 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Object Segmentation-Aware Audio Generation
Sep 30, 2025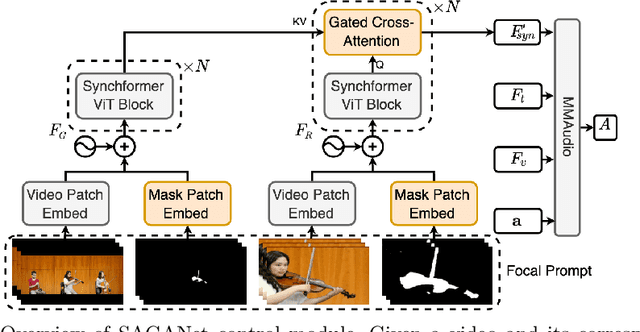



Existing multimodal audio generation models often lack precise user control, which limits their applicability in professional Foley workflows. In particular, these models focus on the entire video and do not provide precise methods for prioritizing a specific object within a scene, generating unnecessary background sounds, or focusing on the wrong objects. To address this gap, we introduce the novel task of video object segmentation-aware audio generation, which explicitly conditions sound synthesis on object-level segmentation maps. We present SAGANet, a new multimodal generative model that enables controllable audio generation by leveraging visual segmentation masks along with video and textual cues. Our model provides users with fine-grained and visually localized control over audio generation. To support this task and further research on segmentation-aware Foley, we propose Segmented Music Solos, a benchmark dataset of musical instrument performance videos with segmentation information. Our method demonstrates substantial improvements over current state-of-the-art methods and sets a new standard for controllable, high-fidelity Foley synthesis. Code, samples, and Segmented Music Solos are available at https://saganet.notion.site
Evaluating Fisheye-Compatible 3D Gaussian Splatting Methods on Real Images Beyond 180 Degree Field of View
Aug 09, 2025We present the first evaluation of fisheye-based 3D Gaussian Splatting methods, Fisheye-GS and 3DGUT, on real images with fields of view exceeding 180 degree. Our study covers both indoor and outdoor scenes captured with 200 degree fisheye cameras and analyzes how each method handles extreme distortion in real world settings. We evaluate performance under varying fields of view (200 degree, 160 degree, and 120 degree) to study the tradeoff between peripheral distortion and spatial coverage. Fisheye-GS benefits from field of view (FoV) reduction, particularly at 160 degree, while 3DGUT remains stable across all settings and maintains high perceptual quality at the full 200 degree view. To address the limitations of SfM-based initialization, which often fails under strong distortion, we also propose a depth-based strategy using UniK3D predictions from only 2-3 fisheye images per scene. Although UniK3D is not trained on real fisheye data, it produces dense point clouds that enable reconstruction quality on par with SfM, even in difficult scenes with fog, glare, or sky. Our results highlight the practical viability of fisheye-based 3DGS methods for wide-angle 3D reconstruction from sparse and distortion-heavy image inputs.
FIORD: A Fisheye Indoor-Outdoor Dataset with LIDAR Ground Truth for 3D Scene Reconstruction and Benchmarking
Apr 02, 2025The development of large-scale 3D scene reconstruction and novel view synthesis methods mostly rely on datasets comprising perspective images with narrow fields of view (FoV). While effective for small-scale scenes, these datasets require large image sets and extensive structure-from-motion (SfM) processing, limiting scalability. To address this, we introduce a fisheye image dataset tailored for scene reconstruction tasks. Using dual 200-degree fisheye lenses, our dataset provides full 360-degree coverage of 5 indoor and 5 outdoor scenes. Each scene has sparse SfM point clouds and precise LIDAR-derived dense point clouds that can be used as geometric ground-truth, enabling robust benchmarking under challenging conditions such as occlusions and reflections. While the baseline experiments focus on vanilla Gaussian Splatting and NeRF based Nerfacto methods, the dataset supports diverse approaches for scene reconstruction, novel view synthesis, and image-based rendering.
