 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning meets Masked Video Modeling : Trajectory-Guided Adaptive Token Selection
May 13, 2025Masked video modeling~(MVM) has emerged as a highly effective pre-training strategy for visual foundation models, whereby the model reconstructs masked spatiotemporal tokens using information from visible tokens. However, a key challenge in such approaches lies in selecting an appropriate masking strategy. Previous studies have explored predefined masking techniques, including random and tube-based masking, as well as approaches that leverage key motion priors, optical flow and semantic cues from externally pre-trained models. In this work, we introduce a novel and generalizable Trajectory-Aware Adaptive Token Sampler (TATS), which models the motion dynamics of tokens and can be seamlessly integrated into the masked autoencoder (MAE) framework to select motion-centric tokens in videos. Additionally, we propose a unified training strategy that enables joint optimization of both MAE and TATS from scratch using Proximal Policy Optimization (PPO). We show that our model allows for aggressive masking without compromising performance on the downstream task of action recognition while also ensuring that the pre-training remains memory efficient. Extensive experiments of the proposed approach across four benchmarks, including Something-Something v2, Kinetics-400, UCF101, and HMDB51, demonstrate the effectiveness, transferability, generalization, and efficiency of our work compared to other state-of-the-art methods.
Video Anomaly Detection via Spatio-Temporal Pseudo-Anomaly Generation : A Unified Approach
Nov 27, 2023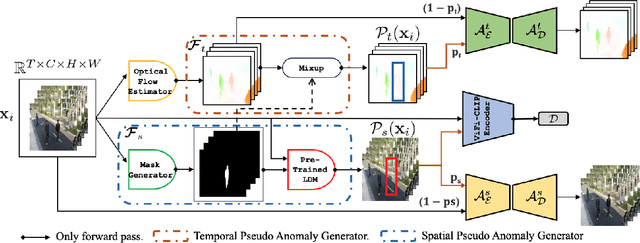
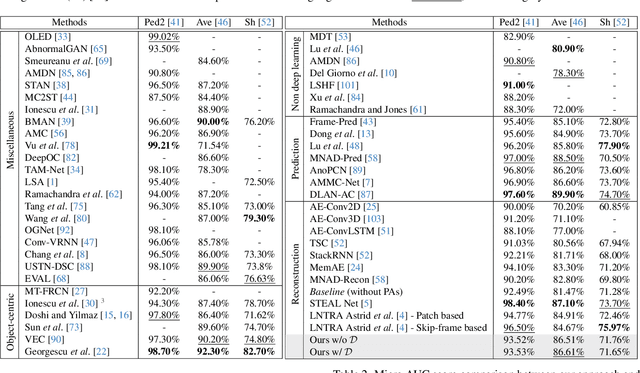


Video Anomaly Detection (VAD) is an open-set recognition task, which is usually formulated as a one-class classification (OCC) problem, where training data is comprised of videos with normal instances while test data contains both normal and anomalous instances. Recent works have investigated the creation of pseudo-anomalies (PAs) using only the normal data and making strong assumptions about real-world anomalies with regards to abnormality of objects and speed of motion to inject prior information about anomalies in an autoencoder (AE) based reconstruction model during training. This work proposes a novel method for generating generic spatio-temporal PAs by inpainting a masked out region of an image using a pre-trained Latent Diffusion Model and further perturbing the optical flow using mixup to emulate spatio-temporal distortions in the data. In addition, we present a simple unified framework to detect real-world anomalies under the OCC setting by learning three types of anomaly indicators, namely reconstruction quality, temporal irregularity and semantic inconsistency. Extensive experiments on four VAD benchmark datasets namely Ped2, Avenue, ShanghaiTech and UBnormal demonstrate that our method performs on par with other existing state-of-the-art PAs generation and reconstruction based methods under the OCC setting. Our analysis also examines the transferability and generalisation of PAs across these datasets, offering valuable insights by identifying real-world anomalies through PAs.
