 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn accurate detection is not all you need to combat label noise in web-noisy datasets
Jul 08, 2024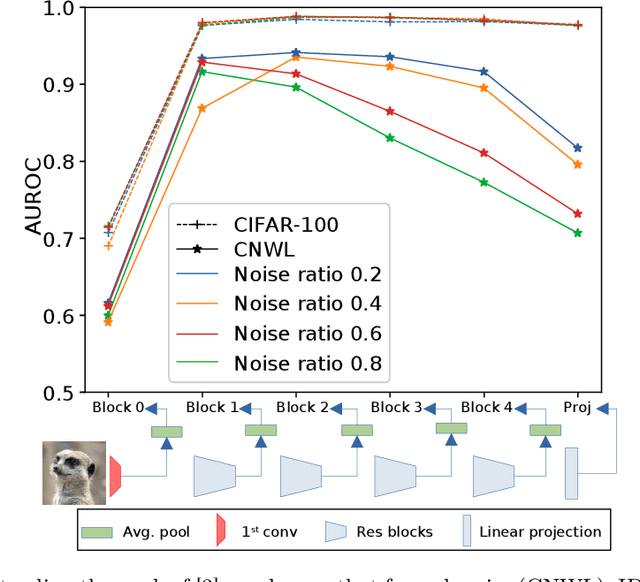
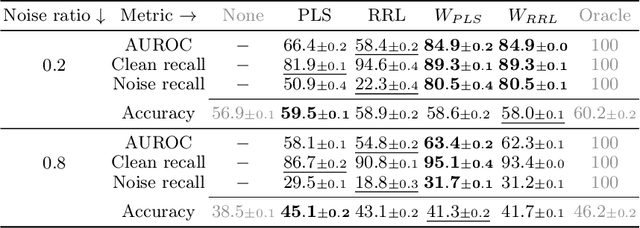

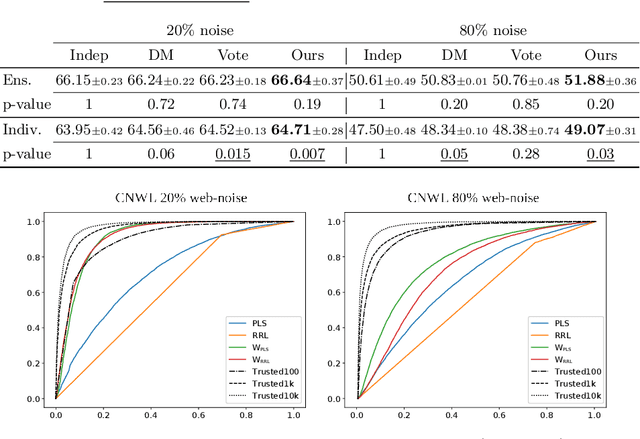
Training a classifier on web-crawled data demands learning algorithms that are robust to annotation errors and irrelevant examples. This paper builds upon the recent empirical observation that applying unsupervised contrastive learning to noisy, web-crawled datasets yields a feature representation under which the in-distribution (ID) and out-of-distribution (OOD) samples are linearly separable. We show that direct estimation of the separating hyperplane can indeed offer an accurate detection of OOD samples, and yet, surprisingly, this detection does not translate into gains in classification accuracy. Digging deeper into this phenomenon, we discover that the near-perfect detection misses a type of clean examples that are valuable for supervised learning. These examples often represent visually simple images, which are relatively easy to identify as clean examples using standard loss- or distance-based methods despite being poorly separated from the OOD distribution using unsupervised learning. Because we further observe a low correlation with SOTA metrics, this urges us to propose a hybrid solution that alternates between noise detection using linear separation and a state-of-the-art (SOTA) small-loss approach. When combined with the SOTA algorithm PLS, we substantially improve SOTA results for real-world image classification in the presence of web noise github.com/PaulAlbert31/LSA
Dataset Clustering for Improved Offline Policy Learning
Feb 14, 2024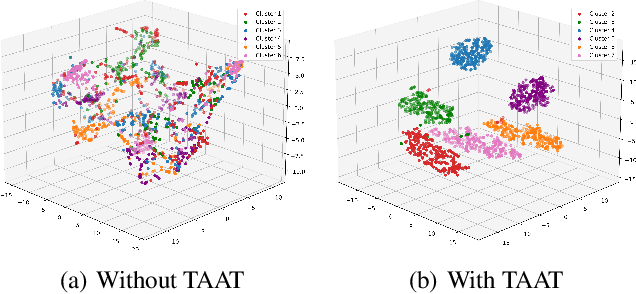
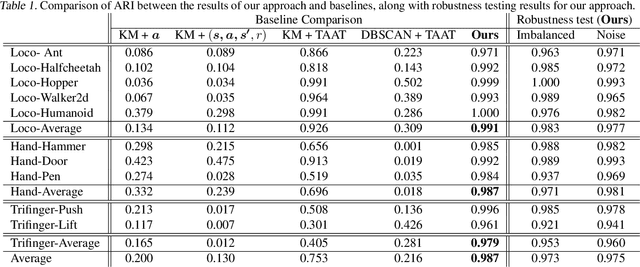
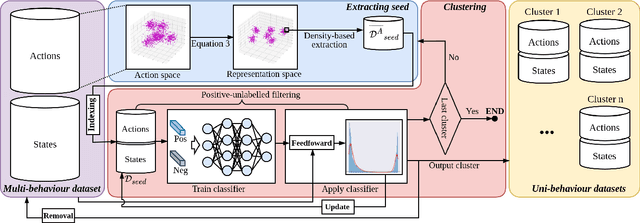

