 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasonAudio: A Benchmark for Evaluating Reasoning Beyond Matching in Text-Audio Retrieval
May 05, 2026As multimodal content continues to expand at a rapid pace, audio retrieval has emerged as a key enabling technology for media search, content organization, and intelligent assistants. However, most existing benchmarks concentrate on semantic matching and fail to capture the fact that real-world queries often demand advanced reasoning abilities, including negation understanding, temporal ordering, concurrent event recognition, and duration discrimination. To address this gap, we introduce ReasonAudio, the first reasoning-intensive benchmark for Text-Audio Retrieval, comprising 1,000 queries and 10,000 composite audio clips across five fundamental reasoning tasks: Negation, Order, Overlap, Duration, and Mix. Despite their intuitive nature for humans and straightforward construction, these tasks pose significant challenges to current models. Our evaluation of ten state-of-the-art models reveals the following findings: All models struggle with reasoning-intensive audio retrieval, performing particularly poorly on Negation and Duration while showing relatively better results on Overlap and Order. Moreover, Multimodal Large Language Model-based embedding models fail to inherit the reasoning capabilities of their backbones through contrastive fine-tuning, suggesting that current training paradigms are insufficient to preserve reasoning capacity in retrieval settings
From Transfer to Collaboration: A Federated Framework for Cross-Market Sequential Recommendation
Apr 15, 2026Cross-market recommendation (CMR) aims to enhance recommendation performance across multiple markets. Due to its inherent characteristics, i.e., data isolation, non-overlapping users, and market heterogeneity, CMR introduces unique challenges and fundamentally differs from cross-domain recommendation (CDR). Existing CMR approaches largely inherit CDR by adopting the one-to-one transfer paradigm, where a model is pretrained on a source market and then fine-tuned on a target market. However, such a paradigm suffers from CH1. source degradation, where the source market sacrifices its own performance for the target markets, and CH2. negative transfer, where market heterogeneity leads to suboptimal performance in target markets. To address these challenges, we propose FeCoSR, a novel federated collaboration framework for cross-market sequential recommendation. Specifically, to tackle CH1, we introduce a many-to-many collaboration paradigm that enables all markets to jointly participate in and benefit from training. It consists of a federated pretraining stage for capturing shared behavior-level patterns, followed by local fine-tuning for market-specific item-level preferences. For CH2, we theoretically and empirically show that vanilla Cross-Entropy (CE) exacerbates market heterogeneity, undermining federated optimization. To address this, we propose a Semantic Soft Cross-Entropy (S^2CE) that leverages shared semantic information to facilitate collaborative behavioral learning across markets. Then, we design a market-specific adaptation module during fine-tuning to capture local item preferences. Extensive experiments on the real-world datasets demonstrate the advantages of FeCoSR over other methods.
MDiffFR: Modality-Guided Diffusion Generation for Cold-start Items in Federated Recommendation
Dec 31, 2025Federated recommendations (FRs) provide personalized services while preserving user privacy by keeping user data on local clients, which has attracted significant attention in recent years. However, due to the strict privacy constraints inherent in FRs, access to user-item interaction data and user profiles across clients is highly restricted, making it difficult to learn globally effective representations for new (cold-start) items. Consequently, the item cold-start problem becomes even more challenging in FRs. Existing solutions typically predict embeddings for new items through the attribute-to-embedding mapping paradigm, which establishes a fixed one-to-one correspondence between item attributes and their embeddings. However, this one-to-one mapping paradigm often fails to model varying data distributions and tends to cause embedding misalignment, as verified by our empirical studies. To this end, we propose MDiffFR, a novel generation-based modality-guided diffusion method for cold-start items in FRs. In this framework, we employ a tailored diffusion model on the server to generate embeddings for new items, which are then distributed to clients for cold-start inference. To align item semantics, we deploy a pre-trained modality encoder to extract modality features as conditional signals to guide the reverse denoising process. Furthermore, our theoretical analysis verifies that the proposed method achieves stronger privacy guarantees compared to existing mapping-based approaches. Extensive experiments on four real datasets demonstrate that our method consistently outperforms all baselines in FRs.
Learn to Preserve Personality: Federated Foundation Models in Recommendations
Jun 13, 2025A core learning challenge for existed Foundation Models (FM) is striking the tradeoff between generalization with personalization, which is a dilemma that has been highlighted by various parameter-efficient adaptation techniques. Federated foundation models (FFM) provide a structural means to decouple shared knowledge from individual specific adaptations via decentralized processes. Recommendation systems offer a perfect testbed for FFMs, given their reliance on rich implicit feedback reflecting unique user characteristics. This position paper discusses a novel learning paradigm where FFMs not only harness their generalization capabilities but are specifically designed to preserve the integrity of user personality, illustrated thoroughly within the recommendation contexts. We envision future personal agents, powered by personalized adaptive FMs, guiding user decisions on content. Such an architecture promises a user centric, decentralized system where individuals maintain control over their personalized agents.
