 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Note on Shumailov et al. (2024): `AI Models Collapse When Trained on Recursively Generated Data'
Oct 16, 2024



The study conducted by Shumailov et al. (2024) demonstrates that repeatedly training a generative model on synthetic data leads to model collapse. This finding has generated considerable interest and debate, particularly given that current models have nearly exhausted the available data. In this work, we investigate the effects of fitting a distribution (through Kernel Density Estimation, or KDE) or a model to the data, followed by repeated sampling from it. Our objective is to develop a theoretical understanding of the phenomenon observed by Shumailov et al. (2024). Our results indicate that the outcomes reported are a statistical phenomenon and may be unavoidable.
Addressing a fundamental limitation in deep vision models: lack of spatial attention
Jul 01, 2024

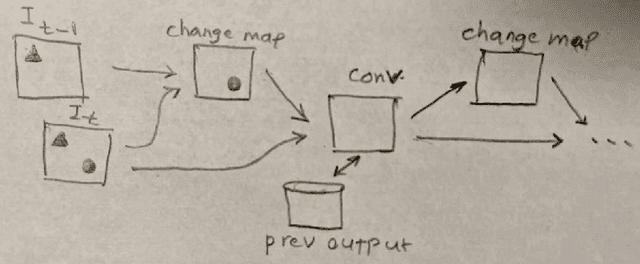
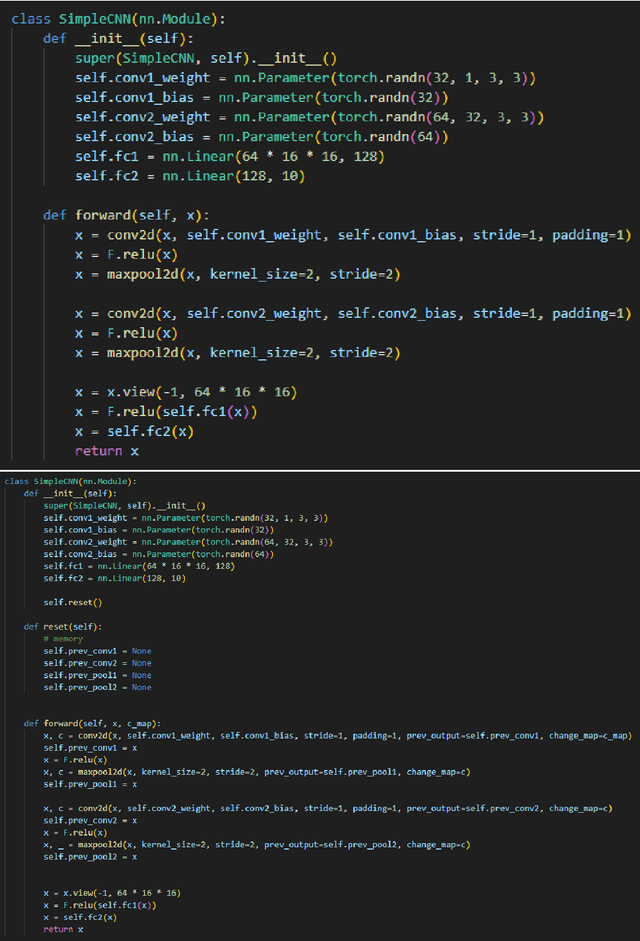
The primary aim of this manuscript is to underscore a significant limitation in current deep learning models, particularly vision models. Unlike human vision, which efficiently selects only the essential visual areas for further processing, leading to high speed and low energy consumption, deep vision models process the entire image. In this work, we examine this issue from a broader perspective and propose a solution that could pave the way for the next generation of more efficient vision models. Basically, convolution and pooling operations are selectively applied to altered regions, with a change map sent to subsequent layers. This map indicates which computations need to be repeated. The code is available at https://github.com/aliborji/spatial_attention.
SalFoM: Dynamic Saliency Prediction with Video Foundation Models
Apr 03, 2024



