 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamera-Agnostic Pruning of 3D Gaussian Splats via Descriptor-Based Beta Evidence
Mar 23, 2026The pruning of 3D Gaussian splats is essential for reducing their complexity to enable efficient storage, transmission, and downstream processing. However, most of the existing pruning strategies depend on camera parameters, rendered images, or view-dependent measures. This dependency becomes a hindrance in emerging camera-agnostic exchange settings, where splats are shared directly as point-based representations (e.g., .ply). In this paper, we propose a camera-agnostic, one-shot, post-training pruning method for 3D Gaussian splats that relies solely on attribute-derived neighbourhood descriptors. As our primary contribution, we introduce a hybrid descriptor framework that captures structural and appearance consistency directly from the splat representation. Building on these descriptors, we formulate pruning as a statistical evidence estimation problem and introduce a Beta evidence model that quantifies per-splat reliability through a probabilistic confidence score. Experiments conducted on standardized test sequences defined by the ISO/IEC MPEG Common Test Conditions (CTC) demonstrate that our approach achieves substantial pruning while preserving reconstruction quality, establishing a practical and generalizable alternative to existing camera-dependent pruning strategies.
EyeFormer: Predicting Personalized Scanpaths with Transformer-Guided Reinforcement Learning
Apr 15, 2024
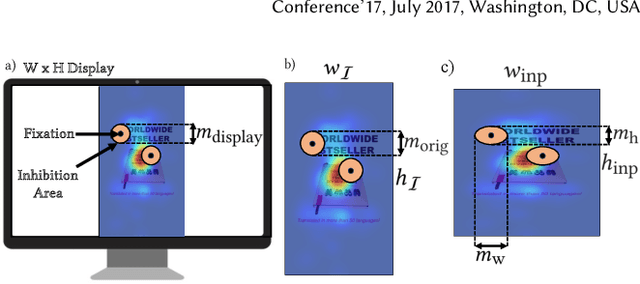
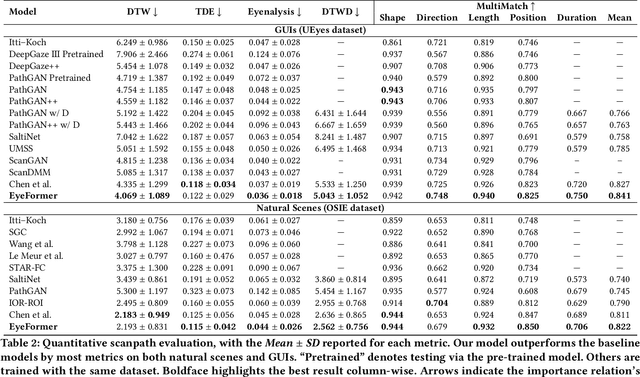
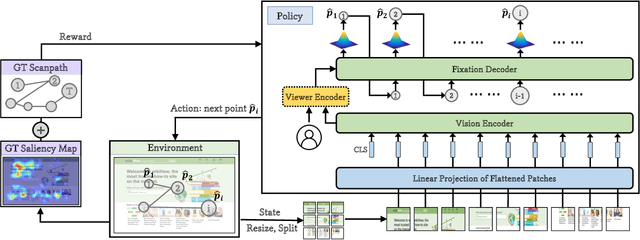
From a visual perception perspective, modern graphical user interfaces (GUIs) comprise a complex graphics-rich two-dimensional visuospatial arrangement of text, images, and interactive objects such as buttons and menus. While existing models can accurately predict regions and objects that are likely to attract attention ``on average'', so far there is no scanpath model capable of predicting scanpaths for an individual. To close this gap, we introduce EyeFormer, which leverages a Transformer architecture as a policy network to guide a deep reinforcement learning algorithm that controls gaze locations. Our model has the unique capability of producing personalized predictions when given a few user scanpath samples. It can predict full scanpath information, including fixation positions and duration, across individuals and various stimulus types. Additionally, we demonstrate applications in GUI layout optimization driven by our model. Our software and models will be publicly available.