Offline policy learning aims to discover decision-making policies from previously-collected datasets without additional online interactions with the environment. As the training dataset is fixed, its quality becomes a crucial determining factor in the performance of the learned policy. This paper studies a dataset characteristic that we refer to as multi-behavior, indicating that the dataset is collected using multiple policies that exhibit distinct behaviors. In contrast, a uni-behavior dataset would be collected solely using one policy. We observed that policies learned from a uni-behavior dataset typically outperform those learned from multi-behavior datasets, despite the uni-behavior dataset having fewer examples and less diversity. Therefore, we propose a behavior-aware deep clustering approach that partitions multi-behavior datasets into several uni-behavior subsets, thereby benefiting downstream policy learning. Our approach is flexible and effective; it can adaptively estimate the number of clusters while demonstrating high clustering accuracy, achieving an average Adjusted Rand Index of 0.987 across various continuous control task datasets. Finally, we present improved policy learning examples using dataset clustering and discuss several potential scenarios where our approach might benefit the offline policy learning community.
Video Anomaly Detection via Spatio-Temporal Pseudo-Anomaly Generation : A Unified Approach
Nov 27, 2023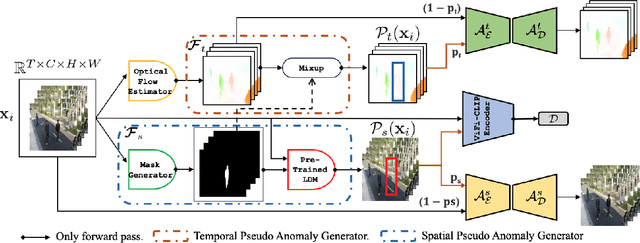
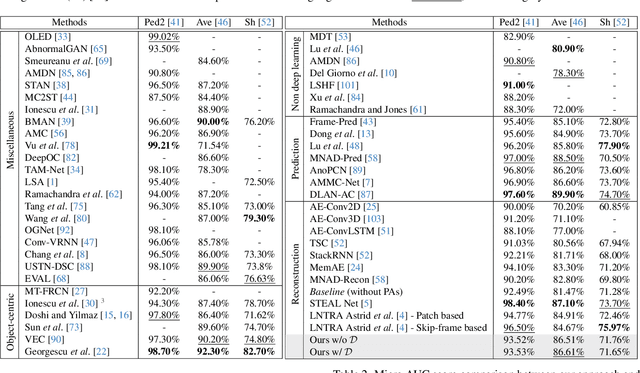


Video Anomaly Detection (VAD) is an open-set recognition task, which is usually formulated as a one-class classification (OCC) problem, where training data is comprised of videos with normal instances while test data contains both normal and anomalous instances. Recent works have investigated the creation of pseudo-anomalies (PAs) using only the normal data and making strong assumptions about real-world anomalies with regards to abnormality of objects and speed of motion to inject prior information about anomalies in an autoencoder (AE) based reconstruction model during training. This work proposes a novel method for generating generic spatio-temporal PAs by inpainting a masked out region of an image using a pre-trained Latent Diffusion Model and further perturbing the optical flow using mixup to emulate spatio-temporal distortions in the data. In addition, we present a simple unified framework to detect