 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Decentralized Federated Learning
Sep 30, 2025CLIP has revolutionized zero-shot learning by enabling task generalization without fine-tuning. While prompting techniques like CoOp and CoCoOp enhance CLIP's adaptability, their effectiveness in Federated Learning (FL) remains an open challenge. Existing federated prompt learning approaches, such as FedCoOp and FedTPG, improve performance but face generalization issues, high communication costs, and reliance on a central server, limiting scalability and privacy. We propose Zero-shot Decentralized Federated Learning (ZeroDFL), a fully decentralized framework that enables zero-shot adaptation across distributed clients without a central coordinator. ZeroDFL employs an iterative prompt-sharing mechanism, allowing clients to optimize and exchange textual prompts to enhance generalization while drastically reducing communication overhead. We validate ZeroDFL on nine diverse image classification datasets, demonstrating that it consistently outperforms--or remains on par with--state-of-the-art federated prompt learning methods. More importantly, ZeroDFL achieves this performance in a fully decentralized setting while reducing communication overhead by 118x compared to FedTPG. These results highlight that our approach not only enhances generalization in federated zero-shot learning but also improves scalability, efficiency, and privacy preservation--paving the way for decentralized adaptation of large vision-language models in real-world applications.
Cyst-X: AI-Powered Pancreatic Cancer Risk Prediction from Multicenter MRI in Centralized and Federated Learning
Jul 29, 2025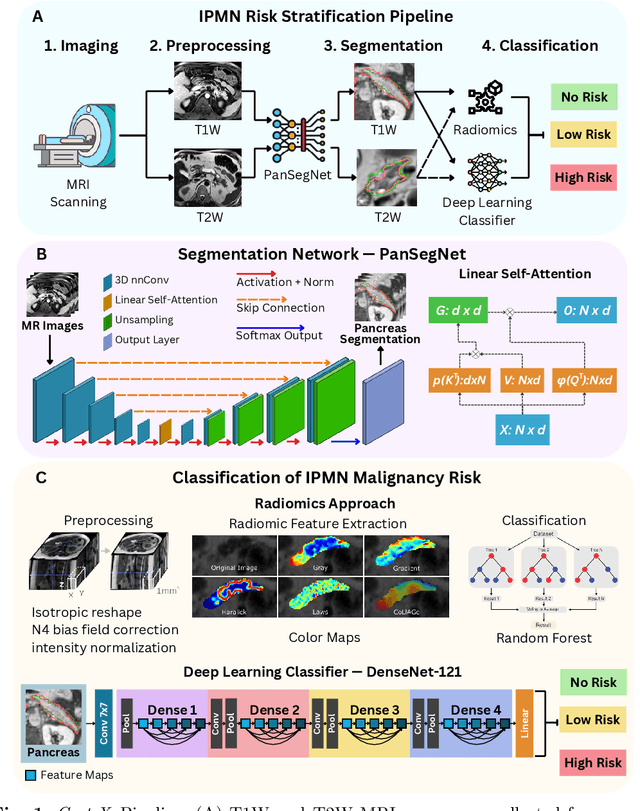

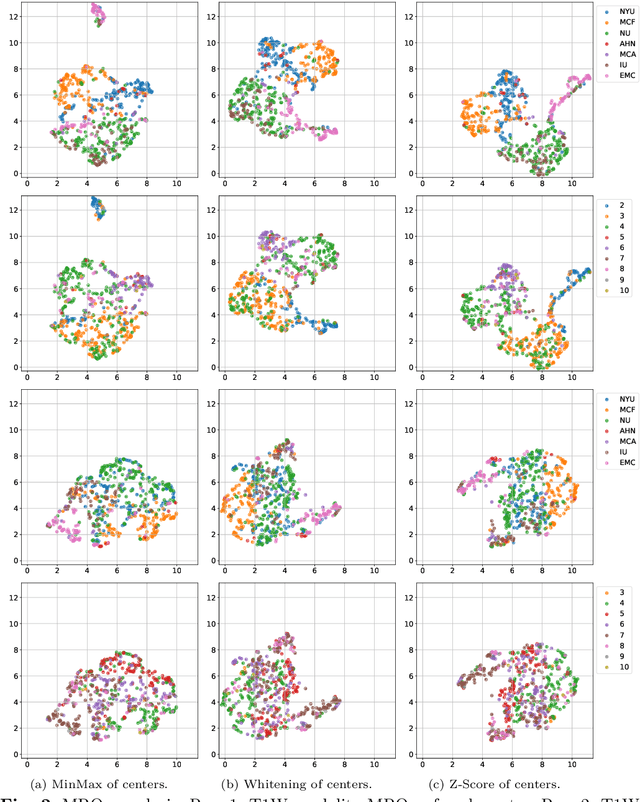
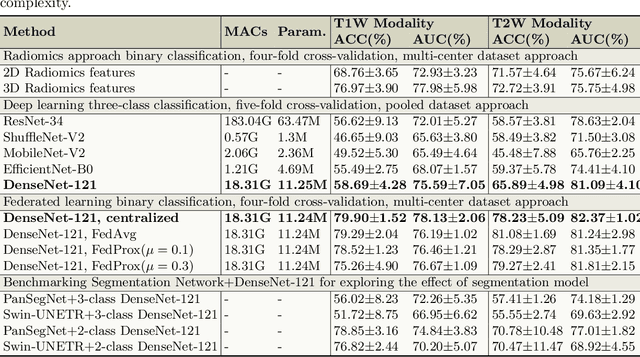
Pancreatic cancer is projected to become the second-deadliest malignancy in Western countries by 2030, highlighting the urgent need for better early detection. Intraductal papillary mucinous neoplasms (IPMNs), key precursors to pancreatic cancer, are challenging to assess with current guidelines, often leading to unnecessary surgeries or missed malignancies. We present Cyst-X, an AI framework that predicts IPMN malignancy using multicenter MRI data, leveraging MRI's superior soft tissue contrast over CT. Trained on 723 T1- and 738 T2-weighted scans from 764 patients across seven institutions, our models (AUC=0.82) significantly outperform both Kyoto guidelines (AUC=0.75) and expert radiologists. The AI-derived imaging features align with known clinical markers and offer biologically meaningful insights. We also demonstrate strong performance in a federated learning setting, enabling collaborative training without sharing patient data. To promote privacy-preserving AI development and improve IPMN risk stratification, the Cyst-X dataset is released as the first large-scale, multi-center pancreatic cysts MRI dataset.
