 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Compression Beyond VVC: Quantitative Analysis of Intra Coding Tools in Enhanced Compression Model (ECM)
Apr 11, 2024A quantitative analysis of post-VVC luma and chroma intra tools is presented, focusing on their statistical behaviors, in terms of block selection rate under different conditions. The aim is to provide insights to the standardization community, offering a clearer understanding of interactions between tools and assisting in the design of an optimal combination of these novel tools when the JVET enters the standardization phase. Specifically, this paper examines the selection rate of intra tools as function of 1) the version of the ECM, 2) video resolution, and 3) video bitrate. Additionally, tests have been conducted on sequences beyond the JVET CTC database. The statistics show several trends and interactions, with various strength, between coding tools of both luma and chroma.
Bridging the gap between image coding for machines and humans
Jan 19, 2024Image coding for machines (ICM) aims at reducing the bitrate required to represent an image while minimizing the drop in machine vision analysis accuracy. In many use cases, such as surveillance, it is also important that the visual quality is not drastically deteriorated by the compression process. Recent works on using neural network (NN) based ICM codecs have shown significant coding gains against traditional methods; however, the decompressed images, especially at low bitrates, often contain checkerboard artifacts. We propose an effective decoder finetuning scheme based on adversarial training to significantly enhance the visual quality of ICM codecs, while preserving the machine analysis accuracy, without adding extra bitcost or parameters at the inference phase. The results show complete removal of the checkerboard artifacts at the negligible cost of -1.6% relative change in task performance score. In the cases where some amount of artifacts is tolerable, such as when machine consumption is the primary target, this technique can enhance both pixel-fidelity and feature-fidelity scores without losing task performance.
Adaptation and Attention for Neural Video Coding
Dec 16, 2021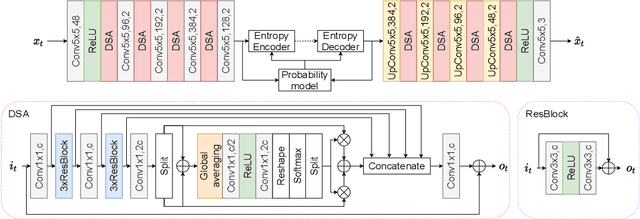
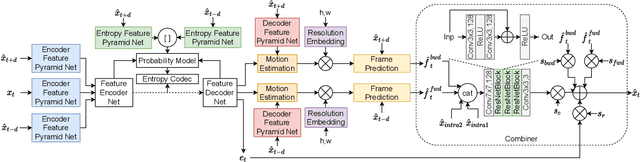
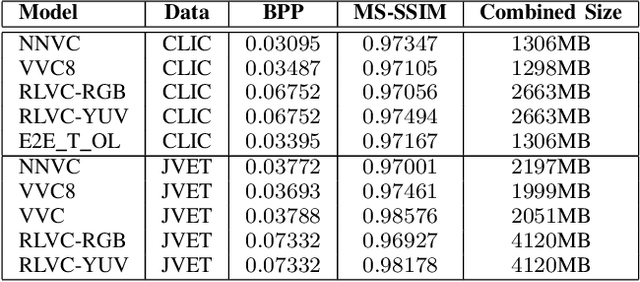
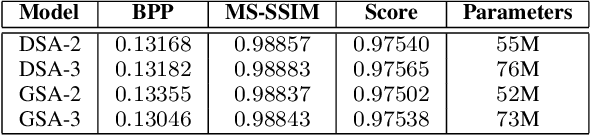
Neural image coding represents now the state-of-the-art image compression approach. However, a lot of work is still to be done in the video domain. In this work, we propose an end-to-end learned video codec that introduces several architectural novelties as well as training novelties, revolving around the concepts of adaptation and attention. Our codec is organized as an intra-frame codec paired with an inter-frame codec. As one architectural novelty, we propose to train the inter-frame codec model to adapt the motion estimation process based on the resolution of the input video. A second architectural novelty is a new neural block that combines concepts from split-attention based neural networks and from DenseNets. Finally, we propose to overfit a set of decoder-side multiplicative parameters at inference time. Through ablation studies and comparisons to prior art, we show the benefits of our proposed techniques in terms of coding gains. We compare our codec to VVC/H.266 and RLVC, which represent the state-of-the-art traditional and end-to-end learned codecs, respectively, and to the top performing end-to-end learned approach in 2021 CLIC competition, E2E_T_OL. Our codec clearly outperforms E2E_T_OL, and compare favorably to VVC and RLVC in some settings.