Bridging the gap between image coding for machines and humans
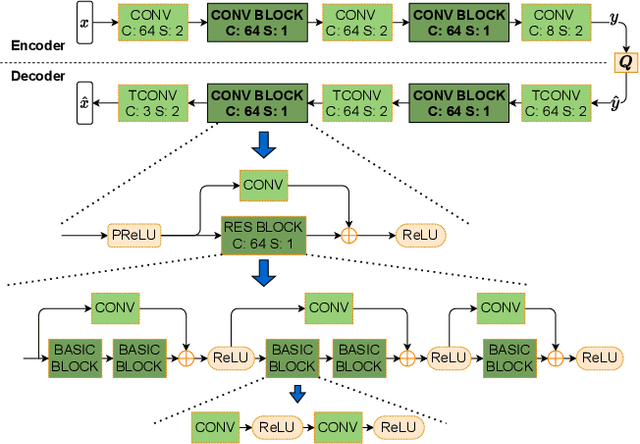
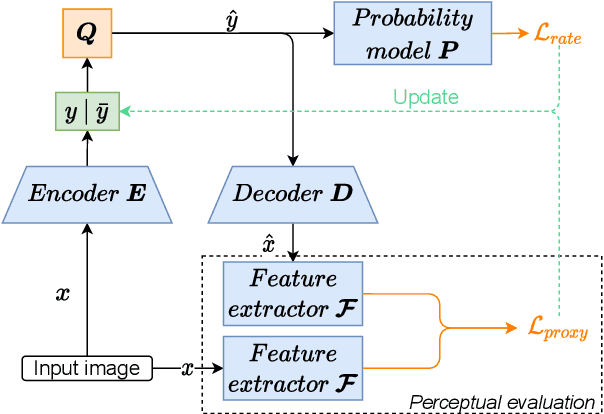
Jan 19, 2024Image coding for machines (ICM) aims at reducing the bitrate required to represent an image while minimizing the drop in machine vision analysis accuracy. In many use cases, such as surveillance, it is also important that the visual quality is not drastically deteriorated by the compression process. Recent works on using neural network (NN) based ICM codecs have shown significant coding gains against traditional methods; however, the decompressed images, especially at low bitrates, often contain checkerboard artifacts. We propose an effective decoder finetuning scheme based on adversarial training to significantly enhance the visual quality of ICM codecs, while preserving the machine analysis accuracy, without adding extra bitcost or parameters at the inference phase. The results show complete removal of the checkerboard artifacts at the negligible cost of -1.6% relative change in task performance score. In the cases where some amount of artifacts is tolerable, such as when machine consumption is the primary target, this technique can enhance both pixel-fidelity and feature-fidelity scores without losing task performance.
NN-VVC: Versatile Video Coding boosted by self-supervisedly learned image coding for machines
Jan 19, 2024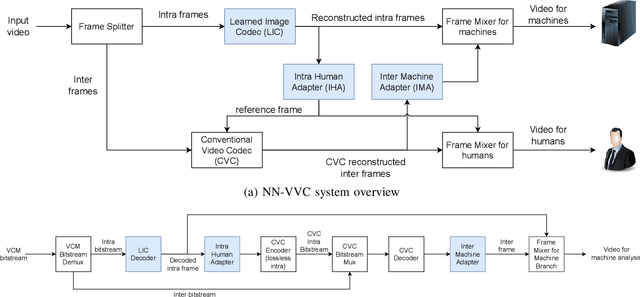

The recent progress in artificial intelligence has led to an ever-increasing usage of images and videos by machine analysis algorithms, mainly neural networks. Nonetheless, compression, storage and transmission of media have traditionally been designed considering human beings as the viewers of the content. Recent research on image and video coding for machine analysis has progressed mainly in two almost orthogonal directions. The first is represented by end-to-end (E2E) learned codecs which, while offering high performance on image coding, are not yet on par with state-of-the-art conventional video codecs and lack interoperability. The second direction considers using the Versatile Video Coding (VVC) standard or any other conventional video codec (CVC) together with pre- and post-processing operations targeting machine analysis. While the CVC-based methods benefit from interoperability and broad hardware and software support, the machine task performance is often lower than the desired level, particularly in low bitrates. This paper proposes a hybrid codec for machines called NN-VVC, which combines the advantages of an E2E-learned image codec and a CVC to achieve high performance in both image and video coding for machines. Our experiments show that the proposed system achieved up to -43.20% and -26.8% Bj{\o}ntegaard Delta rate reduction over VVC for image and video data, respectively, when evaluated on multiple different datasets and machine vision tasks. To the best of our knowledge, this is the first research paper showing a hybrid video codec that outperforms VVC on multiple datasets and multiple machine vision tasks.