Evidential Federated Learning for Skin Lesion Image Classification
Nov 15, 2024We introduce FedEvPrompt, a federated learning approach that integrates principles of evidential deep learning, prompt tuning, and knowledge distillation for distributed skin lesion classification. FedEvPrompt leverages two sets of prompts: b-prompts (for low-level basic visual knowledge) and t-prompts (for task-specific knowledge) prepended to frozen pre-trained Vision Transformer (ViT) models trained in an evidential learning framework to maximize class evidences. Crucially, knowledge sharing across federation clients is achieved only through knowledge distillation on attention maps generated by the local ViT models, ensuring enhanced privacy preservation compared to traditional parameter or synthetic image sharing methodologies. FedEvPrompt is optimized within a round-based learning paradigm, where each round involves training local models followed by attention maps sharing with all federation clients. Experimental validation conducted in a real distributed setting, on the ISIC2019 dataset, demonstrates the superior performance of FedEvPrompt against baseline federated learning algorithms and knowledge distillation methods, without sharing model parameters. In conclusion, FedEvPrompt offers a promising approach for federated learning, effectively addressing challenges such as data heterogeneity, imbalance, privacy preservation, and knowledge sharing.
FedRewind: Rewinding Continual Model Exchange for Decentralized Federated Learning
Nov 14, 2024



In this paper, we present FedRewind, a novel approach to decentralized federated learning that leverages model exchange among nodes to address the issue of data distribution shift. Drawing inspiration from continual learning (CL) principles and cognitive neuroscience theories for memory retention, FedRewind implements a decentralized routing mechanism where nodes send/receive models to/from other nodes in the federation to address spatial distribution challenges inherent in distributed learning (FL). During local training, federation nodes periodically send their models back (i.e., rewind) to the nodes they received them from for a limited number of iterations. This strategy reduces the distribution shift between nodes' data, leading to enhanced learning and generalization performance. We evaluate our method on multiple benchmarks, demonstrating its superiority over standard decentralized federated learning methods and those enforcing specific routing schemes within the federation. Furthermore, the combination of federated and continual learning concepts enables our method to tackle the more challenging federated continual learning task, with data shifts over both space and time, surpassing existing baselines.