real-world anomalies under the OCC setting by learning three types of anomaly indicators, namely reconstruction quality, temporal irregularity and semantic inconsistency. Extensive experiments on four VAD benchmark datasets namely Ped2, Avenue, ShanghaiTech and UBnormal demonstrate that our method performs on par with other existing state-of-the-art PAs generation and reconstruction based methods under the OCC setting. Our analysis also examines the transferability and generalisation of PAs across these datasets, offering valuable insights by identifying real-world anomalies through PAs.
Learning and reusing primitive behaviours to improve Hindsight Experience Replay sample efficiency
Oct 03, 2023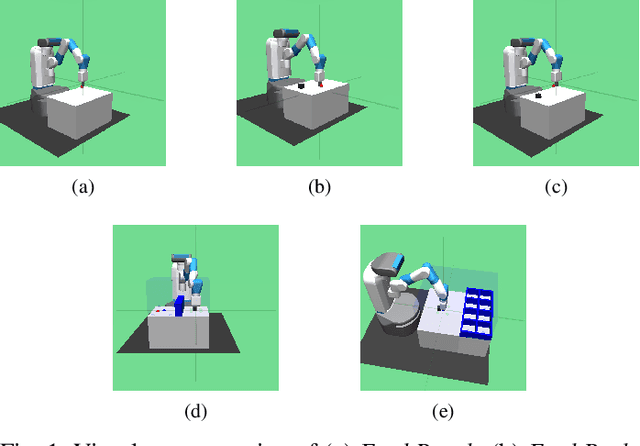
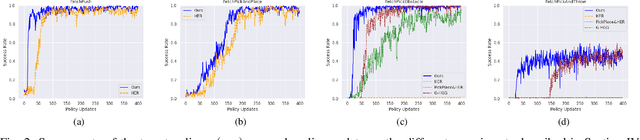
Hindsight Experience Replay (HER) is a technique used in reinforcement learning (RL) that has proven to be very efficient for training off-policy RL-based agents to solve goal-based robotic manipulation tasks using sparse rewards. Even though HER improves the sample efficiency of RL-based agents by learning from mistakes made in past experiences, it does not provide any guidance while exploring the environment. This leads to very large training times due to the volume of experience required to train an agent using this replay strategy. In this paper, we propose a method that uses primitive behaviours that have been previously learned to solve simple tasks in order to guide the agent toward more rewarding actions during exploration while learning other more complex tasks. This guidance, however, is not executed by a manually designed curriculum, but rather using a critic network to decide at each timestep whether or not to use the actions proposed by the previously-learned primitive policies. We evaluate our method by comparing its performance against HER and other more efficient variations of this algorithm in several block manipulation tasks. We demonstrate the agents can learn a successful policy faster when using our proposed method, both in terms of sample efficiency and computation time. Code is available at https://github.com/franroldans/qmp-her.