CoDTS: Enhancing Sparsely Supervised Collaborative Perception with a Dual Teacher-Student Framework
Dec 12, 2024



Current collaborative perception methods often rely on fully annotated datasets, which can be expensive to obtain in practical situations. To reduce annotation costs, some works adopt sparsely supervised learning techniques and generate pseudo labels for the missing instances. However, these methods fail to achieve an optimal confidence threshold that harmonizes the quality and quantity of pseudo labels. To address this issue, we propose an end-to-end Collaborative perception Dual Teacher-Student framework (CoDTS), which employs adaptive complementary learning to produce both high-quality and high-quantity pseudo labels. Specifically, the Main Foreground Mining (MFM) module generates high-quality pseudo labels based on the prediction of the static teacher. Subsequently, the Supplement Foreground Mining (SFM) module ensures a balance between the quality and quantity of pseudo labels by adaptively identifying missing instances based on the prediction of the dynamic teacher. Additionally, the Neighbor Anchor Sampling (NAS) module is incorporated to enhance the representation of pseudo labels. To promote the adaptive complementary learning, we implement a staged training strategy that trains the student and dynamic teacher in a mutually beneficial manner. Extensive experiments demonstrate that the CoDTS effectively ensures an optimal balance of pseudo labels in both quality and quantity, establishing a new state-of-the-art in sparsely supervised collaborative perception.
A Tutorial of Personalized Federated Recommender Systems: Recent Advances and Future Directions
Dec 11, 2024Personalization stands as the cornerstone of recommender systems (RecSys), striving to sift out redundant information and offer tailor-made services for users. However, the conventional cloud-based RecSys necessitates centralized data collection, posing significant risks of user privacy breaches. In response to this challenge, federated recommender systems (FedRecSys) have emerged, garnering considerable attention. FedRecSys enable users to retain personal data locally and solely share model parameters with low privacy sensitivity for global model training, significantly bolstering the system's privacy protection capabilities. Within the distributed learning framework, the pronounced non-iid nature of user behavior data introduces fresh hurdles to federated optimization. Meanwhile, the ability of federated learning to concurrently learn multiple models presents an opportunity for personalized user modeling. Consequently, the development of personalized FedRecSys (PFedRecSys) is crucial and holds substantial significance. This tutorial seeks to provide an introduction to PFedRecSys, encompassing (1) an overview of existing studies on PFedRecSys, (2) a comprehensive taxonomy of PFedRecSys spanning four pivotal research directions-client-side adaptation, server-side aggregation, communication efficiency, privacy and protection, and (3) exploration of open challenges and promising future directions in PFedRecSys. This tutorial aims to establish a robust foundation and spark new perspectives for subsequent exploration and practical implementations in the evolving realm of RecSys.
Learning to Hash for Recommendation: A Survey
Dec 05, 2024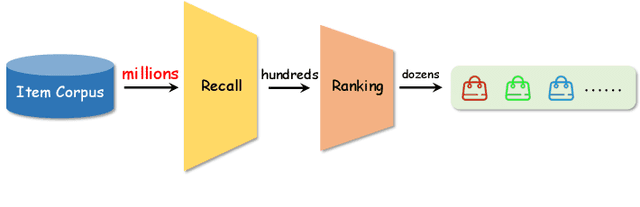
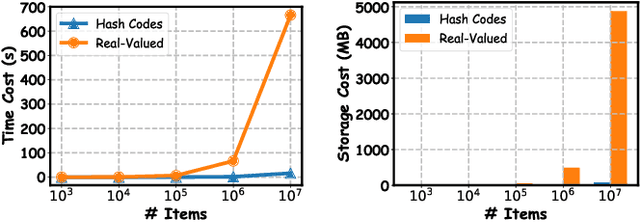
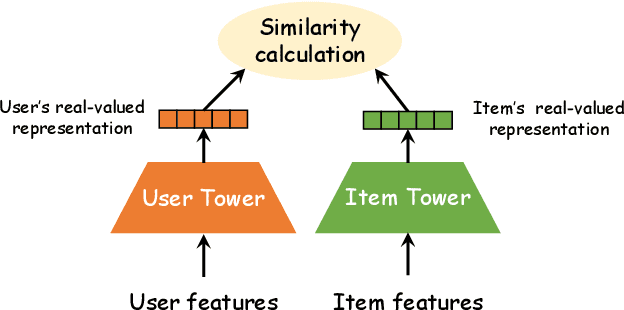
With the explosive growth of users and items, Recommender Systems (RS) are facing unprecedented challenges on both retrieval efficiency and storage cost. Fortunately, Learning to Hash (L2H) techniques have been shown as a promising solution to address the two dilemmas, whose core idea is encoding high-dimensional data into compact hash codes. To this end, L2H for RS (HashRec for short) has recently received widespread attention to support large-scale recommendations. In this survey, we present a comprehensive review of current HashRec algorithms. Specifically, we first introduce the commonly used two-tower models in the recall stage and identify two search strategies frequently employed in L2H. Then, we categorize prior works into two-tier taxonomy based on: (i) the type of loss function and (ii) the optimization strategy. We also introduce some commonly used evaluation metrics to measure the performance of HashRec algorithms. Finally, we shed light on the limitations of the current research and outline the future research directions. Furthermore, the summary of HashRec methods reviewed in this survey can be found at \href{https://github.com/Luo-Fangyuan/HashRec}{https://github.com/Luo-Fangyuan/HashRec}.