TinyHD: Efficient Video Saliency Prediction with Heterogeneous Decoders using Hierarchical Maps Distillation
Jan 11, 2023



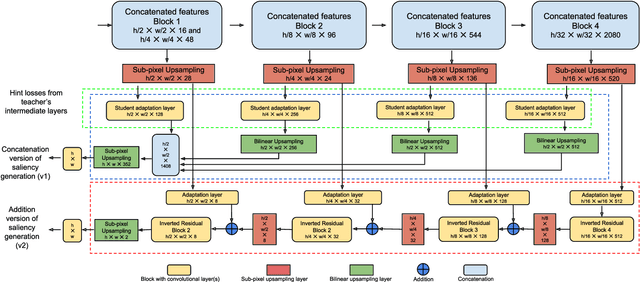
Video saliency prediction has recently attracted attention of the research community, as it is an upstream task for several practical applications. However, current solutions are particularly computationally demanding, especially due to the wide usage of spatio-temporal 3D convolutions. We observe that, while different model architectures achieve similar performance on benchmarks, visual variations between predicted saliency maps are still significant. Inspired by this intuition, we propose a lightweight model that employs multiple simple heterogeneous decoders and adopts several practical approaches to improve accuracy while keeping computational costs low, such as hierarchical multi-map knowledge distillation, multi-output saliency prediction, unlabeled auxiliary datasets and channel reduction with teacher assistant supervision. Our approach achieves saliency prediction accuracy on par or better than state-of-the-art methods on DFH1K, UCF-Sports and Hollywood2 benchmarks, while enhancing significantly the efficiency of the model. Code is on https://github.com/feiyanhu/tinyHD
Fast and Robust Video-Based Exercise Classification via Body Pose Tracking and Scalable Multivariate Time Series Classifiers
Oct 02, 2022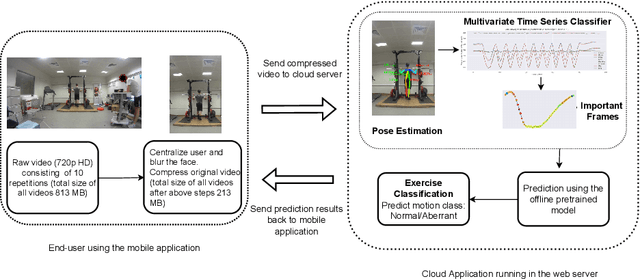


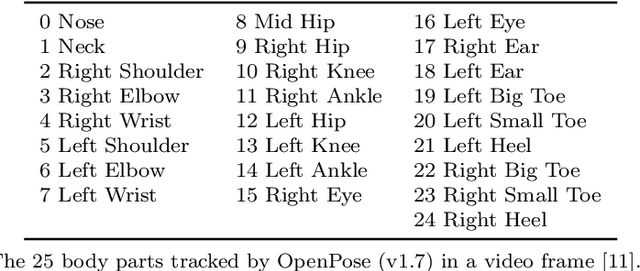
Technological advancements have spurred the usage of machine learning based applications in sports science. Physiotherapists, sports coaches and athletes actively look to incorporate the latest technologies in order to further improve performance and avoid injuries. While wearable sensors are very popular, their use is hindered by constraints on battery power and sensor calibration, especially for use cases which require multiple sensors to be placed on the body. Hence, there is renewed interest in video-based data capture and analysis for sports science. In this paper, we present the application of classifying S\&C exercises using video. We focus on the popular Military Press exercise, where the execution is captured with a video-camera using a mobile device, such as a mobile phone, and the goal is to classify the execution into different types. Since video recordings need a lot of storage and computation, this use case requires data reduction, while preserving the classification accuracy and enabling fast prediction. To this end, we propose an approach named BodyMTS to turn video into time series by employing body pose tracking, followed by training and prediction using multivariate time series classifiers. We analyze the accuracy and robustness of BodyMTS and show that it is robust to different types of noise caused by either video quality or pose estimation factors. We compare BodyMTS to state-of-the-art deep learning methods which classify human activity directly from videos and show that BodyMTS achieves similar accuracy, but with reduced running time and model engineering effort. Finally, we discuss some of the practical aspects of employing BodyMTS in this application in terms of accuracy and robustness under reduced data quality and size. We show that BodyMTS achieves an average accuracy of 87\%, which is significantly higher than the accuracy of human domain experts.