Leveraging progressive model and overfitting for efficient learned image compression
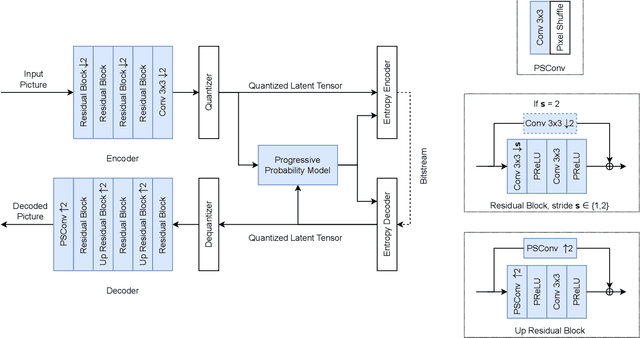
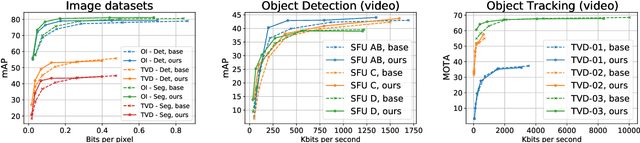
Oct 08, 2022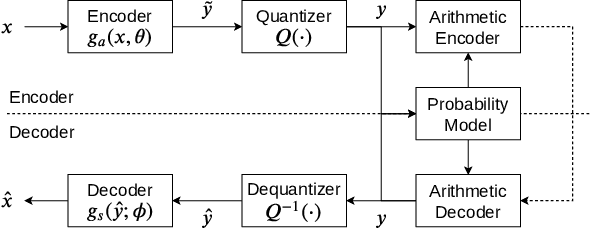
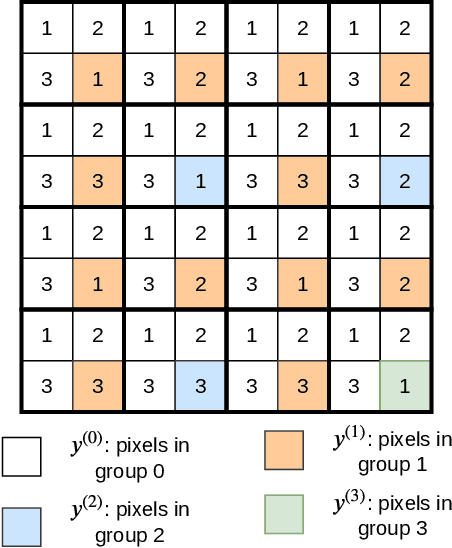
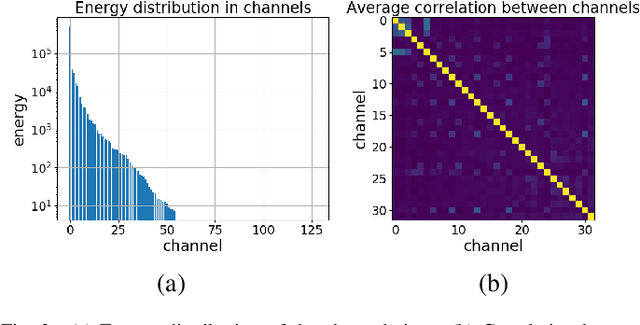
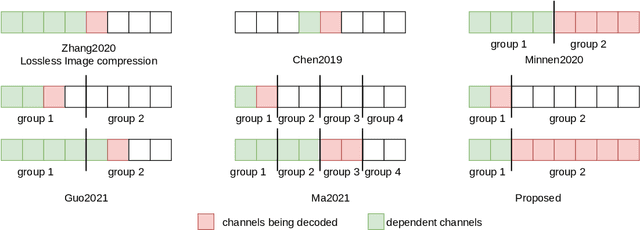
Deep learning is overwhelmingly dominant in the field of computer vision and image/video processing for the last decade. However, for image and video compression, it lags behind the traditional techniques based on discrete cosine transform (DCT) and linear filters. Built on top of an autoencoder architecture, learned image compression (LIC) systems have drawn enormous attention in recent years. Nevertheless, the proposed LIC systems are still inferior to the state-of-the-art traditional techniques, for example, the Versatile Video Coding (VVC/H.266) standard, due to either their compression performance or decoding complexity. Although claimed to outperform the VVC/H.266 on a limited bit rate range, some proposed LIC systems take over 40 seconds to decode a 2K image on a GPU system. In this paper, we introduce a powerful and flexible LIC framework with multi-scale progressive (MSP) probability model and latent representation overfitting (LOF) technique. With different predefined profiles, the proposed framework can achieve various balance points between compression efficiency and computational complexity. Experiments show that the proposed framework achieves 2.5%, 1.0%, and 1.3% Bjontegaard delta bit rate (BD-rate) reduction over the VVC/H.266 standard on three benchmark datasets on a wide bit rate range. More importantly, the decoding complexity is reduced from O(n) to O(1) compared to many other LIC systems, resulting in over 20 times speedup when decoding 2K images.
