 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Effective Code-Integrated Reasoning
May 30, 2025In this paper, we investigate code-integrated reasoning, where models generate code when necessary and integrate feedback by executing it through a code interpreter. To acquire this capability, models must learn when and how to use external code tools effectively, which is supported by tool-augmented reinforcement learning (RL) through interactive learning. Despite its benefits, tool-augmented RL can still suffer from potential instability in the learning dynamics. In light of this challenge, we present a systematic approach to improving the training effectiveness and stability of tool-augmented RL for code-integrated reasoning. Specifically, we develop enhanced training strategies that balance exploration and stability, progressively building tool-use capabilities while improving reasoning performance. Through extensive experiments on five mainstream mathematical reasoning benchmarks, our model demonstrates significant performance improvements over multiple competitive baselines. Furthermore, we conduct an in-depth analysis of the mechanism and effect of code-integrated reasoning, revealing several key insights, such as the extension of model's capability boundaries and the simultaneous improvement of reasoning efficiency through code integration. All data and code for reproducing this work are available at: https://github.com/RUCAIBox/CIR.
R1-Searcher++: Incentivizing the Dynamic Knowledge Acquisition of LLMs via Reinforcement Learning
May 22, 2025Large Language Models (LLMs) are powerful but prone to hallucinations due to static knowledge. Retrieval-Augmented Generation (RAG) helps by injecting external information, but current methods often are costly, generalize poorly, or ignore the internal knowledge of the model. In this paper, we introduce R1-Searcher++, a novel framework designed to train LLMs to adaptively leverage both internal and external knowledge sources. R1-Searcher++ employs a two-stage training strategy: an initial SFT Cold-start phase for preliminary format learning, followed by RL for Dynamic Knowledge Acquisition. The RL stage uses outcome-supervision to encourage exploration, incorporates a reward mechanism for internal knowledge utilization, and integrates a memorization mechanism to continuously assimilate retrieved information, thereby enriching the model's internal knowledge. By leveraging internal knowledge and external search engine, the model continuously improves its capabilities, enabling efficient retrieval-augmented reasoning. Our experiments demonstrate that R1-Searcher++ outperforms previous RAG and reasoning methods and achieves efficient retrieval. The code is available at https://github.com/RUCAIBox/R1-Searcher-plus.
SimpleDeepSearcher: Deep Information Seeking via Web-Powered Reasoning Trajectory Synthesis
May 22, 2025



Retrieval-augmented generation (RAG) systems have advanced large language models (LLMs) in complex deep search scenarios requiring multi-step reasoning and iterative information retrieval. However, existing approaches face critical limitations that lack high-quality training trajectories or suffer from the distributional mismatches in simulated environments and prohibitive computational costs for real-world deployment. This paper introduces SimpleDeepSearcher, a lightweight yet effective framework that bridges this gap through strategic data engineering rather than complex training paradigms. Our approach synthesizes high-quality training data by simulating realistic user interactions in live web search environments, coupled with a multi-criteria curation strategy that optimizes the diversity and quality of input and output side. Experiments on five benchmarks across diverse domains demonstrate that SFT on only 871 curated samples yields significant improvements over RL-based baselines. Our work establishes SFT as a viable pathway by systematically addressing the data-scarce bottleneck, offering practical insights for efficient deep search systems. Our code is available at https://github.com/RUCAIBox/SimpleDeepSearcher.
