 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompetitive Learning for Achieving Content-specific Filters in Video Coding for Machines
Jun 18, 2024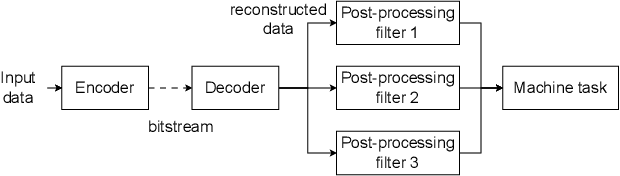

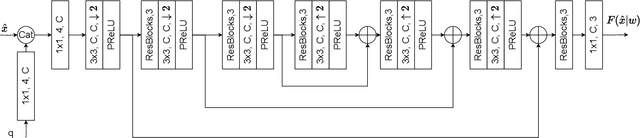

This paper investigates the efficacy of jointly optimizing content-specific post-processing filters to adapt a human oriented video/image codec into a codec suitable for machine vision tasks. By observing that artifacts produced by video/image codecs are content-dependent, we propose a novel training strategy based on competitive learning principles. This strategy assigns training samples to filters dynamically, in a fuzzy manner, which further optimizes the winning filter on the given sample. Inspired by simulated annealing optimization techniques, we employ a softmax function with a temperature variable as the weight allocation function to mitigate the effects of random initialization. Our evaluation, conducted on a system utilizing multiple post-processing filters within a Versatile Video Coding (VVC) codec framework, demonstrates the superiority of content-specific filters trained with our proposed strategies, specifically, when images are processed in blocks. Using VVC reference software VTM 12.0 as the anchor, experiments on the OpenImages dataset show an improvement in the BD-rate reduction from -41.3% and -44.6% to -42.3% and -44.7% for object detection and instance segmentation tasks, respectively, compared to independently trained filters. The statistics of the filter usage align with our hypothesis and underscore the importance of jointly optimizing filters for both content and reconstruction quality. Our findings pave the way for further improving the performance of video/image codecs.
NN-VVC: Versatile Video Coding boosted by self-supervisedly learned image coding for machines
Jan 19, 2024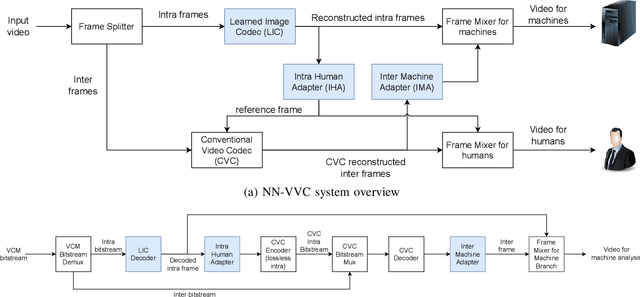

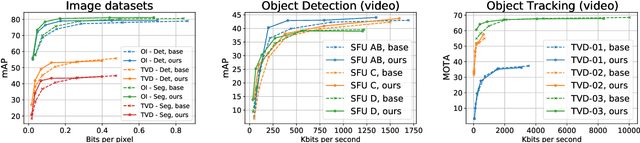
The recent progress in artificial intelligence has led to an ever-increasing usage of images and videos by machine analysis algorithms, mainly neural networks. Nonetheless, compression, storage and transmission of media have traditionally been designed considering human beings as the viewers of the content. Recent research on image and video coding for machine analysis has progressed mainly in two almost orthogonal directions. The first is represented by end-to-end (E2E) learned codecs which, while offering high performance on image coding, are not yet on par with state-of-the-art conventional video codecs and lack interoperability. The second direction considers using the Versatile Video Coding (VVC) standard or any other conventional video codec (CVC) together with pre- and post-processing operations targeting machine analysis. While the CVC-based methods benefit from interoperability and broad hardware and software support, the machine task performance is often lower than the desired level, particularly in low bitrates. This paper proposes a hybrid codec for machines called NN-VVC, which combines the advantages of an E2E-learned image codec and a CVC to achieve high performance in both image and video coding for machines. Our experiments show that the proposed system achieved up to -43.20% and -26.8% Bj{\o}ntegaard Delta rate reduction over VVC for image and video data, respectively, when evaluated on multiple different datasets and machine vision tasks. To the best of our knowledge, this is the first research paper showing a hybrid video codec that outperforms VVC on multiple datasets and multiple machine vision tasks.
