning Trajectory Synthesis
May 22, 2025



Retrieval-augmented generation (RAG) systems have advanced large language models (LLMs) in complex deep search scenarios requiring multi-step reasoning and iterative information retrieval. However, existing approaches face critical limitations that lack high-quality training trajectories or suffer from the distributional mismatches in simulated environments and prohibitive computational costs for real-world deployment. This paper introduces SimpleDeepSearcher, a lightweight yet effective framework that bridges this gap through strategic data engineering rather than complex training paradigms. Our approach synthesizes high-quality training data by simulating realistic user interactions in live web search environments, coupled with a multi-criteria curation strategy that optimizes the diversity and quality of input and output side. Experiments on five benchmarks across diverse domains demonstrate that SFT on only 871 curated samples yields significant improvements over RL-based baselines. Our work establishes SFT as a viable pathway by systematically addressing the data-scarce bottleneck, offering practical insights for efficient deep search systems. Our code is available at https://github.com/RUCAIBox/SimpleDeepSearcher.
R1-Searcher++: Incentivizing the Dynamic Knowledge Acquisition of LLMs via Reinforcement Learning
May 22, 2025Large Language Models (LLMs) are powerful but prone to hallucinations due to static knowledge. Retrieval-Augmented Generation (RAG) helps by injecting external information, but current methods often are costly, generalize poorly, or ignore the internal knowledge of the model. In this paper, we introduce R1-Searcher++, a novel framework designed to train LLMs to adaptively leverage both internal and external knowledge sources. R1-Searcher++ employs a two-stage training strategy: an initial SFT Cold-start phase for preliminary format learning, followed by RL for Dynamic Knowledge Acquisition. The RL stage uses outcome-supervision to encourage exploration, incorporates a reward mechanism for internal knowledge utilization, and integrates a memorization mechanism to continuously assimilate retrieved information, thereby enriching the model's internal knowledge. By leveraging internal knowledge and external search engine, the model continuously improves its capabilities, enabling efficient retrieval-augmented reasoning. Our experiments demonstrate that R1-Searcher++ outperforms previous RAG and reasoning methods and achieves efficient retrieval. The code is available at https://github.com/RUCAIBox/R1-Searcher-plus.
CAFE: Retrieval Head-based Coarse-to-Fine Information Seeking to Enhance Multi-Document QA Capability
May 15, 2025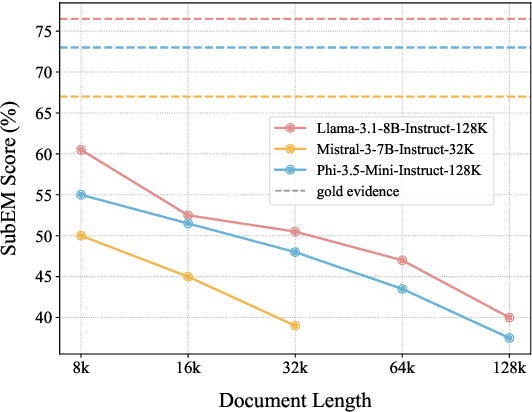


