 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Context or Local Detail? Adaptive Visual Grounding for Hallucination Mitigation
Apr 27, 2026Vision-Language Models (VLMs) are frequently undermined by object hallucination--generating content that contradicts visual reality--due to an over-reliance on linguistic priors. We introduce Positive-and-Negative Decoding (PND), a training-free inference framework that intervenes directly in the decoding process to enforce visual fidelity. PND is motivated by our key finding of a critical attention deficit in VLMs, where visual features are empirically under-weighted. Our framework corrects this via a dual-path contrast: The positive path amplifies salient visual evidence using multi-layer attention to encourage faithful descriptions, directly counteracting the attention deficit. Simultaneously, the negative path identifies and degrades the core object's features to create a strong counterfactual, which penalizes ungrounded, prior-dominant generation. By contrasting the model's outputs from these two perspectives at each step, PND steers generation towards text that is not just linguistically probable, but visually factual. Extensive experiments on benchmarks like POPE, MME, and CHAIR show that PND achieves state-of-the-art performance with up to 6.5% accuracy improvement, substantially reducing object hallucination while also enhancing descriptive detail--all without requiring any model retraining. The method generalizes effectively across diverse VLM architectures including LLaVA, InstructBLIP, InternVL, and Qwen-VL.
V-tableR1: Process-Supervised Multimodal Table Reasoning with Critic-Guided Policy Optimization
Apr 22, 2026We introduce V-tableR1, a process-supervised reinforcement learning framework that elicits rigorous, verifiable reasoning from multimodal large language models (MLLMs). Current MLLMs trained solely on final outcomes often treat visual reasoning as a black box, relying on superficial pattern matching rather than performing rigorous multi-step inference. While Reinforcement Learning with Verifiable Rewards could enforce transparent reasoning trajectories, extending it to visual domains remains severely hindered by the ambiguity of grounding abstract logic into continuous pixel space. We solve this by leveraging the deterministic grid structure of tables as an ideal visual testbed. V-tableR1 employs a specialized critic VLM to provide dense, step-level feedback on the explicit visual chain-of-thought generated by a policy VLM. To optimize this system, we propose Process-Guided Direct Alignment Policy Optimization (PGPO), a novel RL algorithm integrating process rewards, decoupled policy constraints, and length-aware dynamic sampling. Extensive evaluations demonstrate that V-tableR1 explicitly penalizes visual hallucinations and shortcut guessing. By fundamentally shifting multimodal inference from black-box pattern matching to verifiable logical derivation, V-tableR1 4B establishes state-of-the-art accuracy among open-source models on complex tabular benchmarks, outperforming models up to 18x its size and improving over its SFT baseline