Improving Person Re-Identification with Temporal Constraints
Nov 17, 2021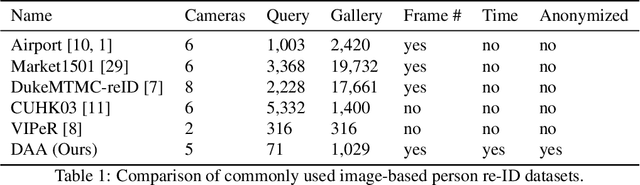

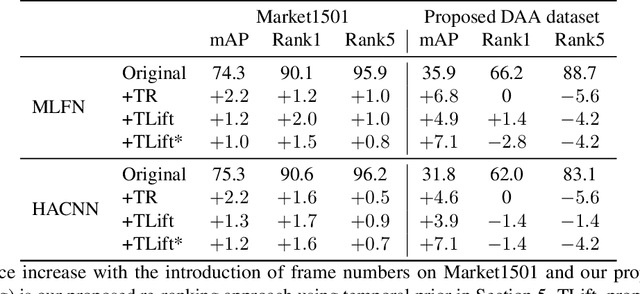
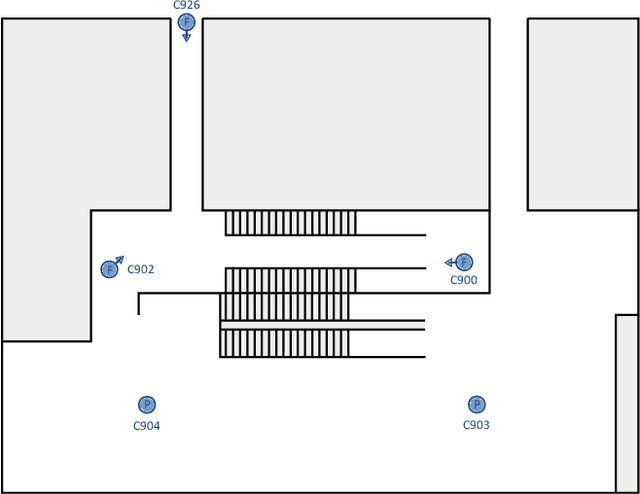
In this paper we introduce an image-based person re-identification dataset collected across five non-overlapping camera views in the large and busy airport in Dublin, Ireland. Unlike all publicly available image-based datasets, our dataset contains timestamp information in addition to frame number, and camera and person IDs. Also our dataset has been fully anonymized to comply with modern data privacy regulations. We apply state-of-the-art person re-identification models to our dataset and show that by leveraging the available timestamp information we are able to achieve a significant gain of 37.43% in mAP and a gain of 30.22% in Rank1 accuracy. We also propose a Bayesian temporal re-ranking post-processing step, which further adds a 10.03% gain in mAP and 9.95% gain in Rank1 accuracy metrics. This work on combining visual and temporal information is not possible on other image-based person re-identification datasets. We believe that the proposed new dataset will enable further development of person re-identification research for challenging real-world applications. DAA dataset can be downloaded from https://bit.ly/3AtXTd6
Temporal Bilinear Encoding Network of Audio-Visual Features at Low Sampling Rates
Dec 18, 2020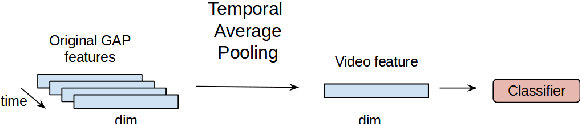

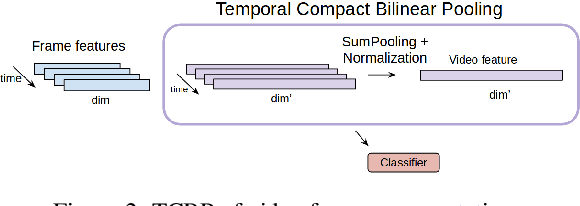
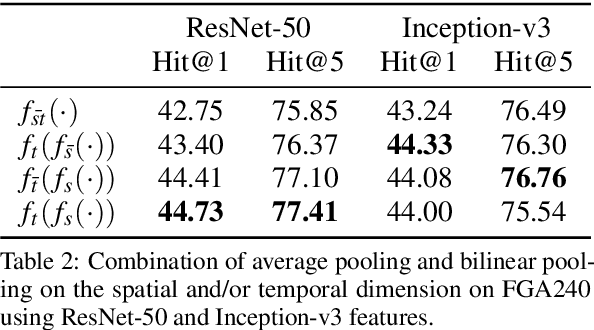
Current deep learning based video classification architectures are typically trained end-to-end on large volumes of data and require extensive computational resources. This paper aims to exploit audio-visual information in video classification with a 1 frame per second sampling rate. We propose Temporal Bilinear Encoding Networks (TBEN) for encoding both audio and visual