CAFE: Retrieval Head-based Coarse-to-Fine Information Seeking to Enhance Multi-Document QA Capability
May 15, 2025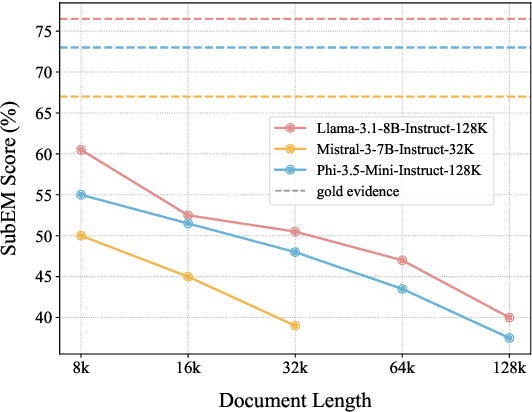


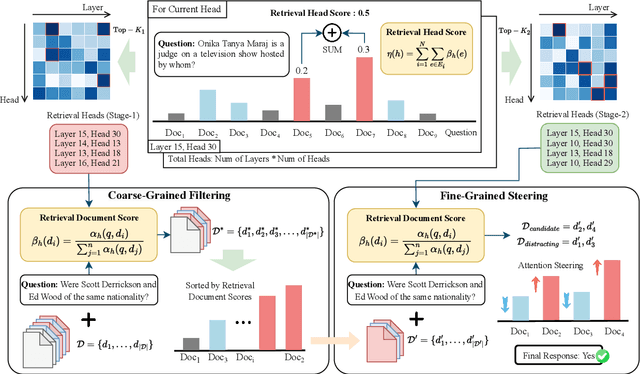
Advancements in Large Language Models (LLMs) have extended their input context length, yet they still struggle with retrieval and reasoning in long-context inputs. Existing methods propose to utilize the prompt strategy and retrieval head to alleviate this limitation. However, they still face challenges in balancing retrieval precision and recall, impacting their efficacy in answering questions. To address this, we introduce $\textbf{CAFE}$, a two-stage coarse-to-fine method to enhance multi-document question-answering capacities. By gradually eliminating the negative impacts of background and distracting documents, CAFE makes the responses more reliant on the evidence documents. Initially, a coarse-grained filtering method leverages retrieval heads to identify and rank relevant documents. Then, a fine-grained steering method guides attention to the most relevant content. Experiments across benchmarks show CAFE outperforms baselines, achieving up to 22.1% and 13.7% SubEM improvement over SFT and RAG methods on the Mistral model, respectively.
Rethinking Invariance in In-context Learning
May 08, 2025In-Context Learning (ICL) has emerged as a pivotal capability of auto-regressive large language models, yet it is hindered by a notable sensitivity to the ordering of context examples regardless of their mutual independence. To address this issue, recent studies have introduced several variant algorithms of ICL that achieve permutation invariance. However, many of these do not exhibit comparable performance with the standard auto-regressive ICL algorithm. In this work, we identify two crucial elements in the design of an invariant ICL algorithm: information non-leakage and context interdependence, which are not simultaneously achieved by any of the existing methods. These investigations lead us to the proposed Invariant ICL (InvICL), a methodology designed to achieve invariance in ICL while ensuring the two properties. Empirically, our findings reveal that InvICL surpasses previous models, both invariant and non-invariant, in most benchmark datasets, showcasing superior generalization capabilities across varying input lengths. Code is available at https://github.com/PKU-ML/InvICL.
Challenging the Boundaries of Reasoning: An Olympiad-Level Math Benchmark for Large Language Models
Mar 27, 2025



In recent years, the rapid development of large reasoning models has resulted in the saturation of existing benchmarks for evaluating mathematical reasoning, highlighting the urgent need for more challenging and rigorous evaluation frameworks. To address this gap, we introduce OlymMATH, a novel Olympiad-level mathematical benchmark, designed to rigorously test the complex reasoning capabilities of LLMs. OlymMATH features 200 meticulously curated problems, each manually verified and available in parallel English and Chinese versions. The problems are systematically organized into two distinct difficulty tiers: (1) AIME-level problems (easy) that establish a baseline for mathematical reasoning assessment, and (2) significantly more challenging problems (hard) designed to push the boundaries of current state-of-the-art models. In our benchmark, these problems span four core mathematical fields, each including a verifiable numerical solution to enable objective, rule-based evaluation. Empirical results underscore the significant challenge presented by OlymMATH, with state-of-the-art models including DeepSeek-R1 and OpenAI's o3-mini demonstrating notably limited accuracy on the hard subset. Furthermore, the benchmark facilitates comprehensive bilingual assessment of mathematical reasoning abilities-a critical dimension that remains largely unaddressed in mainstream mathematical reasoning benchmarks. We release the OlymMATH benchmark at the STILL project: https://github.com/RUCAIBox/Slow_Thinking_with_LLMs.
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
Mar 07, 2025



Existing Large Reasoning Models (LRMs) have shown the potential of reinforcement learning (RL) to enhance the complex reasoning capabilities of Large Language Models~(LLMs). While they achieve remarkable performance on challenging tasks such as mathematics and coding, they often rely on their internal knowledge to solve problems, which can be inadequate for time-sensitive or knowledge-intensive questions, leading to inaccuracies and hallucinations. To address this, we propose \textbf{R1-Searcher}, a novel two-stage outcome-based RL approach designed to enhance the search capabilities of LLMs. This method allows LLMs to autonomously invoke external search systems to access additional knowledge during the reasoning process. Our framework relies exclusively on RL, without requiring process rewards or distillation for a cold start. % effectively generalizing to out-of-domain datasets and supporting both Base and Instruct models. Our experiments demonstrate that our method significantly outperforms previous strong RAG methods, even when compared to the closed-source GPT-4o-mini.
