 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the gap between image coding for machines and humans
Jan 19, 2024Image coding for machines (ICM) aims at reducing the bitrate required to represent an image while minimizing the drop in machine vision analysis accuracy. In many use cases, such as surveillance, it is also important that the visual quality is not drastically deteriorated by the compression process. Recent works on using neural network (NN) based ICM codecs have shown significant coding gains against traditional methods; however, the decompressed images, especially at low bitrates, often contain checkerboard artifacts. We propose an effective decoder finetuning scheme based on adversarial training to significantly enhance the visual quality of ICM codecs, while preserving the machine analysis accuracy, without adding extra bitcost or parameters at the inference phase. The results show complete removal of the checkerboard artifacts at the negligible cost of -1.6% relative change in task performance score. In the cases where some amount of artifacts is tolerable, such as when machine consumption is the primary target, this technique can enhance both pixel-fidelity and feature-fidelity scores without losing task performance.
Leveraging progressive model and overfitting for efficient learned image compression
Oct 08, 2022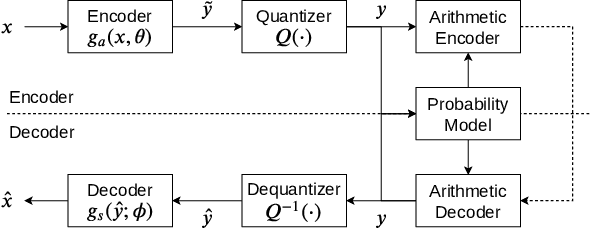
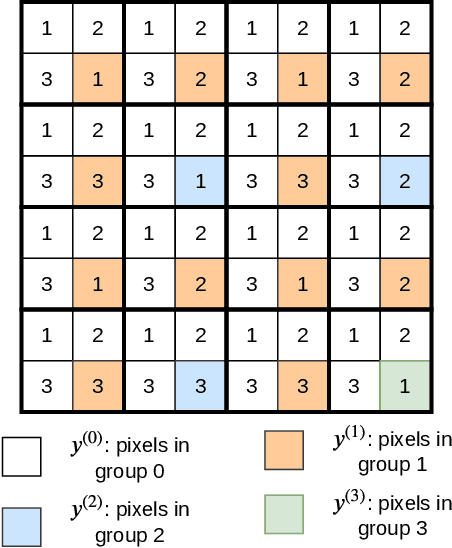
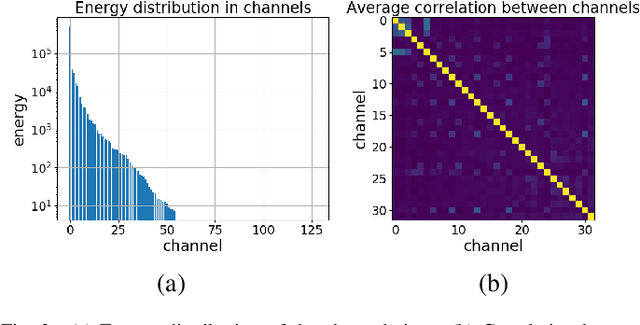
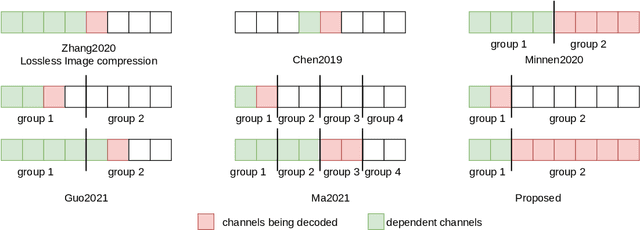
Deep learning is overwhelmingly dominant in the field of computer vision and image/video processing for the last decade. However, for image and video compression, it lags behind the traditional techniques based on discrete cosine transform (DCT) and linear filters. Built on top of an autoencoder architecture, learned image compression (LIC) systems have drawn enormous attention in recent years. Nevertheless, the proposed LIC systems are still inferior to the state-of-the-art traditional techniques, for example, the Versatile Video Coding (VVC/H.266) standard, due to either their compression performance or decoding complexity. Although claimed to outperform the VVC/H.266 on a limited bit rate range, some proposed LIC systems take over 40 seconds to decode a 2K image on a GPU system. In this paper, we introduce a powerful and flexible LIC framework with multi-scale progressive (MSP) probability model and latent representation overfitting (LOF) technique. With different predefined profiles, the proposed framework can achieve various balance points between compression efficiency and computational complexity. Experiments show that the proposed framework achieves 2.5%, 1.0%, and 1.3% Bjontegaard delta bit rate (BD-rate) reduction over the VVC/H.266 standard on three benchmark datasets on a wide bit rate range. More importantly, the decoding complexity is reduced from O(n) to O(1) compared to many other LIC systems, resulting in over 20 times speedup when decoding 2K images.