long range temporal information using bilinear pooling and demonstrate bilinear pooling is better than average pooling on the temporal dimension for videos with low sampling rate. We also embed the label hierarchy in TBEN to further improve the robustness of the classifier. Experiments on the FGA240 fine-grained classification dataset using TBEN achieve a new state-of-the-art (hit@1=47.95%). We also exploit the possibility of incorporating TBEN with multiple decoupled modalities like visual semantic and motion features: experiments on UCF101 sampled at 1 FPS achieve close to state-of-the-art accuracy (hit@1=91.03%) while requiring significantly less computational resources than competing approaches for both training and prediction.
FastSal: a Computationally Efficient Network for Visual Saliency Prediction
Aug 25, 2020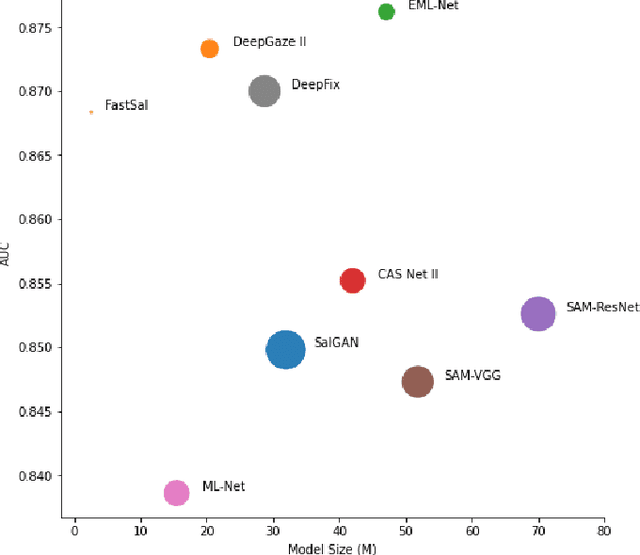
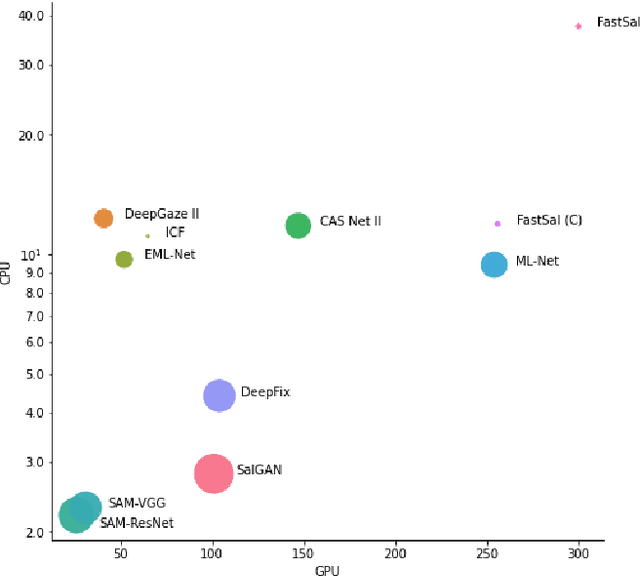
This paper focuses on the problem of visual saliency prediction, predicting regions of an image that tend to attract human visual attention, under a constrained computational budget. We modify and test various recent efficient convolutional neural network architectures like EfficientNet and MobileNetV2 and compare them with existing state-of-the-art saliency models such as SalGAN and DeepGaze II both in terms of standard accuracy metrics like AUC and NSS, and in terms of the computational complexity and model size. We find that MobileNetV2 makes an excellent backbone for a visual saliency model and can be effective even without a complex decoder. We also show that knowledge transfer from a more computationally expensive model like DeepGaze II can be achieved via pseudo-labelling an unlabelled dataset, and that this approach gives result on-par with many state-of-the-art algorithms with a fraction of the computational cost and model size. Source code is available at https://github.com/feiyanhu/FastSal.