An Empirical Study on Eliciting and Improving R1-like Reasoning Models
Mar 06, 2025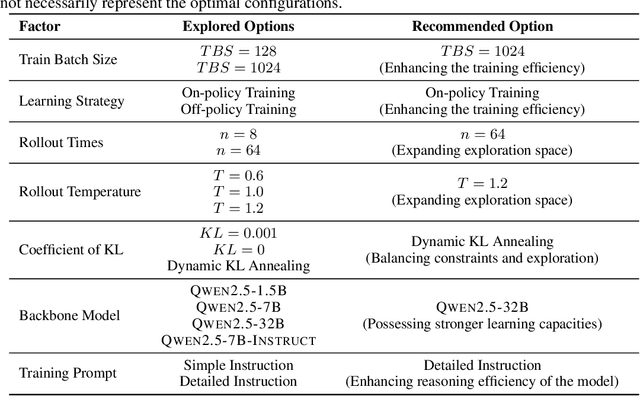
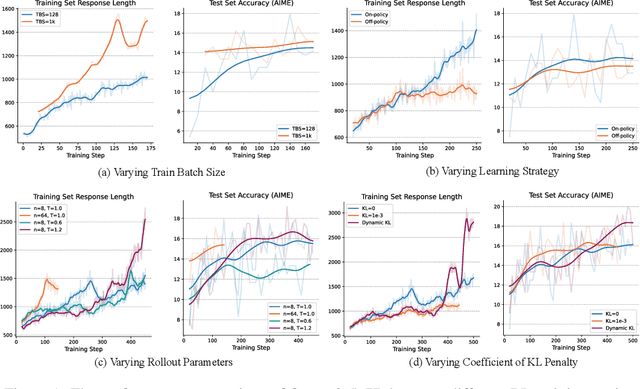
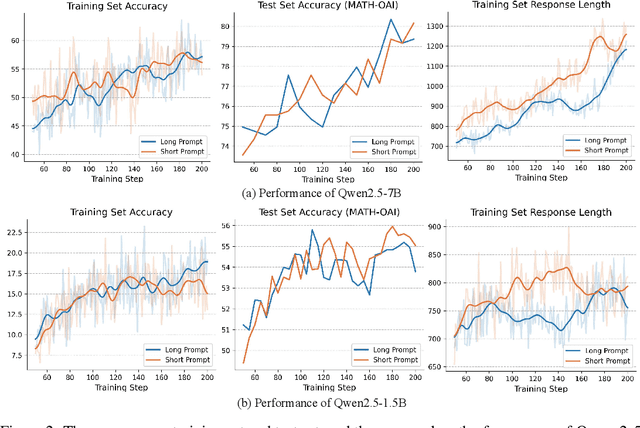

In this report, we present the third technical report on the development of slow-thinking models as part of the STILL project. As the technical pathway becomes clearer, scaling RL training has become a central technique for implementing such reasoning models. We systematically experiment with and document the effects of various factors influencing RL training, conducting experiments on both base models and fine-tuned models. Specifically, we demonstrate that our RL training approach consistently improves the Qwen2.5-32B base models, enhancing both response length and test accuracy. Furthermore, we show that even when a model like DeepSeek-R1-Distill-Qwen-1.5B has already achieved a high performance level, it can be further refined through RL training, reaching an accuracy of 39.33% on AIME 2024. Beyond RL training, we also explore the use of tool manipulation, finding that it significantly boosts the reasoning performance of large reasoning models. This approach achieves a remarkable accuracy of 86.67% with greedy search on AIME 2024, underscoring its effectiveness in enhancing model capabilities. We release our resources at the STILL project website: https://github.com/RUCAIBox/Slow_Thinking_with_LLMs.