Recent advancements in video saliency prediction (VSP) have shown promising performance compared to the human visual system, whose emulation is the primary goal of VSP. However, current state-of-the-art models employ spatio-temporal transformers trained on limited amounts of data, hindering generalizability adaptation to downstream tasks. The benefits of vision foundation models present a potential solution to improve the VSP process. However, adapting image foundation models to the video domain presents significant challenges in modeling scene dynamics and capturing temporal information. To address these challenges, and as the first initiative to design a VSP model based on video foundation models, we introduce SalFoM, a novel encoder-decoder video transformer architecture. Our model employs UnMasked Teacher (UMT) as feature extractor and presents a heterogeneous decoder which features a locality-aware spatio-temporal transformer and integrates local and global spatio-temporal information from various perspectives to produce the final saliency map. Our qualitative and quantitative experiments on the challenging VSP benchmark datasets of DHF1K, Hollywood-2 and UCF-Sports demonstrate the superiority of our proposed model in comparison with the state-of-the-art methods.
Key-Value Transformer
May 28, 2023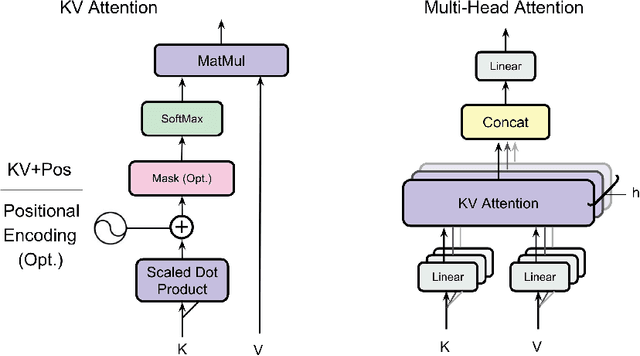
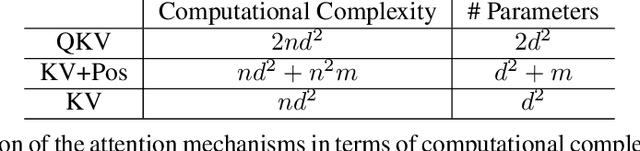
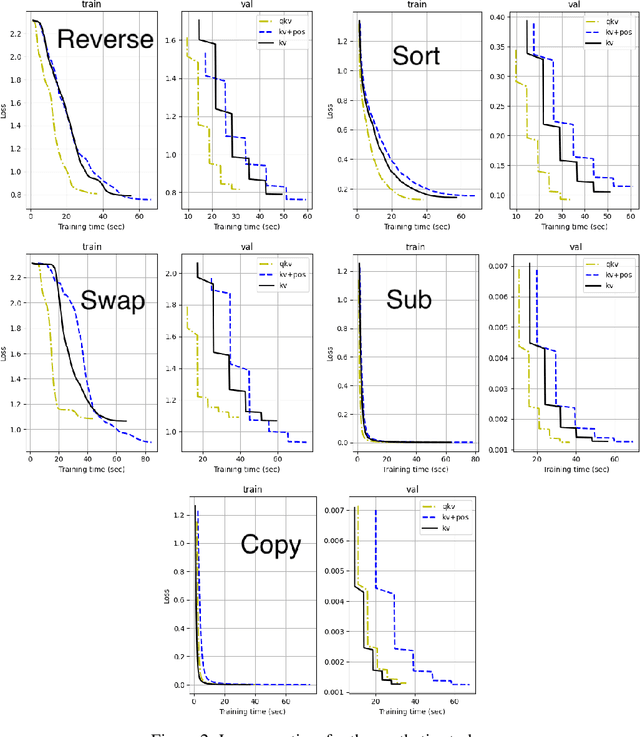

Transformers have emerged as the prevailing standard solution for various AI tasks, including computer vision and natural language processing. The widely adopted Query, Key, and Value formulation (QKV) has played a significant role in this. Nevertheless, no research has examined the essentiality of these three components for transformer performance. Therefore, we conducted an evaluation of the key-value formulation (KV), which generates symmetric attention maps, along with an asymmetric version that incorporates a 2D positional encoding into the attention matrix. Remarkably, this transformer requires fewer parameters and computation than the original one. Through experiments encompassing three task types -- synthetics (such as reversing or sorting a list), vision (mnist or cifar classification), and NLP (character generation and translation) -- we discovered that the KV transformer occasionally outperforms the QKV transformer. However, it also exhibits instances of underperformance compared to QKV, making it challenging to draw a definitive conclusion. Nonetheless, we consider the reported results to be encouraging and anticipate that they may pave the way for more efficient transformers in the future.
Qualitative Failures of Image Generation Models and Their Application in Detecting Deepfakes
Mar 29, 2023



