 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Bilinear Encoding Network of Audio-Visual Features at Low Sampling Rates
Paper and Code
Dec 18, 2020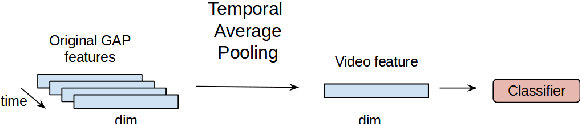

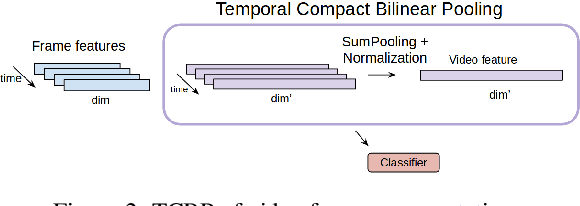
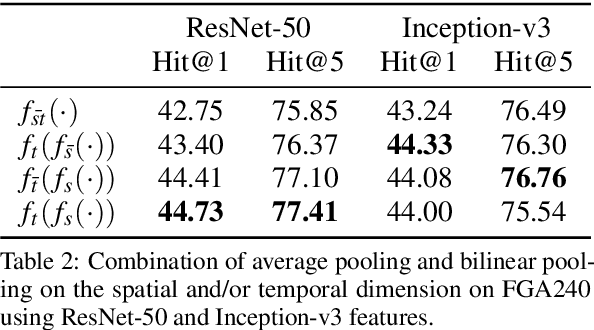
Current deep learning based video classification architectures are typically trained end-to-end on large volumes of data and require extensive computational resources. This paper aims to exploit audio-visual information in video classification with a 1 frame per second sampling rate. We propose Temporal Bilinear Encoding Networks (TBEN) for encoding both audio and visual long range temporal information using bilinear pooling and demonstrate bilinear pooling is better than average pooling on the temporal dimension for videos with low sampling rate. We also embed the label hierarchy in TBEN to further improve the robustness of the classifier. Experiments on the FGA240 fine-grained classification dataset using TBEN achieve a new state-of-the-art (hit@1=47.95%). We also exploit the possibility of incorporating TBEN with multiple decoupled modalities like visual semantic and motion features: experiments on UCF101 sampled at 1 FPS achieve close to state-of-the-art accuracy (hit@1=91.03%) while requiring significantly less computational resources than competing approaches for both training and prediction.