Learning without Isolation: Pathway Protection for Continual Learning
May 24, 2025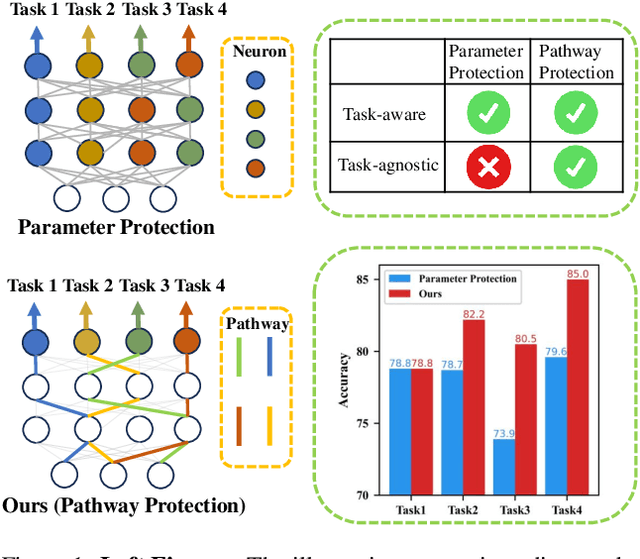
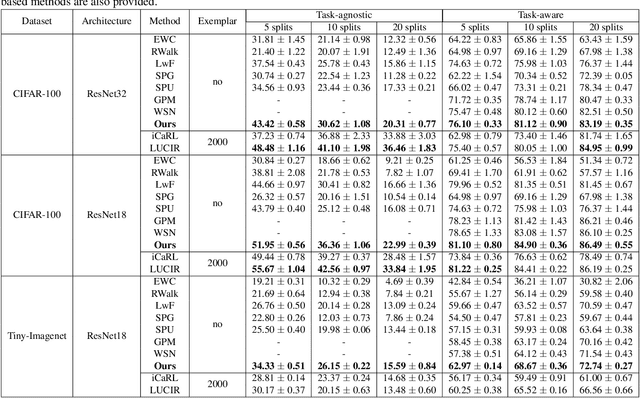
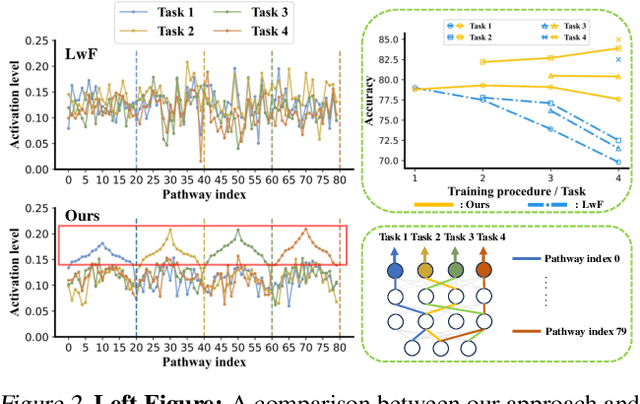
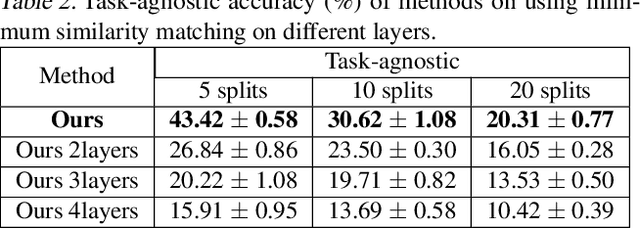
Deep networks are prone to catastrophic forgetting during sequential task learning, i.e., losing the knowledge about old tasks upon learning new tasks. To this end, continual learning(CL) has emerged, whose existing methods focus mostly on regulating or protecting the parameters associated with the previous tasks. However, parameter protection is often impractical, since the size of parameters for storing the old-task knowledge increases linearly with the number of tasks, otherwise it is hard to preserve the parameters related to the old-task knowledge. In this work, we bring a dual opinion from neuroscience and physics to CL: in the whole networks, the pathways matter more than the parameters when concerning the knowledge acquired from the old tasks. Following this opinion, we propose a novel CL framework, learning without isolation(LwI), where model fusion is formulated as graph matching and the pathways occupied by the old tasks are protected without being isolated. Thanks to the sparsity of activation channels in a deep network, LwI can adaptively allocate available pathways for a new task, realizing pathway protection and addressing catastrophic forgetting in a parameter-efficient manner. Experiments on popular benchmark datasets demonstrate the superiority of the proposed LwI.
Accurate Forgetting for Heterogeneous Federated Continual Learning
Feb 20, 2025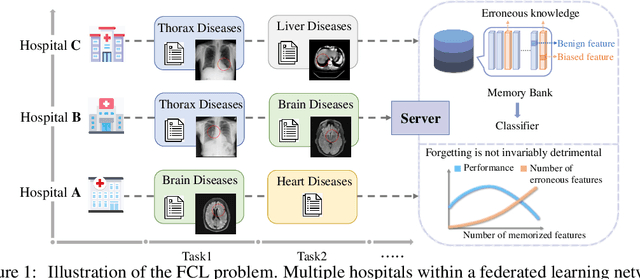
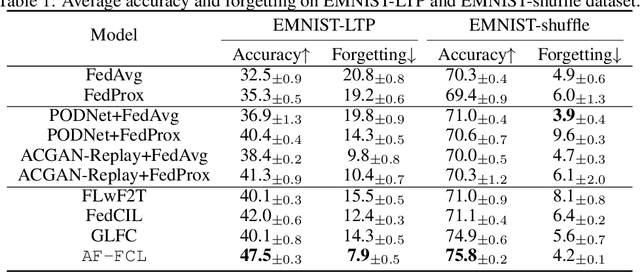
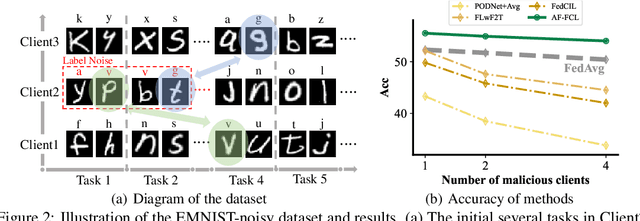
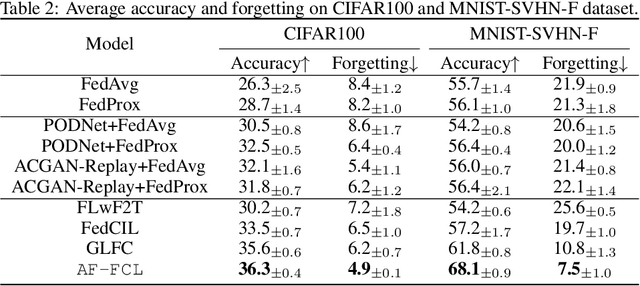
Recent years have witnessed a burgeoning interest in federated learning (FL). However, the contexts in which clients engage in sequential learning remain under-explored. Bridging FL and continual learning (CL) gives rise to a challenging practical problem: federated continual learning (FCL). Existing research in FCL primarily focuses on mitigating the catastrophic forgetting issue of continual learning while collaborating with other clients. We argue that the forgetting phenomena are not invariably detrimental. In this paper, we consider a more practical and challenging FCL setting characterized by potentially unrelated or even antagonistic data/tasks across different clients. In the FL scenario, statistical heterogeneity and data noise among clients may exhibit spurious correlations which result in biased feature learning. While existing CL strategies focus on a complete utilization of previous knowledge, we found that forgetting biased information is beneficial in our study. Therefore, we propose a new concept accurate forgetting (AF) and develop a novel generative-replay method~\method~which selectively utilizes previous knowledge in federated networks. We employ a probabilistic framework based on a normalizing flow model to quantify the credibility of previous knowledge. Comprehensive experiments affirm the superiority of our method over baselines.