Bridging the gap between image coding for machines and humans
Jan 19, 2024Image coding for machines (ICM) aims at reducing the bitrate required to represent an image while minimizing the drop in machine vision analysis accuracy. In many use cases, such as surveillance, it is also important that the visual quality is not drastically deteriorated by the compression process. Recent works on using neural network (NN) based ICM codecs have shown significant coding gains against traditional methods; however, the decompressed images, especially at low bitrates, often contain checkerboard artifacts. We propose an effective decoder finetuning scheme based on adversarial training to significantly enhance the visual quality of ICM codecs, while preserving the machine analysis accuracy, without adding extra bitcost or parameters at the inference phase. The results show complete removal of the checkerboard artifacts at the negligible cost of -1.6% relative change in task performance score. In the cases where some amount of artifacts is tolerable, such as when machine consumption is the primary target, this technique can enhance both pixel-fidelity and feature-fidelity scores without losing task performance.
Leveraging progressive model and overfitting for efficient learned image compression
Oct 08, 2022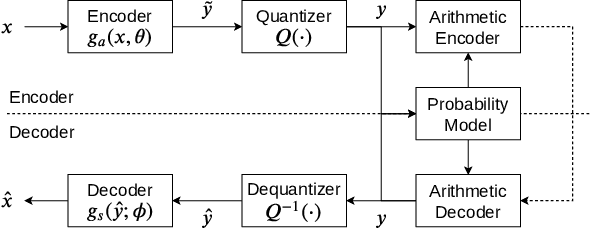
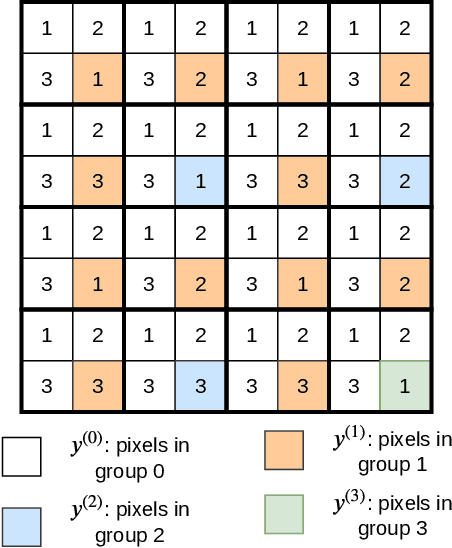
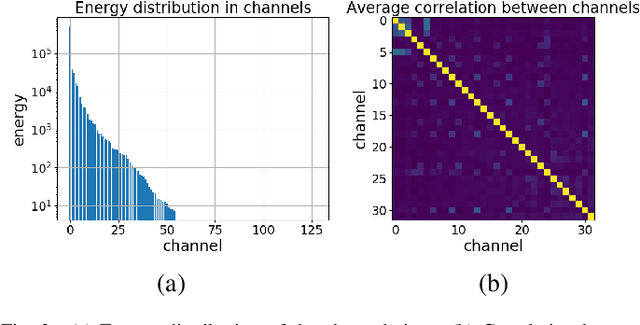
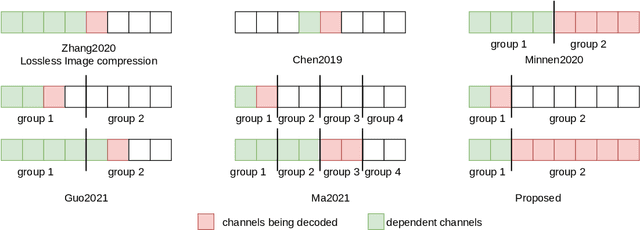
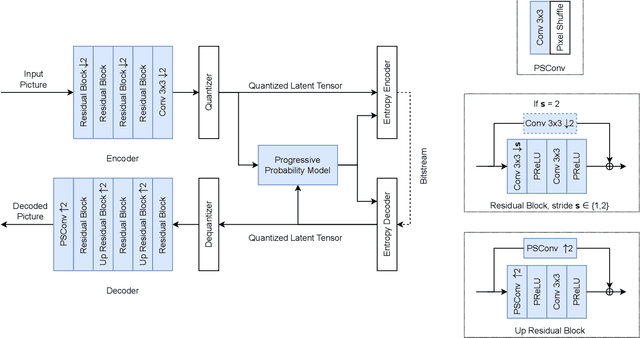
Deep learning is overwhelmingly dominant in the field of computer vision and image/video processing for the last decade. However, for image and video compression, it lags behind the traditional techniques based on discrete cosine transform (DCT) and linear filters. Built on top of an autoencoder architecture, learned image compression (LIC) systems have drawn enormous attention in recent years. Nevertheless, the proposed LIC systems are still inferior to the state-of-the-art traditional techniques, for example, the Versatile Video Coding (VVC/H.266) standard, due to either their compression performance or decoding complexity. Although claimed to outperform the VVC/H.266 on a limited bit rate range, some proposed