Adaptation and Attention for Neural Video Coding
Dec 16, 2021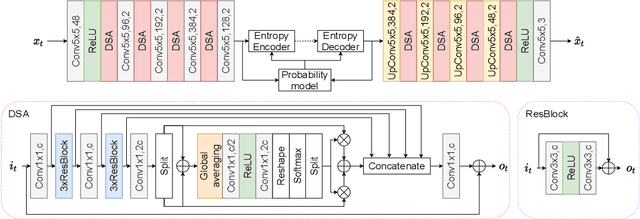
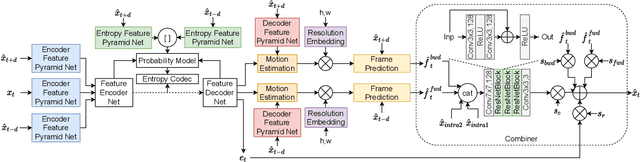
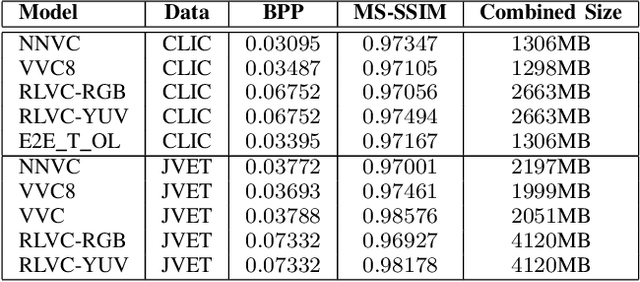
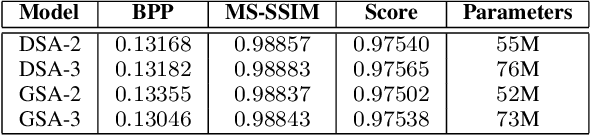
Neural image coding represents now the state-of-the-art image compression approach. However, a lot of work is still to be done in the video domain. In this work, we propose an end-to-end learned video codec that introduces several architectural novelties as well as training novelties, revolving around the concepts of adaptation and attention. Our codec is organized as an intra-frame codec paired with an inter-frame codec. As one architectural novelty, we propose to train the inter-frame codec model to adapt the motion estimation process based on the resolution of the input video. A second architectural novelty is a new neural block that combines concepts from split-attention based neural networks and from DenseNets. Finally, we propose to overfit a set of decoder-side multiplicative parameters at inference time. Through ablation studies and comparisons to prior art, we show the benefits of our proposed techniques in terms of coding gains. We compare our codec to VVC/H.266 and RLVC, which represent the state-of-the-art traditional and end-to-end learned codecs, respectively, and to the top performing end-to-end learned approach in 2021 CLIC competition, E2E_T_OL. Our codec clearly outperforms E2E_T_OL, and compare favorably to VVC and RLVC in some settings.