Learned Image Coding for Machines: A Content-Adaptive Approach
Aug 23, 2021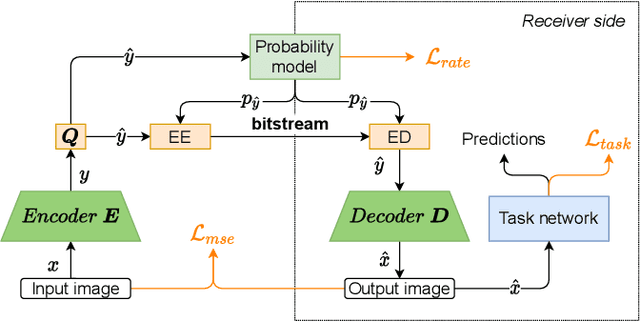
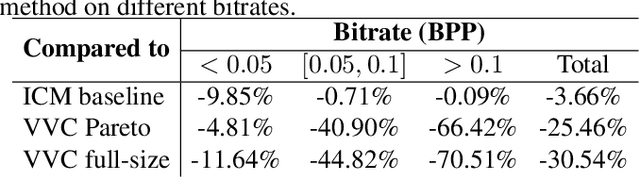
Today, according to the Cisco Annual Internet Report (2018-2023), the fastest-growing category of Internet traffic is machine-to-machine communication. In particular, machine-to-machine communication of images and videos represents a new challenge and opens up new perspectives in the context of data compression. One possible solution approach consists of adapting current human-targeted image and video coding standards to the use case of machine consumption. Another approach consists of developing completely new compression paradigms and architectures for machine-to-machine communications. In this paper, we focus on image compression and present an inference-time content-adaptive finetuning scheme that optimizes the latent representation of an end-to-end learned image codec, aimed at improving the compression efficiency for machine-consumption. The conducted experiments show that our online finetuning brings an average bitrate saving (BD-rate) of -3.66% with respect to our pretrained image codec. In particular, at low bitrate points, our proposed method results in a significant bitrate saving of -9.85%. Overall, our pretrained-and-then-finetuned system achieves -30.54% BD-rate over the state-of-the-art image/video codec Versatile Video Coding (VVC).
* Added some typo fixes since the accepted version in ICME2021
A Compact Deep Architecture for Real-time Saliency Prediction
Aug 30, 2020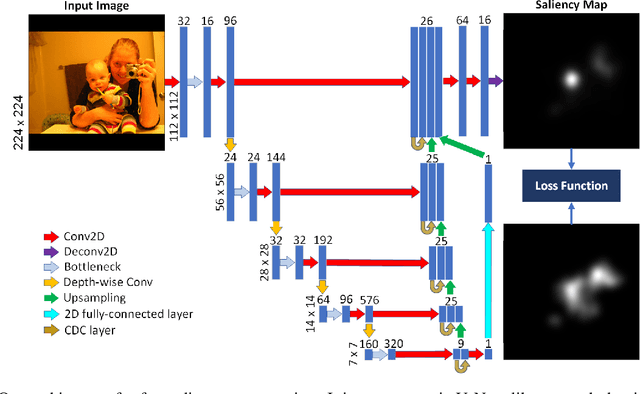

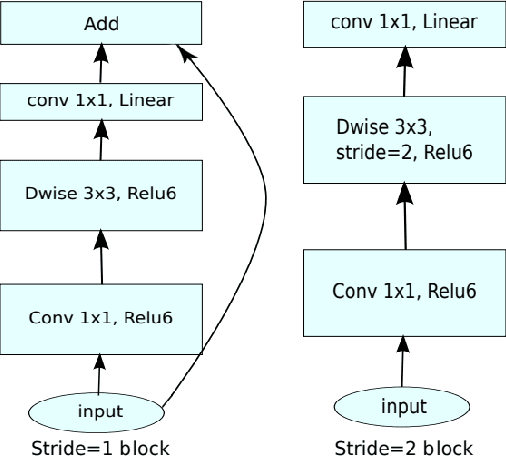
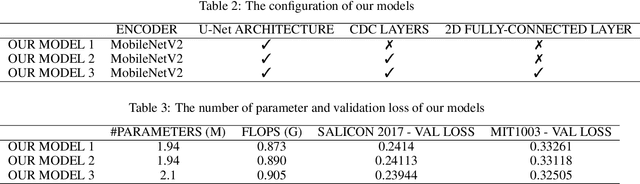
Saliency computation models aim to imitate the attention mechanism in the human visual system. The application of deep neural networks for saliency prediction has led to a drastic improvement over the last few years. However, deep models have a high number of parameters which makes them less suitable for real-time applications. Here we propose a compact yet fast model for real-time saliency prediction. Our proposed model consists of a modified U-net architecture, a novel fully connected layer, and central difference convolutional layers. The modified U-Net architecture promotes compactness and efficiency. The novel fully-connected layer facilitates the implicit capturing of the location-dependent information. Using the central difference convolutional layers at different scales enables capturing more robust and biologically motivated features. We compare our model with state of the art saliency models using traditional saliency scores as well as our newly devised scheme. Experimental results over four challenging saliency benchmark datasets demonstrate the effectiveness of our approach in striking a balance between accuracy and speed. Our model can be run in real-time which makes it appealing for edge devices and video processing.