 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompetitive Learning for Achieving Content-specific Filters in Video Coding for Machines
Jun 18, 2024This paper investigates the efficacy of jointly optimizing content-specific post-processing filters to adapt a human oriented video/image codec into a codec suitable for machine vision tasks. By observing that artifacts produced by video/image codecs are content-dependent, we propose a novel training strategy based on competitive learning principles. This strategy assigns training samples to filters dynamically, in a fuzzy manner, which further optimizes the winning filter on the given sample. Inspired by simulated annealing optimization techniques, we employ a softmax function with a temperature variable as the weight allocation function to mitigate the effects of random initialization. Our evaluation, conducted on a system utilizing multiple post-processing filters within a Versatile Video Coding (VVC) codec framework, demonstrates the superiority of content-specific filters trained with our proposed strategies, specifically, when images are processed in blocks. Using VVC reference software VTM 12.0 as the anchor, experiments on the OpenImages dataset show an improvement in the BD-rate reduction from -41.3% and -44.6% to -42.3% and -44.7% for object detection and instance segmentation tasks, respectively, compared to independently trained filters. The statistics of the filter usage align with our hypothesis and underscore the importance of jointly optimizing filters for both content and reconstruction quality. Our findings pave the way for further improving the performance of video/image codecs.
NN-VVC: Versatile Video Coding boosted by self-supervisedly learned image coding for machines
Jan 19, 2024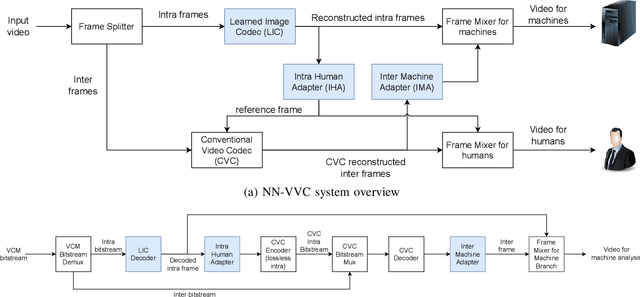
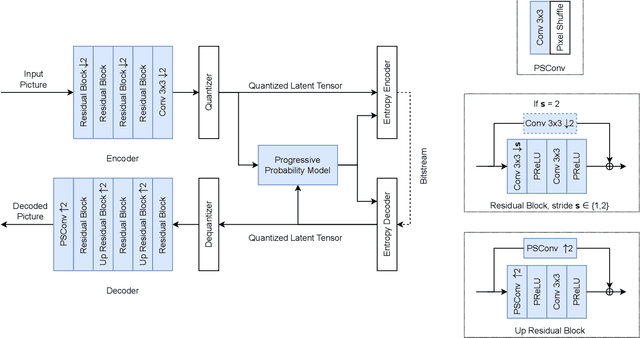

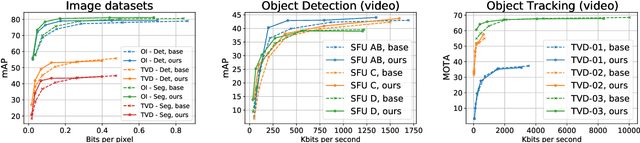
The recent progress in artificial intelligence has led to an ever-increasing usage of images and videos by machine analysis algorithms, mainly neural networks. Nonetheless, compression, storage and transmission of media have traditionally been designed considering human beings as the viewers of the content. Recent research on image and video coding for machine analysis has progressed mainly in two almost orthogonal directions. The first is represented by end-to-end (E2E) learned codecs which, while offering high performance on image coding, are not yet on par with state-of-the-art conventional video codecs and lack interoperability. The second direction considers using the Versatile Video Coding (VVC) standard or any other conventional video codec (CVC) together with pre- and post-processing operations targeting machine analysis. While the CVC-based methods benefit from interoperability and broad hardware and software support, the machine task performance is often lower than the desired level, particularly in low bitrates. This paper proposes a hybrid codec for machines called NN-VVC, which combines the advantages of an E2E-learned image codec and a CVC to achieve high performance in both image and video coding for machines. Our experiments show that the proposed system achieved up to -43.20% and -26.8% Bj{\o}ntegaard Delta rate reduction over VVC for image and video data, respectively, when evaluated on multiple different datasets and machine vision tasks. To the best of our knowledge, this is the first research paper showing a hybrid video codec that outperforms VVC on multiple datasets and multiple machine vision tasks.