LIC systems take over 40 seconds to decode a 2K image on a GPU system. In this paper, we introduce a powerful and flexible LIC framework with multi-scale progressive (MSP) probability model and latent representation overfitting (LOF) technique. With different predefined profiles, the proposed framework can achieve various balance points between compression efficiency and computational complexity. Experiments show that the proposed framework achieves 2.5%, 1.0%, and 1.3% Bjontegaard delta bit rate (BD-rate) reduction over the VVC/H.266 standard on three benchmark datasets on a wide bit rate range. More importantly, the decoding complexity is reduced from O(n) to O(1) compared to many other LIC systems, resulting in over 20 times speedup when decoding 2K images.
Adaptation and Attention for Neural Video Coding
Dec 16, 2021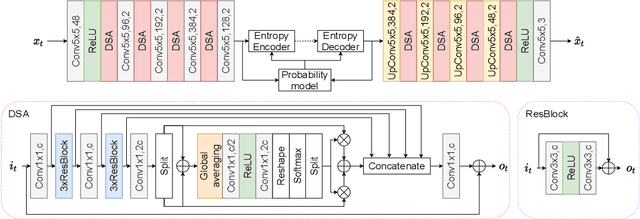
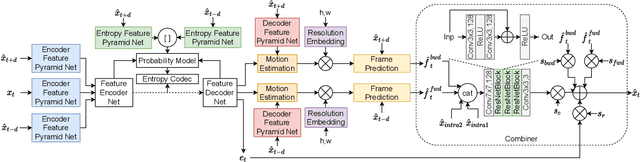
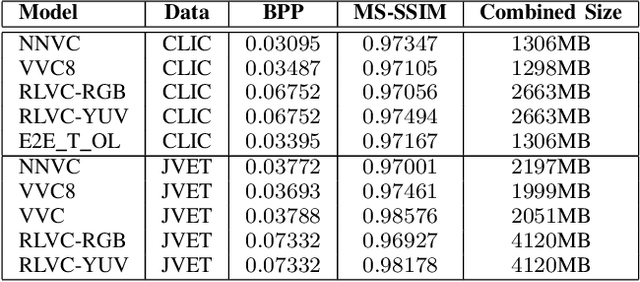
Neural image coding represents now the state-of-the-art image compression approach. However, a lot of work is still to be done in the video domain. In this work, we propose an end-to-end learned video codec that introduces several architectural novelties as well as training novelties, revolving around the concepts of adaptation and attention. Our codec is organized as an intra-frame codec paired with an inter-frame codec. As one architectural novelty, we propose to train the inter-frame codec model to adapt the motion estimation process based on the resolution of the input video. A second architectural novelty is a new neural block that combines concepts from split-attention based neural networks and from DenseNets. Finally, we propose to overfit a set of decoder-side multiplicative parameters at inference time. Through ablation studies and comparisons to prior art, we show the benefits of our proposed techniques in terms of coding gains. We compare our codec to VVC/H.266 and RLVC, which represent the state-of-the-art traditional and end-to-end learned codecs, respectively, and to the top performing end-to-end learned approach in 2021 CLIC competition, E2E_T_OL. Our codec clearly outperforms E2E_T_OL, and compare favorably to VVC and RLVC in some settings.