Beyond Similarity: Personalized Federated Recommendation with Composite Aggregation
Jun 06, 2024Federated recommendation aims to collect global knowledge by aggregating local models from massive devices, to provide recommendations while ensuring privacy. Current methods mainly leverage aggregation functions invented by federated vision community to aggregate parameters from similar clients, e.g., clustering aggregation. Despite considerable performance, we argue that it is suboptimal to apply them to federated recommendation directly. This is mainly reflected in the disparate model architectures. Different from structured parameters like convolutional neural networks in federated vision, federated recommender models usually distinguish itself by employing one-to-one item embedding table. Such a discrepancy induces the challenging embedding skew issue, which continually updates the trained embeddings but ignores the non-trained ones during aggregation, thus failing to predict future items accurately. To this end, we propose a personalized Federated recommendation model with Composite Aggregation (FedCA), which not only aggregates similar clients to enhance trained embeddings, but also aggregates complementary clients to update non-trained embeddings. Besides, we formulate the overall learning process into a unified optimization algorithm to jointly learn the similarity and complementarity. Extensive experiments on several real-world datasets substantiate the effectiveness of our proposed model. The source codes are available at https://github.com/hongleizhang/FedCA.
Balancing Similarity and Complementarity for Federated Learning
May 16, 2024



In mobile and IoT systems, Federated Learning (FL) is increasingly important for effectively using data while maintaining user privacy. One key challenge in FL is managing statistical heterogeneity, such as non-i.i.d. data, arising from numerous clients and diverse data sources. This requires strategic cooperation, often with clients having similar characteristics. However, we are interested in a fundamental question: does achieving optimal cooperation necessarily entail cooperating with the most similar clients? Typically, significant model performance improvements are often realized not by partnering with the most similar models, but through leveraging complementary data. Our theoretical and empirical analyses suggest that optimal cooperation is achieved by enhancing complementarity in feature distribution while restricting the disparity in the correlation between features and targets. Accordingly, we introduce a novel framework, \texttt{FedSaC}, which balances similarity and complementarity in FL cooperation. Our framework aims to approximate an optimal cooperation network for each client by optimizing a weighted sum of model similarity and feature complementarity. The strength of \texttt{FedSaC} lies in its adaptability to various levels of data heterogeneity and multimodal scenarios. Our comprehensive unimodal and multimodal experiments demonstrate that \texttt{FedSaC} markedly surpasses other state-of-the-art FL methods.