Lossless Image Compression Using a Multi-Scale Progressive Statistical Model
Aug 24, 2021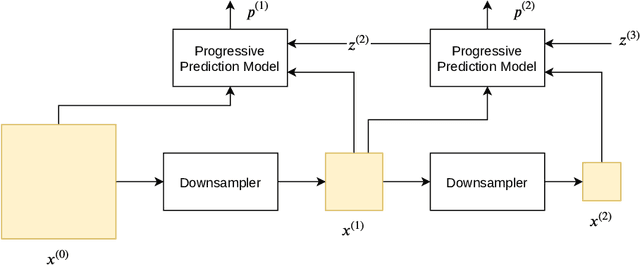

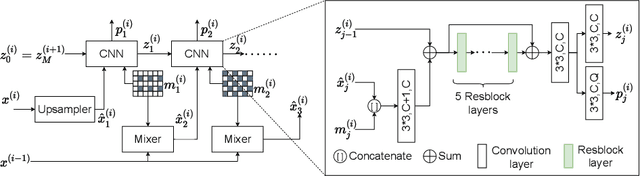

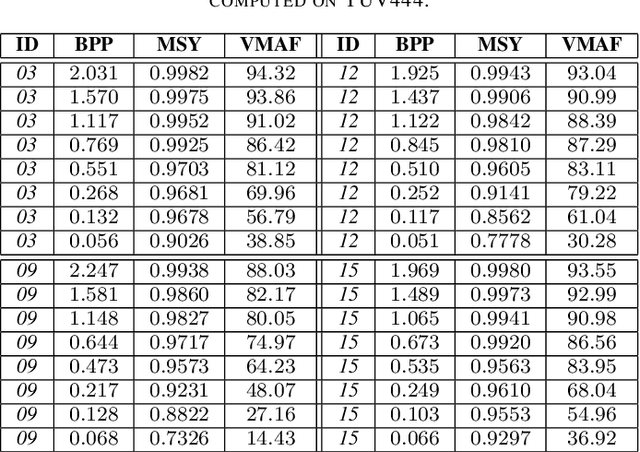
Lossless image compression is an important technique for image storage and transmission when information loss is not allowed. With the fast development of deep learning techniques, deep neural networks have been used in this field to achieve a higher compression rate. Methods based on pixel-wise autoregressive statistical models have shown good performance. However, the sequential processing way prevents these methods to be used in practice. Recently, multi-scale autoregressive models have been proposed to address this limitation. Multi-scale approaches can use parallel computing systems efficiently and build practical systems. Nevertheless, these approaches sacrifice compression performance in exchange for speed. In this paper, we propose a multi-scale progressive statistical model that takes advantage of the pixel-wise approach and the multi-scale approach. We developed a flexible mechanism where the processing order of the pixels can be adjusted easily. Our proposed method outperforms the state-of-the-art lossless image compression methods on two large benchmark datasets by a significant margin without degrading the inference speed dramatically.
L$^2$C -- Learning to Learn to Compress
Jul 31, 2020
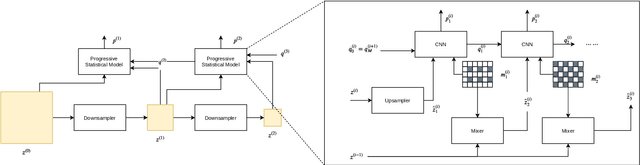

In this paper we present an end-to-end meta-learned system for image compression. Traditional machine learning based approaches to image compression train one or more neural network for generalization performance. However, at inference time, the encoder or the latent tensor output by the encoder can be optimized for each test image. This optimization can be regarded as a form of adaptation or benevolent overfitting to the input content. In order to reduce the gap between training and inference conditions, we propose a new training paradigm for learned image compression, which is based on meta-learning. In a first phase, the neural networks are trained normally. In a second phase, the Model-Agnostic Meta-learning approach is adapted to the specific case of image compression, where the inner-loop performs latent tensor overfitting, and the outer loop updates both encoder and decoder neural networks based on the overfitting performance. Furthermore, after meta-learning, we propose to overfit and cluster the bias terms of the decoder on training image patches, so that at inference time the optimal content-specific bias terms can be selected at encoder-side. Finally, we propose a new probability model for lossless compression, which combines concepts from both multi-scale and super-resolution probability model approaches. We show the benefits of all our proposed ideas via carefully designed experiments.