The ability of image and video generation models to create photorealistic images has reached unprecedented heights, making it difficult to distinguish between real and fake images in many cases. However, despite this progress, a gap remains between the quality of generated images and those found in the real world. To address this, we have reviewed a vast body of literature from both academic publications and social media to identify qualitative shortcomings in image generation models, which we have classified into five categories. By understanding these failures, we can identify areas where these models need improvement, as well as develop strategies for detecting deep fakes. The prevalence of deep fakes in today's society is a serious concern, and our findings can help mitigate their negative impact.
A Categorical Archive of ChatGPT Failures
Feb 23, 2023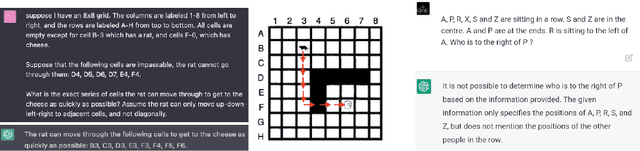
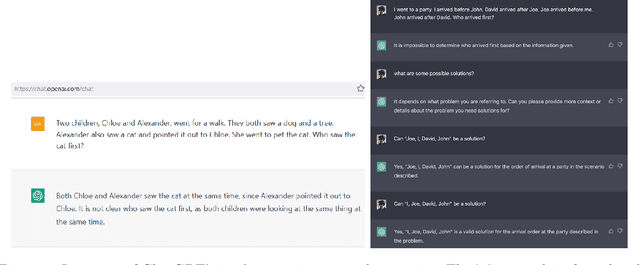
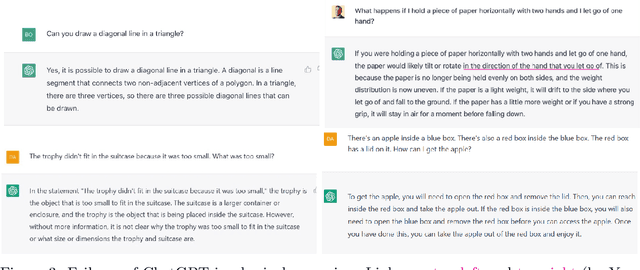
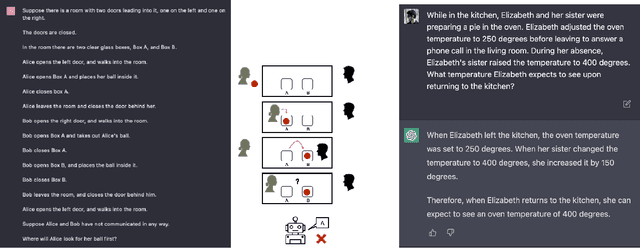
Large language models have been demonstrated to be valuable in different fields. ChatGPT, developed by OpenAI, has been trained using massive amounts of data and simulates human conversation by comprehending context and generating appropriate responses. It has garnered significant attention due to its ability to effectively answer a broad range of human inquiries, with fluent and comprehensive answers surpassing prior public chatbots in both security and usefulness. However, a comprehensive analysis of ChatGPT's failures is lacking, which is the focus of this study. Eleven categories of failures, including reasoning, factual errors, math, coding, and bias, are presented and discussed. The risks, limitations, and societal implications of ChatGPT are also highlighted. The goal of this study is to assist researchers and developers in enhancing future language models and chatbots.
Diverse, Difficult, and Odd Instances : A New Test Set for Object Classification
Jan 29, 2023