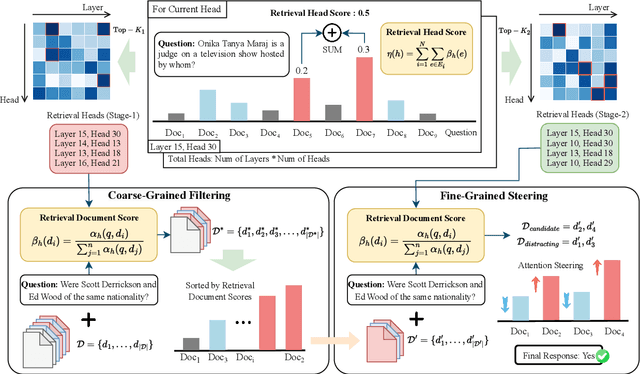
Advancements in Large Language Models (LLMs) have extended their input context length, yet they still struggle with retrieval and reasoning in long-context inputs. Existing methods propose to utilize the prompt strategy and retrieval head to alleviate this limitation. However, they still face challenges in balancing retrieval precision and recall, impacting their efficacy in answering questions. To address this, we introduce $\textbf{CAFE}$, a two-stage coarse-to-fine method to enhance multi-document question-answering capacities. By gradually eliminating the negative impacts of background and distracting documents, CAFE makes the responses more reliant on the evidence documents. Initially, a coarse-grained filtering method leverages retrieval heads to identify and rank relevant documents. Then, a fine-grained steering method guides attention to the most relevant content. Experiments across benchmarks show CAFE outperforms baselines, achieving up to 22.1% and 13.7% SubEM improvement over SFT and RAG methods on the Mistral model, respectively.
Embodied Intelligence: The Key to Unblocking Generalized Artificial Intelligence
May 11, 2025The ultimate goal of artificial intelligence (AI) is to achieve Artificial General Intelligence (AGI). Embodied Artificial Intelligence (EAI), which involves intelligent systems with physical presence and real-time interaction with the environment, has emerged as a key research direction in pursuit of AGI. While advancements in deep learning, reinforcement learning, large-scale language models, and multimodal technologies have significantly contributed to the progress of EAI, most existing reviews focus on specific technologies or applications. A systematic overview, particularly one that explores the direct connection between EAI and AGI, remains scarce. This paper examines EAI as a foundational approach to AGI, systematically analyzing its four core modules: perception, intelligent decision-making, action, and feedback. We provide a detailed discussion of how each module contributes to the six core principles of AGI. Additionally, we discuss future trends, challenges, and research directions in EAI, emphasizing its potential as a cornerstone for AGI development. Our findings suggest that EAI's integration of dynamic learning and real-world interaction is essential for bridging the gap between narrow AI and AGI.
RV-Syn: Rational and Verifiable Mathematical Reasoning Data Synthesis based on Structured Function Library
Apr 29, 2025The advancement of reasoning capabilities in Large Language Models (LLMs) requires substantial amounts of high-quality reasoning data, particularly in mathematics. Existing data synthesis methods, such as data augmentation from annotated training sets or direct question generation based on relevant knowledge points and documents, have expanded datasets but face challenges in mastering the inner logic of the problem during generation and ensuring the verifiability of the solutions. To address these issues, we propose RV-Syn, a novel Rational and Verifiable mathematical Synthesis approach. RV-Syn constructs a structured mathematical operation function library based on initial seed problems and generates computational graphs as solutions by combining Python-formatted functions from this library. These graphs are then back-translated into complex problems. Based on the constructed computation graph, we achieve solution-guided logic-aware problem generation. Furthermore, the executability of the computational graph ensures the verifiability of the solving process. Experimental results show that RV-Syn surpasses existing synthesis methods, including those involving human-generated problems, achieving greater efficient data scaling. This approach provides a scalable framework for generating high-quality reasoning datasets.
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
Mar 07, 2025



Existing Large Reasoning Models (LRMs) have shown the potential of reinforcement learning (RL) to enhance the complex reasoning capabilities of Large Language Models~(LLMs). While they achieve remarkable performance on challenging tasks such as mathematics and coding, they often rely on their internal knowledge to solve problems, which can be inadequate for time-sensitive or knowledge-intensive questions, leading to inaccuracies and hallucinations. To address this, we propose \textbf{R1-Searcher}, a novel two-stage outcome-based RL approach designed to enhance the search capabilities of LLMs. This method allows LLMs to autonomously invoke external search systems to access additional knowledge during the reasoning process. Our framework relies exclusively on RL, without requiring process rewards or distillation for a cold start. % effectively generalizing to out-of-domain datasets and supporting both Base and Instruct models. Our experiments demonstrate that our method significantly outperforms previous strong RAG methods, even when compared to the closed-source GPT-4o-mini.