Image coding for machines: an end-to-end learned approach
Aug 30, 2021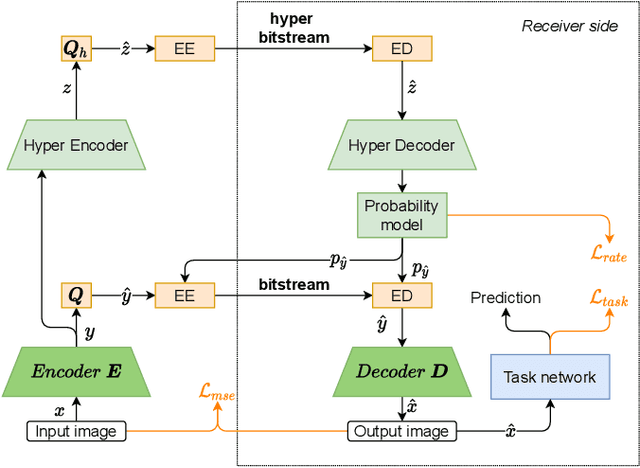

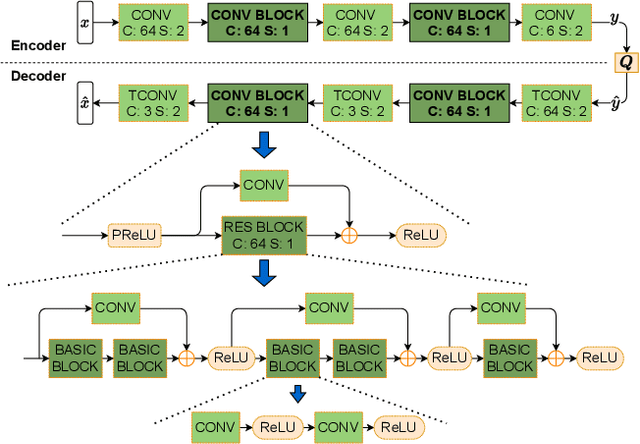
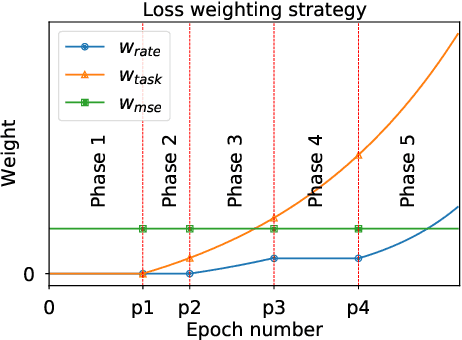
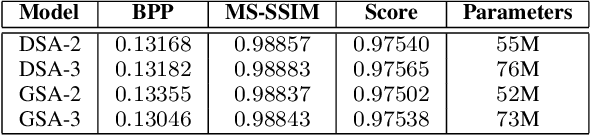
Over recent years, deep learning-based computer vision systems have been applied to images at an ever-increasing pace, oftentimes representing the only type of consumption for those images. Given the dramatic explosion in the number of images generated per day, a question arises: how much better would an image codec targeting machine-consumption perform against state-of-the-art codecs targeting human-consumption? In this paper, we propose an image codec for machines which is neural network (NN) based and end-to-end learned. In particular, we propose a set of training strategies that address the delicate problem of balancing competing loss functions, such as computer vision task losses, image distortion losses, and rate loss. Our experimental results show that our NN-based codec outperforms the state-of-the-art Versa-tile Video Coding (VVC) standard on the object detection and instance segmentation tasks, achieving -37.87% and -32.90% of BD-rate gain, respectively, while being fast thanks to its compact size. To the best of our knowledge, this is the first end-to-end learned machine-targeted image codec.