MetaAge: Meta-Learning Personalized Age Estimators
Jul 12, 2022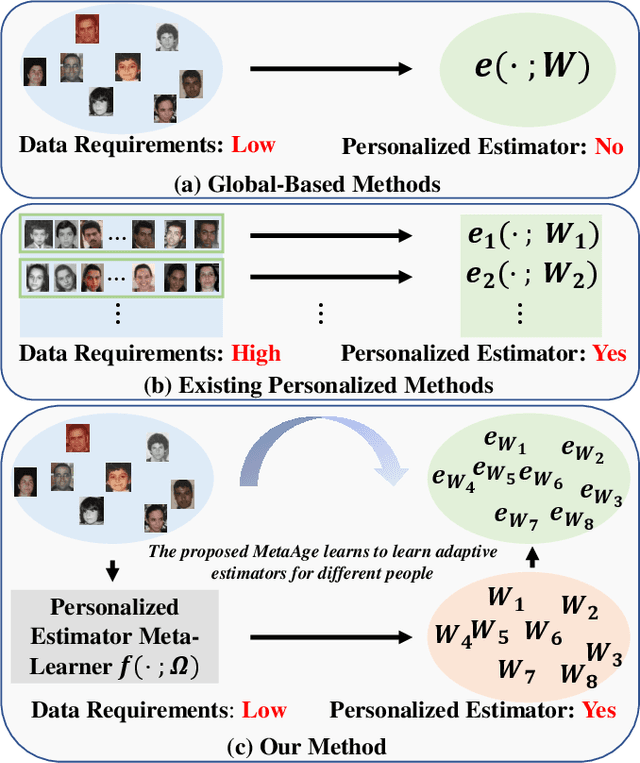
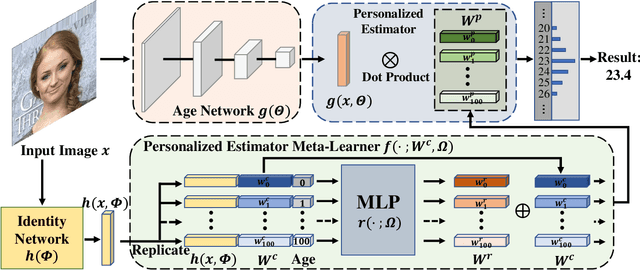
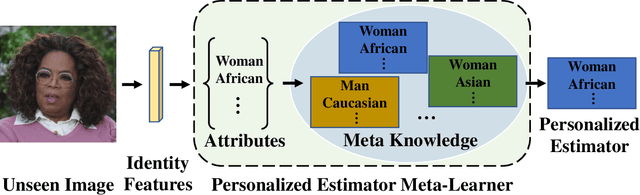
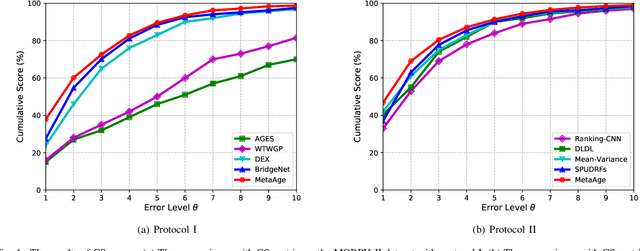
Different people age in different ways. Learning a personalized age estimator for each person is a promising direction for age estimation given that it better models the personalization of aging processes. However, most existing personalized methods suffer from the lack of large-scale datasets due to the high-level requirements: identity labels and enough samples for each person to form a long-term aging pattern. In this paper, we aim to learn personalized age estimators without the above requirements and propose a meta-learning method named MetaAge for age estimation. Unlike most existing personalized methods that learn the parameters of a personalized estimator for each person in the training set, our method learns the mapping from identity information to age estimator parameters. Specifically, we introduce a personalized estimator meta-learner, which takes identity features as the input and outputs the parameters of customized estimators. In this way, our method learns the meta knowledge without the above requirements and seamlessly transfers the learned meta knowledge to the test set, which enables us to leverage the existing large-scale age datasets without any additional annotations. Extensive experimental results on three benchmark datasets including MORPH II, ChaLearn LAP 2015 and ChaLearn LAP 2016 databases demonstrate that our MetaAge significantly boosts the performance of existing personalized methods and outperforms the state-of-the-art approaches.