AGS-Mesh: Adaptive Gaussian Splatting and Meshing with Geometric Priors for Indoor Room Reconstruction Using Smartphones
Nov 28, 2024Geometric priors are often used to enhance 3D reconstruction. With many smartphones featuring low-resolution depth sensors and the prevalence of off-the-shelf monocular geometry estimators, incorporating geometric priors as regularization signals has become common in 3D vision tasks. However, the accuracy of depth estimates from mobile devices is typically poor for highly detailed geometry, and monocular estimators often suffer from poor multi-view consistency and precision. In this work, we propose an approach for joint surface depth and normal refinement of Gaussian Splatting methods for accurate 3D reconstruction of indoor scenes. We develop supervision strategies that adaptively filters low-quality depth and normal estimates by comparing the consistency of the priors during optimization. We mitigate regularization in regions where prior estimates have high uncertainty or ambiguities. Our filtering strategy and optimization design demonstrate significant improvements in both mesh estimation and novel-view synthesis for both 3D and 2D Gaussian Splatting-based methods on challenging indoor room datasets. Furthermore, we explore the use of alternative meshing strategies for finer geometry extraction. We develop a scale-aware meshing strategy inspired by TSDF and octree-based isosurface extraction, which recovers finer details from Gaussian models compared to other commonly used open-source meshing tools. Our code is released in https://xuqianren.github.io/ags_mesh_website/.
Temporally Aligned Audio for Video with Autoregression
Sep 20, 2024We introduce V-AURA, the first autoregressive model to achieve high temporal alignment and relevance in video-to-audio generation. V-AURA uses a high-framerate visual feature extractor and a cross-modal audio-visual feature fusion strategy to capture fine-grained visual motion events and ensure precise temporal alignment. Additionally, we propose VisualSound, a benchmark dataset with high audio-visual relevance. VisualSound is based on VGGSound, a video dataset consisting of in-the-wild samples extracted from YouTube. During the curation, we remove samples where auditory events are not aligned with the visual ones. V-AURA outperforms current state-of-the-art models in temporal alignment and semantic relevance while maintaining comparable audio quality. Code, samples, VisualSound and models are available at https://v-aura.notion.site
UDGS-SLAM : UniDepth Assisted Gaussian Splatting for Monocular SLAM
Aug 31, 2024Recent advancements in monocular neural depth estimation, particularly those achieved by the UniDepth network, have prompted the investigation of integrating UniDepth within a Gaussian splatting framework for monocular SLAM.This study presents UDGS-SLAM, a novel approach that eliminates the necessity of RGB-D sensors for depth estimation within Gaussian splatting framework. UDGS-SLAM employs statistical filtering to ensure local consistency of the estimated depth and jointly optimizes camera trajectory and Gaussian scene representation parameters. The proposed method achieves high-fidelity rendered images and low ATERMSE of the camera trajectory. The performance of UDGS-SLAM is rigorously evaluated using the TUM RGB-D dataset and benchmarked against several baseline methods, demonstrating superior performance across various scenarios. Additionally, an ablation study is conducted to validate design choices and investigate the impact of different network backbone encoders on system performance.
DN-Splatter: Depth and Normal Priors for Gaussian Splatting and Meshing
Mar 26, 2024



3D Gaussian splatting, a novel differentiable rendering technique, has achieved state-of-the-art novel view synthesis results with high rendering speeds and relatively low training times. However, its performance on scenes commonly seen in indoor datasets is poor due to the lack of geometric constraints during optimization. We extend 3D Gaussian splatting with depth and normal cues to tackle challenging indoor datasets and showcase techniques for efficient mesh extraction, an important downstream application. Specifically, we regularize the optimization procedure with depth information, enforce local smoothness of nearby Gaussians, and use the geometry of the 3D Gaussians supervised by normal cues to achieve better alignment with the true scene geometry. We improve depth estimation and novel view synthesis results over baselines and show how this simple yet effective regularization technique can be used to directly extract meshes from the Gaussian representation yielding more physically accurate reconstructions on indoor scenes. Our code will be released in https://github.com/maturk/dn-splatter.
Gaussian Splatting on the Move: Blur and Rolling Shutter Compensation for Natural Camera Motion
Mar 20, 2024



High-quality scene reconstruction and novel view synthesis based on Gaussian Splatting (3DGS) typically require steady, high-quality photographs, often impractical to capture with handheld cameras. We present a method that adapts to camera motion and allows high-quality scene reconstruction with handheld video data suffering from motion blur and rolling shutter distortion. Our approach is based on detailed modelling of the physical image formation process and utilizes velocities estimated using visual-inertial odometry (VIO). Camera poses are considered non-static during the exposure time of a single image frame and camera poses are further optimized in the reconstruction process. We formulate a differentiable rendering pipeline that leverages screen space approximation to efficiently incorporate rolling-shutter and motion blur effects into the 3DGS framework. Our results with both synthetic and real data demonstrate superior performance in mitigating camera motion over existing methods, thereby advancing 3DGS in naturalistic settings.