FeDETR: a Federated Approach for Stenosis Detection in Coronary Angiography
Sep 21, 2024Assessing the severity of stenoses in coronary angiography is critical to the patient's health, as coronary stenosis is an underlying factor in heart failure. Current practice for grading coronary lesions, i.e. fractional flow reserve (FFR) or instantaneous wave-free ratio (iFR), suffers from several drawbacks, including time, cost and invasiveness, alongside potential interobserver variability. In this context, some deep learning methods have emerged to assist cardiologists in automating the estimation of FFR/iFR values. Despite the effectiveness of these methods, their reliance on large datasets is challenging due to the distributed nature of sensitive medical data. Federated learning addresses this challenge by aggregating knowledge from multiple nodes to improve model generalization, while preserving data privacy. We propose the first federated detection transformer approach, FeDETR, to assess stenosis severity in angiography videos based on FFR/iFR values estimation. In our approach, each node trains a detection transformer (DETR) on its local dataset, with the central server federating the backbone part of the network. The proposed method is trained and evaluated on a dataset collected from five hospitals, consisting of 1001 angiographic examinations, and its performance is compared with state-of-the-art federated learning methods.
Selective Attention-based Modulation for Continual Learning
Mar 29, 2024



We present SAM, a biologically-plausible selective attention-driven modulation approach to enhance classification models in a continual learning setting. Inspired by neurophysiological evidence that the primary visual cortex does not contribute to object manifold untangling for categorization and that primordial attention biases are still embedded in the modern brain, we propose to employ auxiliary saliency prediction features as a modulation signal to drive and stabilize the learning of a sequence of non-i.i.d. classification tasks. Experimental results confirm that SAM effectively enhances the performance (in some cases up to about twenty percent points) of state-of-the-art continual learning methods, both in class-incremental and task-incremental settings. Moreover, we show that attention-based modulation successfully encourages the learning of features that are more robust to the presence of spurious features and to adversarial attacks than baseline methods. Code is available at: https://github.com/perceivelab/SAM.
A Privacy-Preserving Walk in the Latent Space of Generative Models for Medical Applications
Jul 06, 2023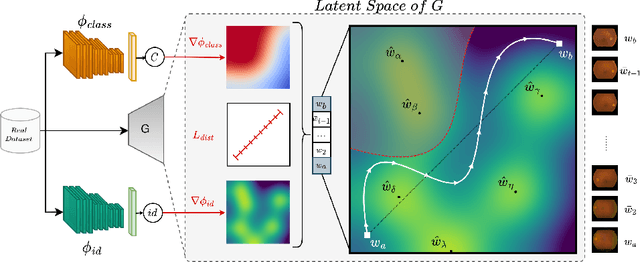
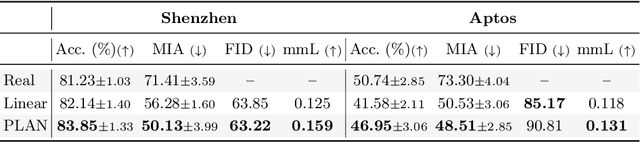
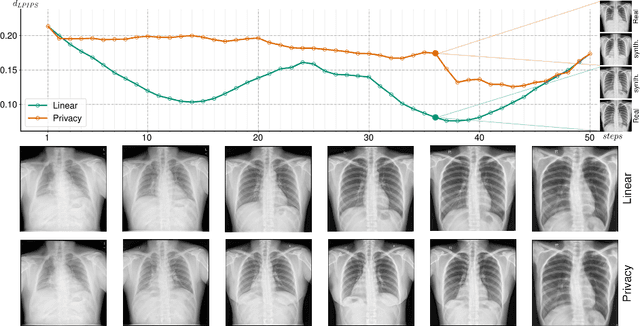

Generative Adversarial Networks (GANs) have demonstrated their ability to generate synthetic samples that match a target distribution. However, from a privacy perspective, using GANs as a proxy for data sharing is not a safe solution, as they tend to embed near-duplicates of real samples in the latent space. Recent works, inspired by k-anonymity principles, address this issue through sample aggregation in the latent space, with the drawback of reducing the dataset by a factor of k. Our work aims to mitigate this problem by proposing a latent space navigation strategy able to generate diverse synthetic samples that may support effective training of deep models, while addressing privacy concerns in a principled way. Our approach leverages an auxiliary identity classifier as a guide to non-linearly walk between points in the latent space, minimizing the risk of collision with near-duplicates of real samples. We empirically demonstrate that, given any random pair of points in the latent space, our walking strategy is safer than linear interpolation. We then test our path-finding strategy combined to k-same methods and demonstrate, on two benchmarks for tuberculosis and diabetic retinopathy classification, that training a model using samples generated by our approach mitigate drops in performance, while keeping privacy preservation.