Rethinking Audio-visual Synchronization for Active Speaker Detection
Jun 21, 2022
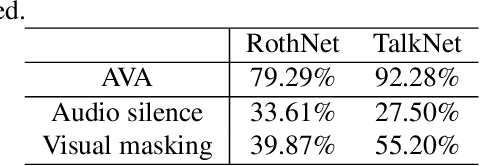

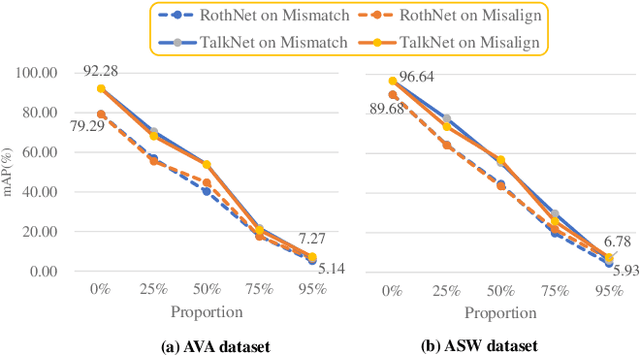
Active speaker detection (ASD) systems are important modules for analyzing multi-talker conversations. They aim to detect which speakers or none are talking in a visual scene at any given time. Existing research on ASD does not agree on the definition of active speakers. We clarify the definition in this work and require synchronization between the audio and visual speaking activities. This clarification of definition is motivated by our extensive experiments, through which we discover that existing ASD methods fail in modeling the audio-visual synchronization and often classify unsynchronized videos as active speaking. To address this problem, we propose a cross-modal contrastive learning strategy and apply positional encoding in attention modules for supervised ASD models to leverage the synchronization cue. Experimental results suggest that our model can successfully detect unsynchronized speaking as not speaking, addressing the limitation of current models.
Reasoning Graph Networks for Kinship Verification: from Star-shaped to Hierarchical
Sep 06, 2021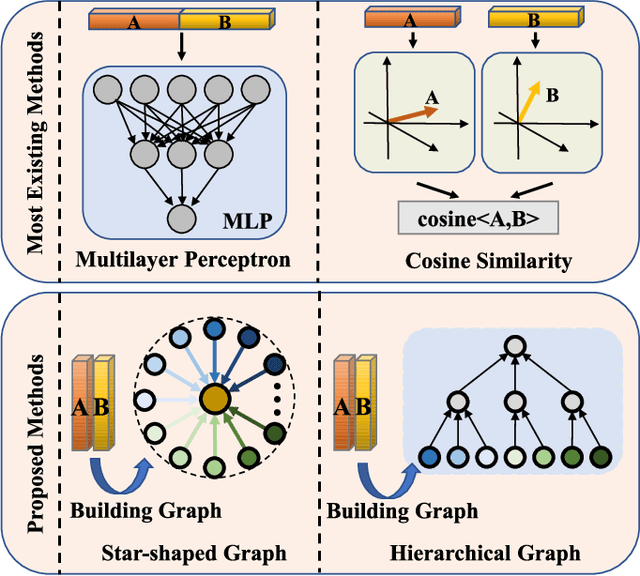
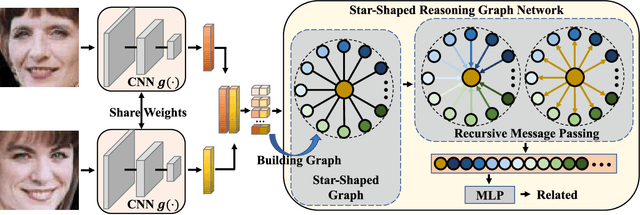

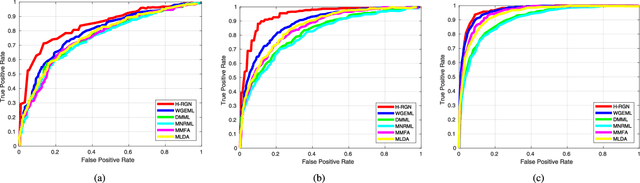
In this paper, we investigate the problem of facial kinship verification by learning hierarchical reasoning graph networks. Conventional methods usually focus on learning discriminative features for each facial image of a paired sample and neglect how to fuse the obtained two facial image features and reason about the relations between them. To address this, we propose a Star-shaped Reasoning Graph Network (S-RGN). Our S-RGN first constructs a star-shaped graph where each surrounding node encodes the information of comparisons in a feature dimension and the central node is employed as the bridge for the interaction of surrounding nodes. Then we perform relational reasoning on this star graph with iterative message passing. The proposed S-RGN uses only one central node to analyze and process information from all surrounding nodes, which limits its reasoning capacity. We further develop a Hierarchical Reasoning Graph Network (H-RGN) to exploit more powerful and flexible capacity. More specifically, our H-RGN introduces a set of latent reasoning nodes and constructs a hierarchical graph with them. Then bottom-up comparative information abstraction and top-down comprehensive signal propagation are iteratively performed on the hierarchical graph to update the node features. Extensive experimental results on four widely used kinship databases show that the proposed methods achieve very competitive results.
* Accepted by IEEE Transactions on Image Processing (TIP)