GS-Pose: Cascaded Framework for Generalizable Segmentation-based 6D Object Pose Estimation
Mar 15, 2024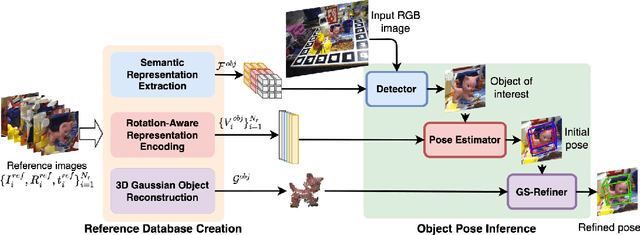
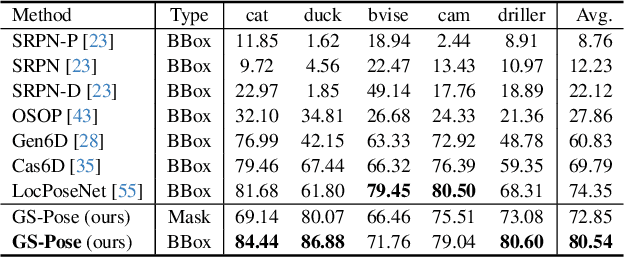
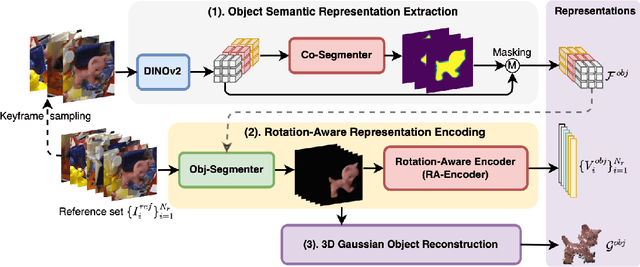
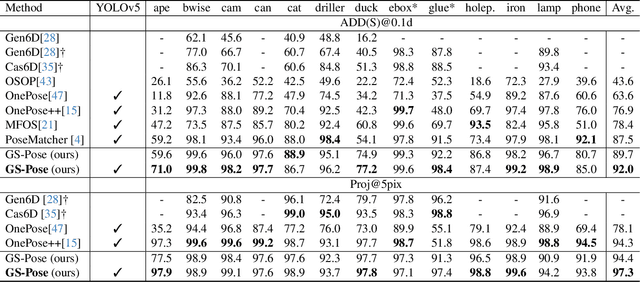
This paper introduces GS-Pose, an end-to-end framework for locating and estimating the 6D pose of objects. GS-Pose begins with a set of posed RGB images of a previously unseen object and builds three distinct representations stored in a database. At inference, GS-Pose operates sequentially by locating the object in the input image, estimating its initial 6D pose using a retrieval approach, and refining the pose with a render-and-compare method. The key insight is the application of the appropriate object representation at each stage of the process. In particular, for the refinement step, we utilize 3D Gaussian splatting, a novel differentiable rendering technique that offers high rendering speed and relatively low optimization time. Off-the-shelf toolchains and commodity hardware, such as mobile phones, can be used to capture new objects to be added to the database. Extensive evaluations on the LINEMOD and OnePose-LowTexture datasets demonstrate excellent performance, establishing the new state-of-the-art. Project page: https://dingdingcai.github.io/gs-pose.
Synchformer: Efficient Synchronization from Sparse Cues
Jan 29, 2024



Our objective is audio-visual synchronization with a focus on 'in-the-wild' videos, such as those on YouTube, where synchronization cues can be sparse. Our contributions include a novel audio-visual synchronization model, and training that decouples feature extraction from synchronization modelling through multi-modal segment-level contrastive pre-training. This approach achieves state-of-the-art performance in both dense and sparse settings. We also extend synchronization model training to AudioSet a million-scale 'in-the-wild' dataset, investigate evidence attribution techniques for interpretability, and explore a new capability for synchronization models: audio-visual synchronizability.