TinyHD: Efficient Video Saliency Prediction with Heterogeneous Decoders using Hierarchical Maps Distillation
Jan 11, 2023



Video saliency prediction has recently attracted attention of the research community, as it is an upstream task for several practical applications. However, current solutions are particularly computationally demanding, especially due to the wide usage of spatio-temporal 3D convolutions. We observe that, while different model architectures achieve similar performance on benchmarks, visual variations between predicted saliency maps are still significant. Inspired by this intuition, we propose a lightweight model that employs multiple simple heterogeneous decoders and adopts several practical approaches to improve accuracy while keeping computational costs low, such as hierarchical multi-map knowledge distillation, multi-output saliency prediction, unlabeled auxiliary datasets and channel reduction with teacher assistant supervision. Our approach achieves saliency prediction accuracy on par or better than state-of-the-art methods on DFH1K, UCF-Sports and Hollywood2 benchmarks, while enhancing significantly the efficiency of the model. Code is on https://github.com/feiyanhu/tinyHD
Neural Transformers for Intraductal Papillary Mucosal Neoplasms (IPMN) Classification in MRI images
Jun 21, 2022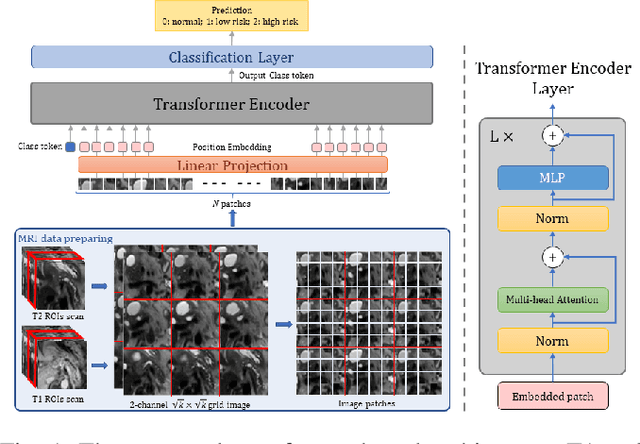
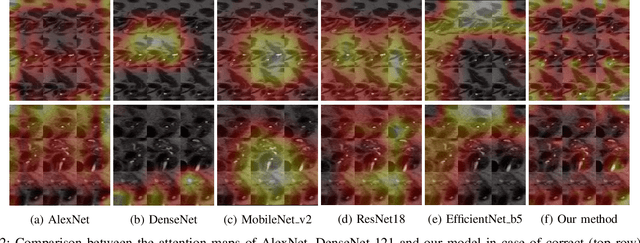

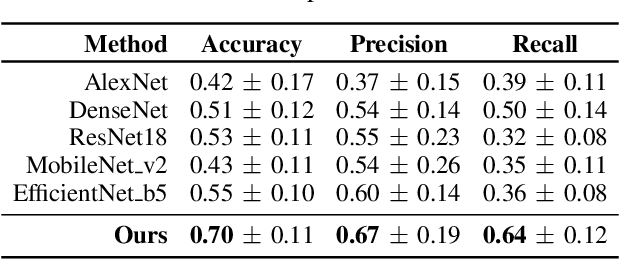
Early detection of precancerous cysts or neoplasms, i.e., Intraductal Papillary Mucosal Neoplasms (IPMN), in pancreas is a challenging and complex task, and it may lead to a more favourable outcome. Once detected, grading IPMNs accurately is also necessary, since low-risk IPMNs can be under surveillance program, while high-risk IPMNs have to be surgically resected before they turn into cancer. Current standards (Fukuoka and others) for IPMN classification show significant intra- and inter-operator variability, beside being error-prone, making a proper diagnosis unreliable. The established progress in artificial intelligence, through the deep learning paradigm, may provide a key tool for an effective support to medical decision for pancreatic cancer. In this work, we follow this trend, by proposing a novel AI-based IPMN classifier that leverages the recent success of transformer networks in generalizing across a wide variety of tasks, including vision ones. We specifically show that our transformer-based model exploits pre-training better than standard convolutional neural networks, thus supporting the sought architectural universalism of transformers in vision, including the medical image domain and it allows for a better interpretation of the obtained results.