Advancing Sustainability via Recommender Systems: A Survey
Nov 12, 2024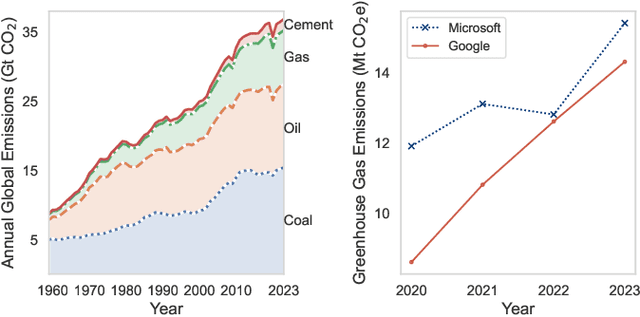
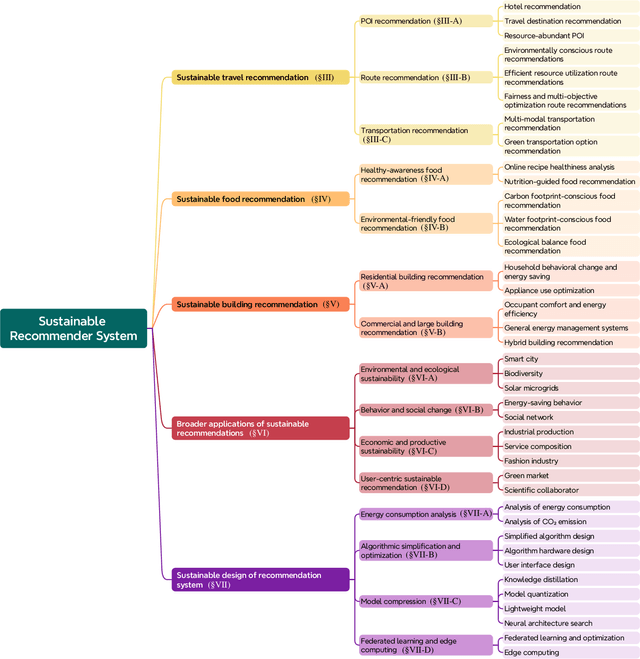
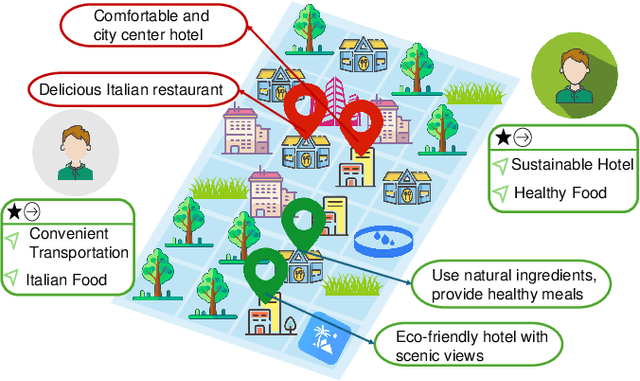
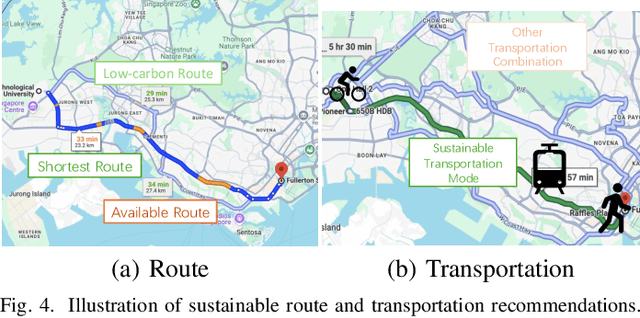
Human behavioral patterns and consumption paradigms have emerged as pivotal determinants in environmental degradation and climate change, with quotidian decisions pertaining to transportation, energy utilization, and resource consumption collectively precipitating substantial ecological impacts. Recommender systems, which generate personalized suggestions based on user preferences and historical interaction data, exert considerable influence on individual behavioral trajectories. However, conventional recommender systems predominantly optimize for user engagement and economic metrics, inadvertently neglecting the environmental and societal ramifications of their recommendations, potentially catalyzing over-consumption and reinforcing unsustainable behavioral patterns. Given their instrumental role in shaping user decisions, there exists an imperative need for sustainable recommender systems that incorporate sustainability principles to foster eco-conscious and socially responsible choices. This comprehensive survey addresses this critical research gap by presenting a systematic analysis of sustainable recommender systems. As these systems can simultaneously advance multiple sustainability objectives--including resource conservation, sustainable consumer behavior, and social impact enhancement--examining their implementations across distinct application domains provides a more rigorous analytical framework. Through a methodological analysis of domain-specific implementations encompassing transportation, food, buildings, and auxiliary sectors, we can better elucidate how these systems holistically advance sustainability objectives while addressing sector-specific constraints and opportunities. Moreover, we delineate future research directions for evolving recommender systems beyond sustainability advocacy toward fostering environmental resilience and social consciousness in society.
Competitive Learning for Achieving Content-specific Filters in Video Coding for Machines
Jun 18, 2024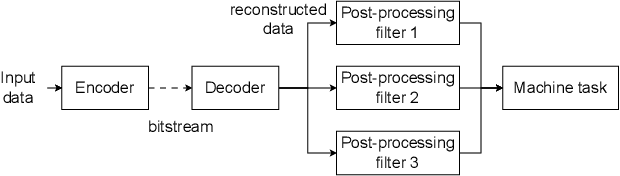


This paper investigates the efficacy of jointly optimizing content-specific post-processing filters to adapt a human oriented video/image codec into a codec suitable for machine vision tasks. By observing that artifacts produced by video/image codecs are content-dependent, we propose a novel training strategy based on competitive learning principles. This strategy assigns training samples to filters