End-to-End Learning for Video Frame Compression with Self-Attention
Apr 20, 2020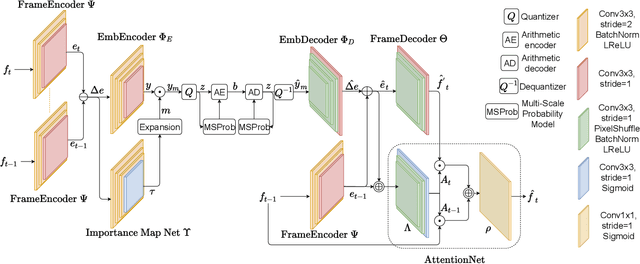
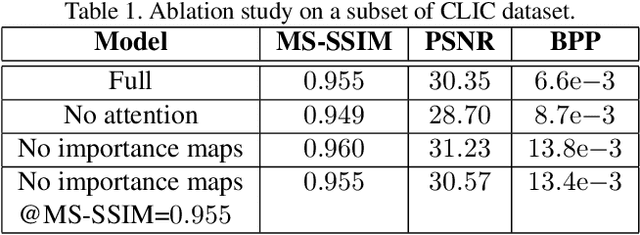

One of the core components of conventional (i.e., non-learned) video codecs consists of predicting a frame from a previously-decoded frame, by leveraging temporal correlations. In this paper, we propose an end-to-end learned system for compressing video frames. Instead of relying on pixel-space motion (as with optical flow), our system learns deep embeddings of frames and encodes their difference in latent space. At decoder-side, an attention mechanism is designed to attend to the latent space of frames to decide how different parts of the previous and current frame are combined to form the final predicted current frame. Spatially-varying channel allocation is achieved by using importance masks acting on the feature-channels. The model is trained to reduce the bitrate by minimizing a loss on importance maps and a loss on the probability output by a context model for arithmetic coding. In our experiments, we show that the proposed system achieves high compression rates and high objective visual quality as measured by MS-SSIM and PSNR. Furthermore, we provide ablation studies where we highlight the contribution of different components.
Calibration of fisheye camera using entrance pupil
Jul 03, 2019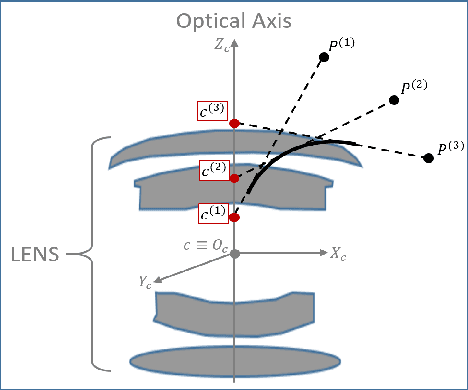
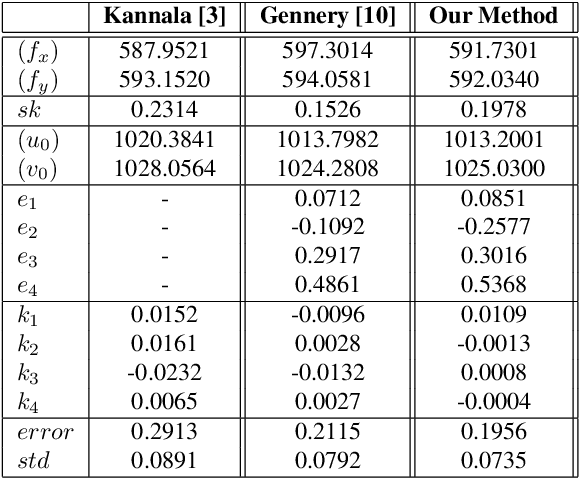
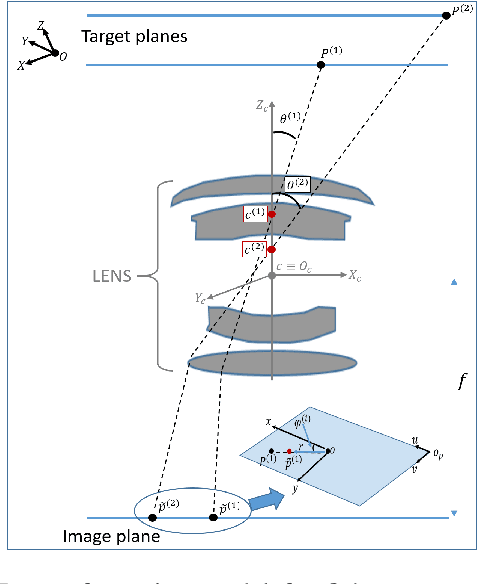

Most conventional camera calibration algorithms assume that the imaging device has a Single Viewpoint (SVP). This is not necessarily true for special imaging device such as fisheye lenses. As a consequence, the intrinsic camera calibration result is not always reliable. In this paper, we propose a new formation