* Fixed a couple of mistakes since the version accepted in IEEE ICASSP2021
Lossless Image Compression Using a Multi-Scale Progressive Statistical Model
Aug 24, 2021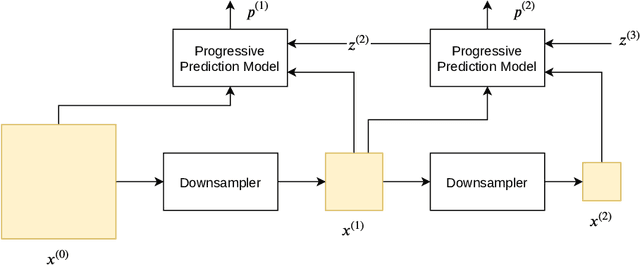

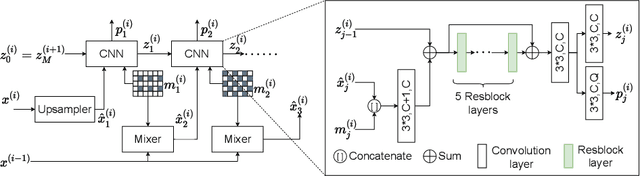

Lossless image compression is an important technique for image storage and transmission when information loss is not allowed. With the fast development of deep learning techniques, deep neural networks have been used in this field to achieve a higher compression rate. Methods based on pixel-wise autoregressive statistical models have shown good performance. However, the sequential processing way prevents these methods to be used in practice. Recently, multi-scale autoregressive models have been proposed to address this limitation. Multi-scale approaches can use parallel computing systems efficiently and build practical systems. Nevertheless, these approaches sacrifice compression performance in exchange for speed. In this paper, we propose a multi-scale progressive statistical model that takes advantage of the pixel-wise approach and the multi-scale approach. We developed a flexible mechanism where the processing order of the pixels can be adjusted easily. Our proposed method outperforms the state-of-the-art lossless image compression methods on two large benchmark datasets by a significant margin without degrading the inference speed dramatically.
Learned Image Coding for Machines: A Content-Adaptive Approach
Aug 23, 2021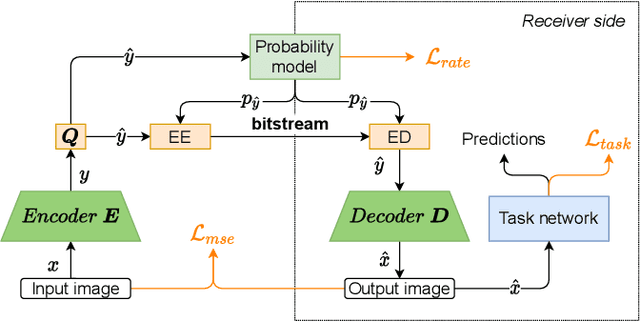
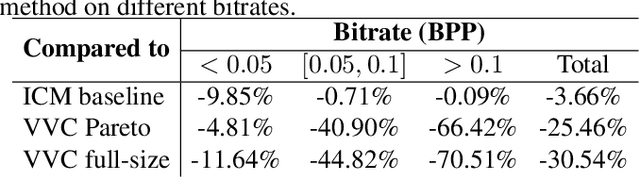
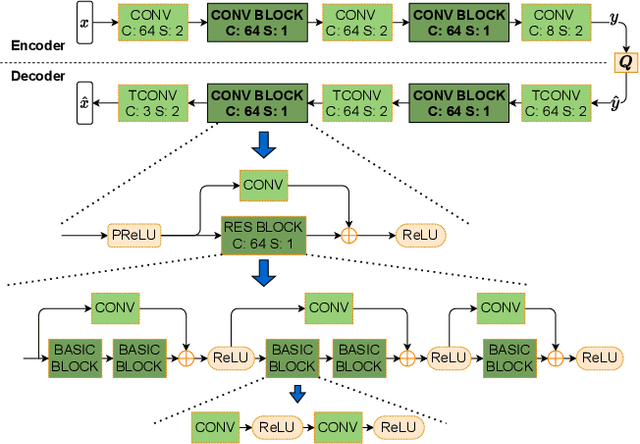
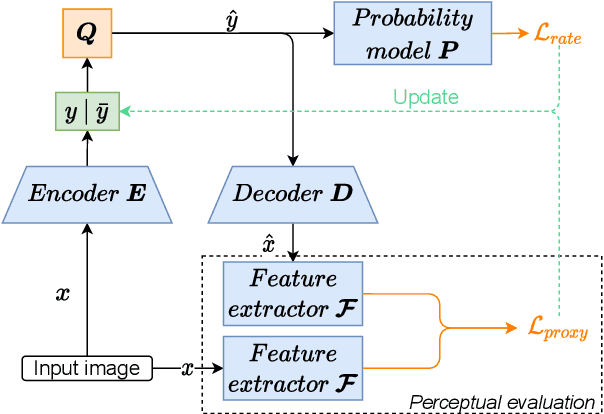
Today, according to the Cisco Annual Internet Report (2018-2023), the fastest-growing category of Internet traffic is machine-to-machine communication. In particular, machine-to-machine communication of images and videos represents a new challenge and opens up new perspectives in the context of data compression. One possible solution approach consists of adapting current human-targeted image and video coding standards to the use case of machine consumption. Another approach consists of developing completely new compression paradigms and architectures for machine-to-machine communications. In this paper, we focus on image compression and present an inference-time content-adaptive finetuning scheme that optimizes the latent representation of an end-to-end learned image codec, aimed at improving the compression efficiency for machine-consumption. The conducted experiments show that our online finetuning brings an average bitrate saving (BD-rate) of -3.66% with respect to our pretrained image codec. In particular, at low bitrate points, our proposed method results in a significant bitrate saving of -9.85%. Overall, our pretrained-and-then-finetuned system achieves -30.54% BD-rate over the state-of-the-art image/video codec Versatile Video Coding (VVC).