Accurate Forgetting for Heterogeneous Federated Continual Learning
Feb 20, 2025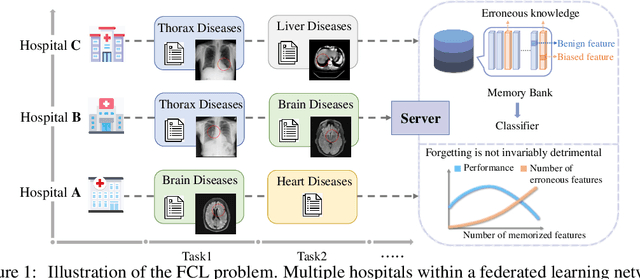
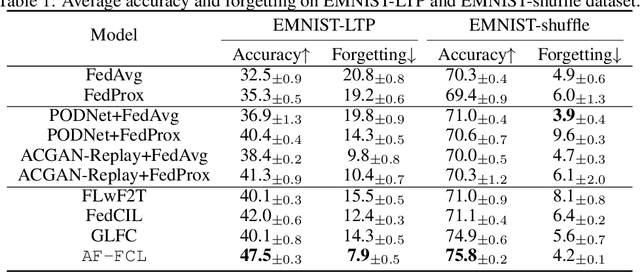
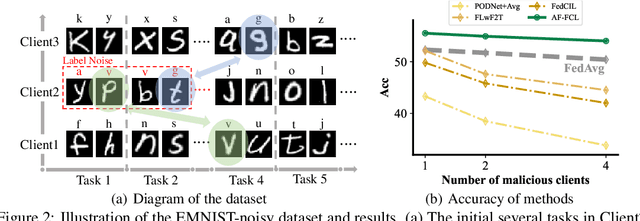
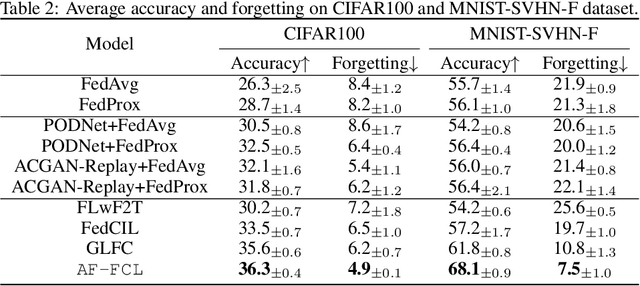
Recent years have witnessed a burgeoning interest in federated learning (FL). However, the contexts in which clients engage in sequential learning remain under-explored. Bridging FL and continual learning (CL) gives rise to a challenging practical problem: federated continual learning (FCL). Existing research in FCL primarily focuses on mitigating the catastrophic forgetting issue of continual learning while collaborating with other clients. We argue that the forgetting phenomena are not invariably detrimental. In this paper, we consider a more practical and challenging FCL setting characterized by potentially unrelated or even antagonistic data/tasks across different clients. In the FL scenario, statistical heterogeneity and data noise among clients may exhibit spurious correlations which result in biased feature learning. While existing CL strategies focus on a complete utilization of previous knowledge, we found that forgetting biased information is beneficial in our study. Therefore, we propose a new concept accurate forgetting (AF) and develop a novel generative-replay method~\method~which selectively utilizes previous knowledge in federated networks. We employ a probabilistic framework based on a normalizing flow model to quantify the credibility of previous knowledge. Comprehensive experiments affirm the superiority of our method over baselines.
Detect Changes like Humans: Incorporating Semantic Priors for Improved Change Detection
Dec 22, 2024



When given two similar images, humans identify their differences by comparing the appearance ({\it e.g., color, texture}) with the help of semantics ({\it e.g., objects, relations}). However, mainstream change detection models adopt a supervised training paradigm, where the annotated binary change map is the main constraint. Thus, these methods primarily emphasize the difference-aware features between bi-temporal images and neglect the semantic understanding of the changed landscapes, which undermines the accuracy in the presence of noise and illumination variations. To this end, this paper explores incorporating semantic priors to improve the ability to detect changes. Firstly, we propose a Semantic-Aware Change Detection network, namely SA-CDNet, which transfers the common knowledge of the visual foundation models ({\it i.e., FastSAM}) to change detection. Inspired by the human visual paradigm, a novel dual-stream feature decoder is derived to distinguish changes by combining semantic-aware features and difference-aware features. Secondly, we design a single-temporal semantic pre-training strategy to enhance the semantic understanding of landscapes, which brings further increments. Specifically, we construct pseudo-change detection data from public single-temporal remote sensing segmentation datasets for large-scale pre-training, where an extra branch is also introduced for the proxy semantic segmentation task. Experimental results on five challenging benchmarks demonstrate the superiority of our method over the existing state-of-the-art methods. The code is available at \href{https://github.com/thislzm/SA-CD}{SA-CD}.