 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal-Local Feature Decoding with Adapter-Guided SAMv2 for Salient Object Detection
May 04, 2026Salient Object Detection (SOD) remains an essential yet underexplored task in the era of large-scale vision models. Although foundation models like SAM exhibit strong generalization, their potential for SOD is not fully realized, and training or fully fine-tuning them is computationally expensive and prone to overfitting under limited data. To overcome these challenges, we introduce GLASSNet, a Global-Local feature decoding framework that uses SAMv2 as a frozen encoder paired with a lightweight, spatially aware convolutional adapter-reducing learnable encoder parameters by over 97%. To enhance saliency quality, GLASSNet employs a dual-decoder architecture: one decoder captures global, long-range semantics with an expanded receptive field, while the other captures fine local details such as edges and textures. Fusing these complementary cues yields saliency maps that combine global coherence with local precision, producing accurate final masks. Extensive experiments on standard SOD and camouflaged object detection benchmarks show that GLASSNet surpasses state-of-the-art methods, demonstrating the power of frozen foundation models combined with targeted adaptation and global-local decoding.
Brain-Grasp: Graph-based Saliency Priors for Improved fMRI-based Visual Brain Decoding
Apr 12, 2026Recent progress in brain-guided image generation has improved the quality of fMRI-based reconstructions; however, fundamental challenges remain in preserving object-level structure and semantic fidelity. Many existing approaches overlook the spatial arrangement of salient objects, leading to conceptually inconsistent outputs. We propose a saliency-driven decoding framework that employs graph-informed saliency priors to translate structural cues from brain signals into spatial masks. These masks, together with semantic information extracted from embeddings, condition a diffusion model to guide image regeneration, helping preserve object conformity while maintaining natural scene composition. In contrast to pipelines that invoke multiple diffusion stages, our approach relies on a single frozen model, offering a more lightweight yet effective design. Experiments show that this strategy improves both conceptual alignment and structural similarity to the original stimuli, while also introducing a new direction for efficient, interpretable, and structurally grounded brain decoding.
SalFoM: Dynamic Saliency Prediction with Video Foundation Models
Apr 03, 2024



Recent advancements in video saliency prediction (VSP) have shown promising performance compared to the human visual system, whose emulation is the primary goal of VSP. However, current state-of-the-art models employ spatio-temporal transformers trained on limited amounts of data, hindering generalizability adaptation to downstream tasks. The benefits of vision foundation models present a potential solution to improve the VSP process. However, adapting image foundation models to the video domain presents significant challenges in modeling scene dynamics and capturing temporal information. To address these challenges, and as the first initiative to design a VSP model based on video foundation models, we introduce SalFoM, a novel encoder-decoder video transformer architecture. Our model employs UnMasked Teacher (UMT) as feature extractor and presents a heterogeneous decoder which features a locality-aware spatio-temporal transformer and integrates local and global spatio-temporal information from various perspectives to produce the final saliency map. Our qualitative and quantitative experiments on the challenging VSP benchmark datasets of DHF1K, Hollywood-2 and UCF-Sports demonstrate the superiority of our proposed model in comparison with the state-of-the-art methods.
Transformer-based Video Saliency Prediction with High Temporal Dimension Decoding
Jan 15, 2024
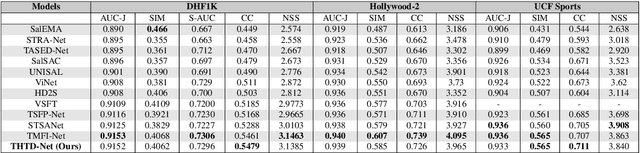


In recent years, finding an effective and efficient strategy for exploiting spatial and temporal information has been a hot research topic in video saliency prediction (VSP). With the emergence of spatio-temporal transformers, the weakness of the prior strategies, e.g., 3D convolutional networks and LSTM-based networks, for capturing long-range dependencies has been effectively compensated. While VSP has drawn benefits from spatio-temporal transformers, finding the most effective way for aggregating temporal features is still challenging. To address this concern, we propose a transformer-based video saliency prediction approach with high temporal dimension decoding network (THTD-Net). This strategy accounts for the lack of complex hierarchical interactions between features that are extracted from the transformer-based spatio-temporal encoder: in particular, it does not require multiple decoders and aims at gradually reducing temporal features' dimensions in the decoder. This decoder-based architecture yields comparable performance to multi-branch and over-complicated models on common benchmarks such as DHF1K, UCF-sports and Hollywood-2.
TinyHD: Efficient Video Saliency Prediction with Heterogeneous Decoders using Hierarchical Maps Distillation
Jan 11, 2023



Video saliency prediction has recently attracted attention of the research community, as it is an upstream task for several practical applications. However, current solutions are particularly computationally demanding, especially due to the wide usage of spatio-temporal 3D convolutions. We observe that, while different model architectures achieve similar performance on benchmarks, visual variations between predicted saliency maps are still significant. Inspired by this intuition, we propose a lightweight model that employs multiple simple heterogeneous decoders and adopts several practical approaches to improve accuracy while keeping computational costs low, such as hierarchical multi-map knowledge distillation, multi-output saliency prediction, unlabeled auxiliary datasets and channel reduction with teacher assistant supervision. Our approach achieves saliency prediction accuracy on par or better than state-of-the-art methods on DFH1K, UCF-Sports and Hollywood2 benchmarks, while enhancing significantly the efficiency of the model. Code is on https://github.com/feiyanhu/tinyHD