Utilising Visual Attention Cues for Vehicle Detection and Tracking
Jul 31, 2020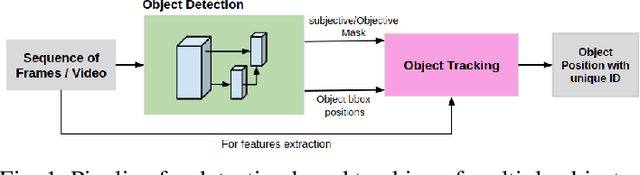

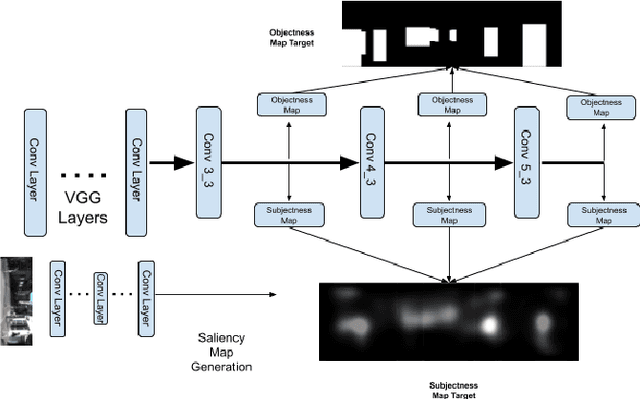
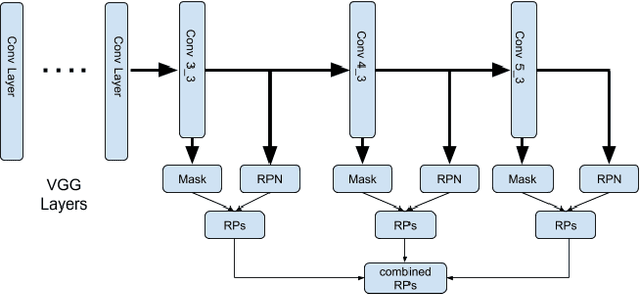
Advanced Driver-Assistance Systems (ADAS) have been attracting attention from many researchers. Vision-based sensors are the closest way to emulate human driver visual behavior while driving. In this paper, we explore possible ways to use visual attention (saliency) for object detection and tracking. We investigate: 1) How a visual attention map such as a \emph{subjectness} attention or saliency map and an \emph{objectness} attention map can facilitate region proposal generation in a 2-stage object detector; 2) How a visual attention map can be used for tracking multiple objects. We propose a neural network that can simultaneously detect objects as and generate objectness and subjectness maps to save computational power. We further exploit the visual attention map during tracking using a sequential Monte Carlo probability hypothesis density (PHD) filter. The experiments are conducted on KITTI and DETRAC datasets. The use of visual attention and hierarchical features has shown a considerable improvement of $\approx$8\% in object detection which effectively increased tracking performance by $\approx$4\% on KITTI dataset.