model that tends to relax this assumption so that a Non-Single Viewpoint (NSVP) system is corrected to always maintain a SVP, by taking into account the variation of the Entrance Pupil (EP) using thin lens modeling. In addition, we present a calibration procedure for the image formation to estimate these EP parameters using non linear optimization procedure with bundle adjustment. From experiments, we are able to obtain slightly better re-projection error than traditional methods, and the camera parameters are better estimated. The proposed calibration procedure is simple and can easily be integrated to any other thin lens image formation model.
A Compression Objective and a Cycle Loss for Neural Image Compression
May 24, 2019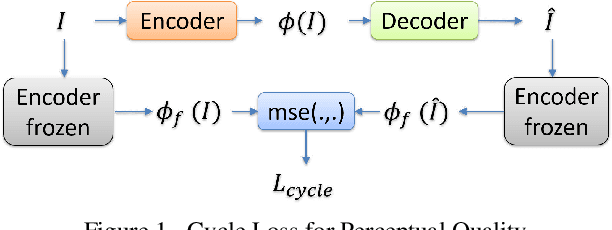
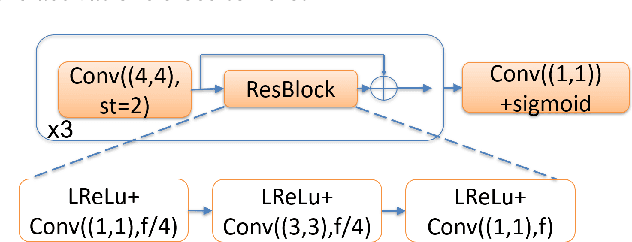
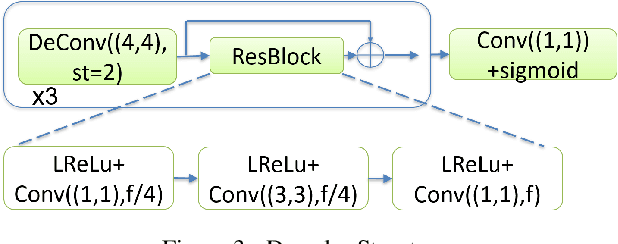

In this manuscript we propose two objective terms for neural image compression: a compression objective and a cycle loss. These terms are applied on the encoder output of an autoencoder and are used in combination with reconstruction losses. The compression objective encourages sparsity and low entropy in the activations. The cycle loss term represents the distortion between encoder outputs computed from the original image and from the reconstructed image (code-domain distortion). We train different autoencoders by using the compression objective in combination with different losses: a) MSE, b) MSE and MSSSIM, c) MSE, MS-SSIM and cycle loss. We observe that images encoded by these differently-trained autoencoders fall into different points of the perception-distortion curve (while having similar bit-rates). In particular, MSE-only training favors low image-domain distortion, whereas cycle loss training favors high perceptual quality.