* Added some typo fixes since the accepted version in ICME2021
Efficient Adaptation of Neural Network Filter for Video Compression
Aug 13, 2020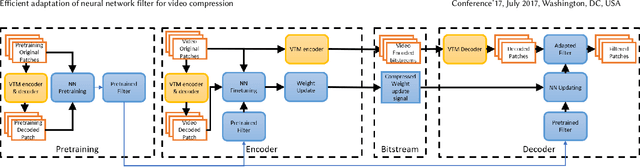
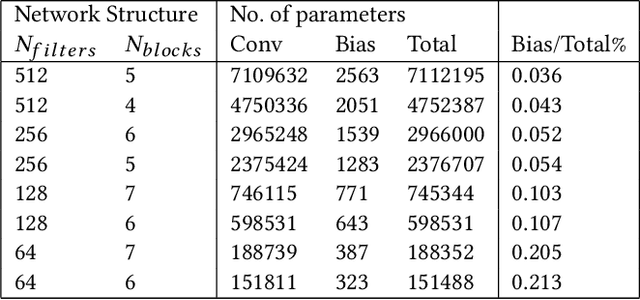
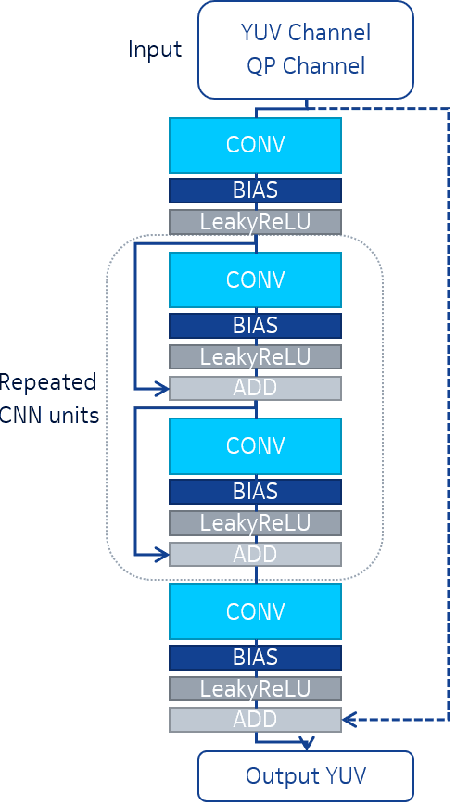
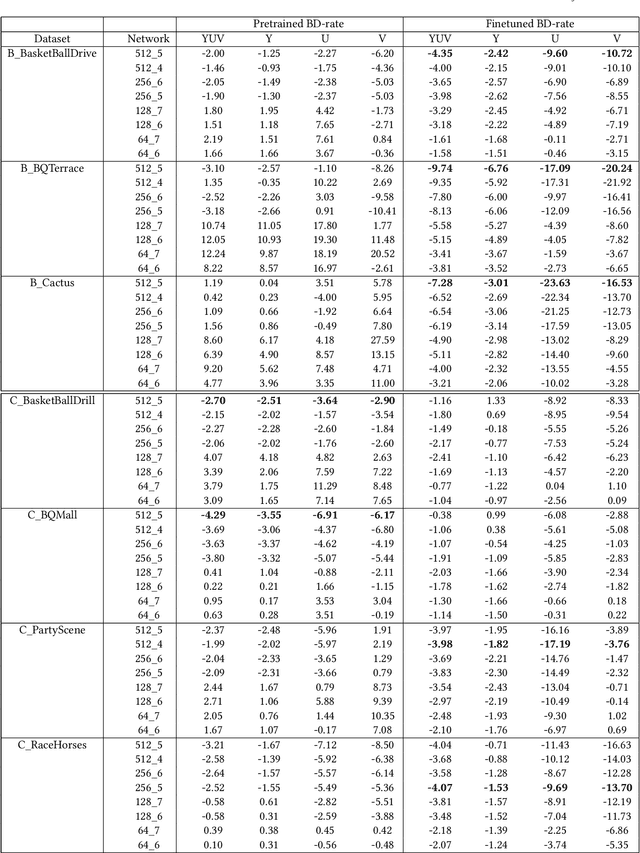
We present an efficient finetuning methodology for neural-network filters which are applied as a postprocessing artifact-removal step in video coding pipelines. The fine-tuning is performed at encoder side to adapt the neural network to the specific content that is being encoded. In order to maximize the PSNR gain and minimize the bitrate overhead, we propose to finetune only the convolutional layers' biases. The proposed method achieves convergence much faster than conventional finetuning approaches, making it suitable for practical applications. The weight-update can be included into the video bitstream generated by the existing video codecs. We show that our method achieves up to 9.7% average BD-rate gain when compared to the state-of-art Versatile Video Coding (VVC) standard codec on 7 test sequences.
L$^2$C -- Learning to Learn to Compress
Jul 31, 2020
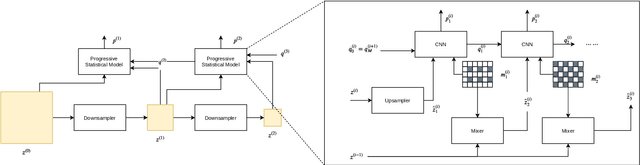
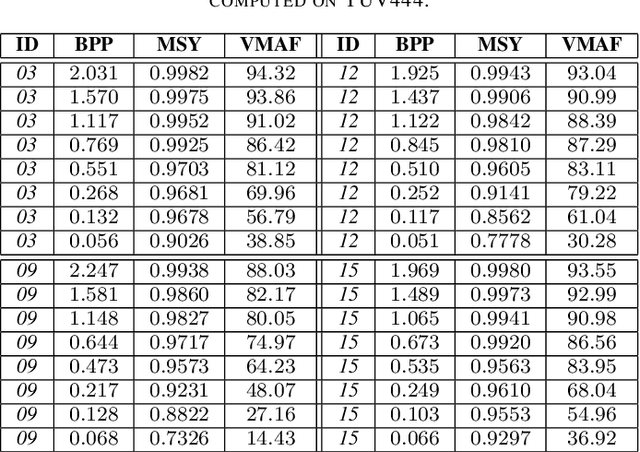

In this paper we present an end-to-end meta-learned system for image compression. Traditional machine learning based approaches to image compression train one or more neural network for generalization performance. However, at inference time, the encoder or the latent tensor output by the encoder can be optimized for each test image. This optimization can be regarded as a form of adaptation or benevolent overfitting to the input content. In order to reduce the gap between training and inference conditions, we propose a new training paradigm for learned image compression, which is based on meta-learning. In a first phase, the neural networks are trained normally. In a second phase, the Model-Agnostic Meta-learning approach is adapted to the specific case of image compression, where the inner-loop performs latent tensor overfitting, and the outer loop updates both encoder and decoder neural networks based on the overfitting performance. Furthermore, after meta-learning, we propose to overfit and cluster the bias terms of the decoder on training image patches, so that at inference time the optimal content-specific bias terms can be selected at encoder-side. Finally, we propose a new probability model for lossless compression, which combines concepts from both multi-scale and super-resolution probability model approaches. We show the benefits of all our proposed ideas via carefully designed experiments.