Decentralized Distributed Learning with Privacy-Preserving Data Synthesis
Jun 20, 2022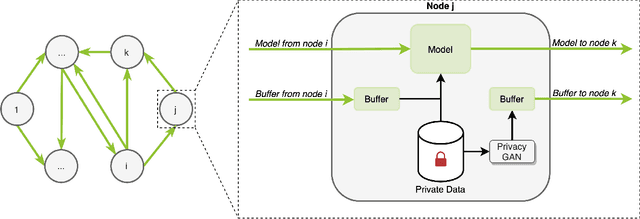
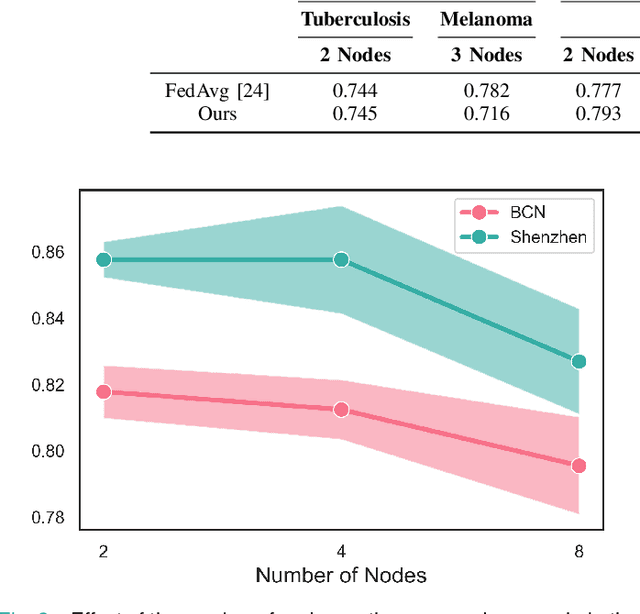
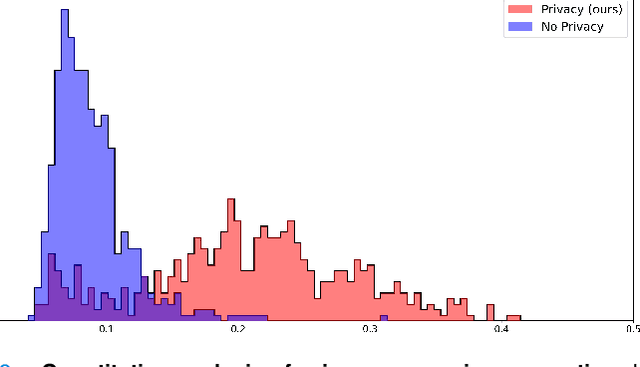
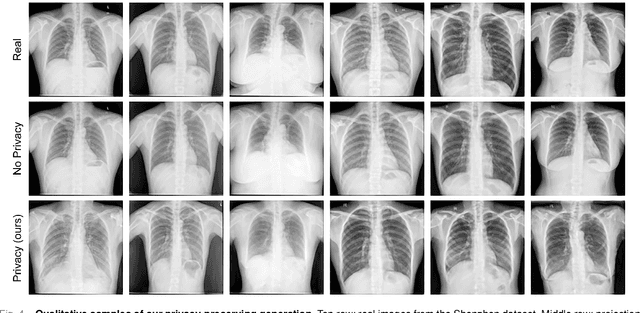
In the medical field, multi-center collaborations are often sought to yield more generalizable findings by leveraging the heterogeneity of patient and clinical data. However, recent privacy regulations hinder the possibility to share data, and consequently, to come up with machine learning-based solutions that support diagnosis and prognosis. Federated learning (FL) aims at sidestepping this limitation by bringing AI-based solutions to data owners and only sharing local AI models, or parts thereof, that need then to be aggregated. However, most of the existing federated learning solutions are still at their infancy and show several shortcomings, from the lack of a reliable and effective aggregation scheme able to retain the knowledge learned locally to weak privacy preservation as real data may be reconstructed from model updates. Furthermore, the majority of these approaches, especially those dealing with medical data, relies on a centralized distributed learning strategy that poses robustness, scalability and trust issues. In this paper we present a decentralized distributed method that, exploiting concepts from experience replay and generative adversarial research, effectively integrates features from local nodes, providing models able to generalize across multiple datasets while maintaining privacy. The proposed approach is tested on two tasks - tuberculosis and melanoma classification - using multiple datasets in order to simulate realistic non-i.i.d. data scenarios. Results show that our approach achieves performance comparable to both standard (non-federated) learning and federated methods in their centralized (thus, more favourable) formulation.