dynamically, in a fuzzy manner, which further optimizes the winning filter on the given sample. Inspired by simulated annealing optimization techniques, we employ a softmax function with a temperature variable as the weight allocation function to mitigate the effects of random initialization. Our evaluation, conducted on a system utilizing multiple post-processing filters within a Versatile Video Coding (VVC) codec framework, demonstrates the superiority of content-specific filters trained with our proposed strategies, specifically, when images are processed in blocks. Using VVC reference software VTM 12.0 as the anchor, experiments on the OpenImages dataset show an improvement in the BD-rate reduction from -41.3% and -44.6% to -42.3% and -44.7% for object detection and instance segmentation tasks, respectively, compared to independently trained filters. The statistics of the filter usage align with our hypothesis and underscore the importance of jointly optimizing filters for both content and reconstruction quality. Our findings pave the way for further improving the performance of video/image codecs.
Beyond Similarity: Personalized Federated Recommendation with Composite Aggregation
Jun 06, 2024Federated recommendation aims to collect global knowledge by aggregating local models from massive devices, to provide recommendations while ensuring privacy. Current methods mainly leverage aggregation functions invented by federated vision community to aggregate parameters from similar clients, e.g., clustering aggregation. Despite considerable performance, we argue that it is suboptimal to apply them to federated recommendation directly. This is mainly reflected in the disparate model architectures. Different from structured parameters like convolutional neural networks in federated vision, federated recommender models usually distinguish itself by employing one-to-one item embedding table. Such a discrepancy induces the challenging embedding skew issue, which continually updates the trained embeddings but ignores the non-trained ones during aggregation, thus failing to predict future items accurately. To this end, we propose a personalized Federated recommendation model with Composite Aggregation (FedCA), which not only aggregates similar clients to enhance trained embeddings, but also aggregates complementary clients to update non-trained embeddings. Besides, we formulate the overall learning process into a unified optimization algorithm to jointly learn the similarity and complementarity. Extensive experiments on several real-world datasets substantiate the effectiveness of our proposed model. The source codes are available at https://github.com/hongleizhang/FedCA.