Compressing Weight-updates for Image Artifacts Removal Neural Networks
May 10, 2019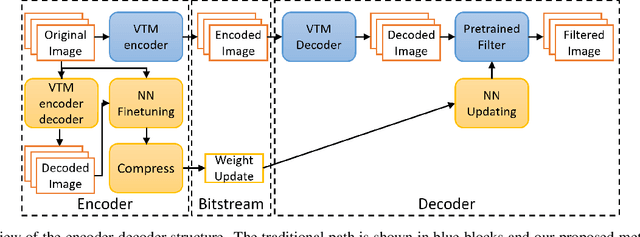
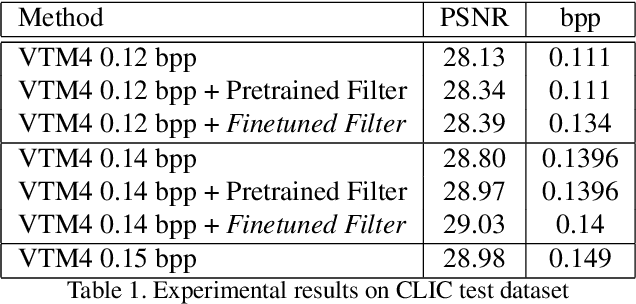

In this paper, we present a novel approach for fine-tuning a decoder-side neural network in the context of image compression, such that the weight-updates are better compressible. At encoder side, we fine-tune a pre-trained artifact removal network on target data by using a compression objective applied on the weight-update. In particular, the compression objective encourages weight-updates which are sparse and closer to quantized values. This way, the final weight-update can be compressed more efficiently by pruning and quantization, and can be included into the encoded bitstream together with the image bitstream of a traditional codec. We show that this approach achieves reconstruction quality which is on-par or slightly superior to a traditional codec, at comparable bitrates. To our knowledge, this is the first attempt to combine image compression and neural network's weight update compression.
Compressibility Loss for Neural Network Weights
May 03, 2019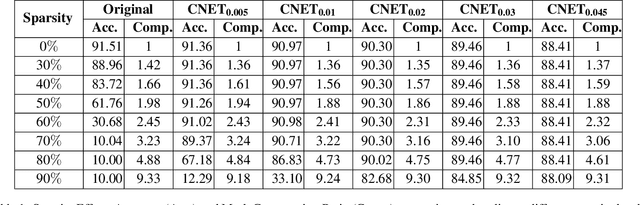

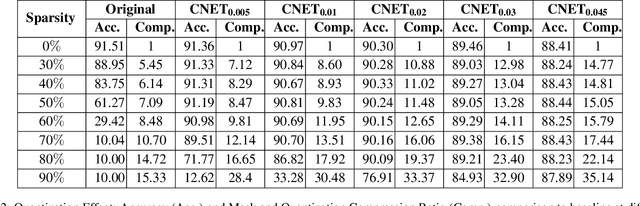

In this paper we apply a compressibility loss that enables learning highly compressible neural network weights. The loss was previously proposed as a measure of negated sparsity of a signal, yet in this paper we show that minimizing this loss also enforces the non-zero parts of the signal to have very low entropy, thus making the entire signal more compressible. For an optimization problem where the goal is to minimize the compressibility loss (the objective), we prove that at any critical point of the objective, the weight vector is a ternary signal and the corresponding value of the objective is the squared root of the number of non-zero elements in the signal, thus directly related to sparsity. In the experiments, we train neural networks with the compressibility loss and we show that the proposed method achieves weight sparsity and compression ratios comparable with the state-of-the-art.