Test sets are an integral part of evaluating models and gauging progress in object recognition, and more broadly in computer vision and AI. Existing test sets for object recognition, however, suffer from shortcomings such as bias towards the ImageNet characteristics and idiosyncrasies (e.g., ImageNet-V2), being limited to certain types of stimuli (e.g., indoor scenes in ObjectNet), and underestimating the model performance (e.g., ImageNet-A). To mitigate these problems, we introduce a new test set, called D2O, which is sufficiently different from existing test sets. Images are a mix of generated images as well as images crawled from the web. They are diverse, unmodified, and representative of real-world scenarios and cause state-of-the-art models to misclassify them with high confidence. To emphasize generalization, our dataset by design does not come paired with a training set. It contains 8,060 images spread across 36 categories, out of which 29 appear in ImageNet. The best Top-1 accuracy on our dataset is around 60% which is much lower than 91% best Top-1 accuracy on ImageNet. We find that popular vision APIs perform very poorly in detecting objects over D2O categories such as ``faces'', ``cars'', and ``cats''. Our dataset also comes with a ``miscellaneous'' category, over which we test the image tagging models. Overall, our investigations demonstrate that the D2O test set contain a mix of images with varied levels of difficulty and is predictive of the average-case performance of models. It can challenge object recognition models for years to come and can spur more research in this fundamental area.
BinaryVQA: A Versatile Test Set to Evaluate the Out-of-Distribution Generalization of VQA Models
Jan 28, 2023



We introduce a new test set for visual question answering (VQA) called BinaryVQA to push the limits of VQA models. Our dataset includes 7,800 questions across 1,024 images and covers a wide variety of objects, topics, and concepts. For easy model evaluation, we only consider binary questions. Questions and answers are formulated and verified carefully and manually. Around 63% of the questions have positive answers. The median number of questions per image and question length are 7 and 5, respectively. The state of the art OFA model achieves 75% accuracy on BinaryVQA dataset, which is significantly lower than its performance on the VQA v2 test-dev dataset (94.7%). We also analyze the model behavior along several dimensions including: a) performance over different categories such as text, counting and gaze direction, b) model interpretability, c) the effect of question length on accuracy, d) bias of models towards positive answers and introduction of a new score called the ShuffleAcc, and e) sensitivity to spelling and grammar errors. Our investigation demonstrates the difficulty of our dataset and shows that it can challenge VQA models for next few years. Data and code are publicly available at: DATA and CODE.
Logits are predictive of network type
Nov 04, 2022



We show that it is possible to predict which deep network has generated a given logit vector with accuracy well above chance. We utilize a number of networks on a dataset, initialized with random weights or pretrained weights, as well as fine-tuned networks. A classifier is then trained on the logit vectors of the trained set of this dataset to map the logit vector to the network index that has generated it. The classifier is then evaluated on the test set of the dataset. Results are better with randomly initialized networks, but also generalize to pretrained networks as well as fine-tuned ones. Classification accuracy is higher using unnormalized logits than normalized ones. We find that there is little transfer when applying a classifier to the same networks but with different sets of weights. In addition to help better understand deep networks and the way they encode uncertainty, we anticipate our finding to be useful in some applications (e.g. tailoring an adversarial attack for a certain type of network). Code is available at https://github.com/aliborji/logits.
Generated Faces in the Wild: Quantitative Comparison of Stable Diffusion, Midjourney and DALL-E 2
Oct 02, 2022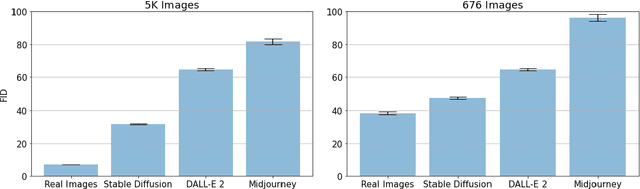



The field of image synthesis has made great strides in the last couple of years. Recent models are capable of generating images with astonishing quality. Fine-grained evaluation of these models on some interesting categories such as faces is still missing. Here, we conduct a quantitative comparison of three popular systems including Stable Diffusion, Midjourney, and DALL-E 2 in their ability to generate photorealistic faces in the wild. We find that Stable Diffusion generates better faces than the other systems, according to the FID score. We also introduce a dataset of generated faces in the wild dubbed GFW, including a total of 15,076 faces. Furthermore, we hope that our study spurs follow-up research in assessing the generative models and improving them. Data and code are available at data and code, respectively.