Enhancing CLIP with GPT-4: Harnessing Visual Descriptions as Prompts
Aug 08, 2023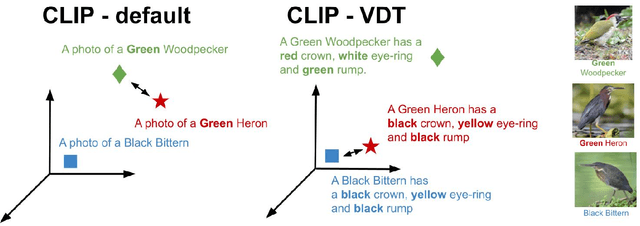


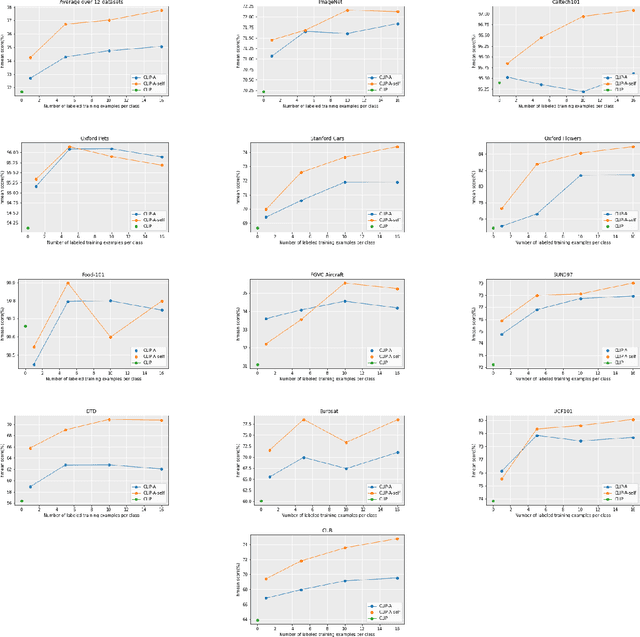
Contrastive pretrained large Vision-Language Models (VLMs) like CLIP have revolutionized visual representation learning by providing good performance on downstream datasets. VLMs are 0-shot adapted to a downstream dataset by designing prompts that are relevant to the dataset. Such prompt engineering makes use of domain expertise and a validation dataset. Meanwhile, recent developments in generative pretrained models like GPT-4 mean they can be used as advanced internet search tools. They can also be manipulated to provide visual information in any structure. In this work, we show that GPT-4 can be used to generate text that is visually descriptive and how this can be used to adapt CLIP to downstream tasks. We show considerable improvements in 0-shot transfer accuracy on specialized fine-grained datasets like EuroSAT (~7%), DTD (~7%), SUN397 (~4.6%), and CUB (~3.3%) when compared to CLIP's default prompt. We also design a simple few-shot adapter that learns to choose the best possible sentences to construct generalizable classifiers that outperform the recently proposed CoCoOP by ~2% on average and by over 4% on 4 specialized fine-grained datasets. The code, prompts, and auxiliary text dataset is available at https://github.com/mayug/VDT-Adapter.
Self-Supervised and Semi-Supervised Polyp Segmentation using Synthetic Data
Jul 22, 2023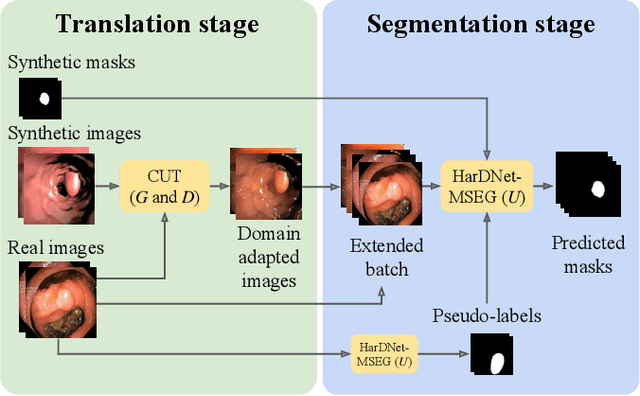
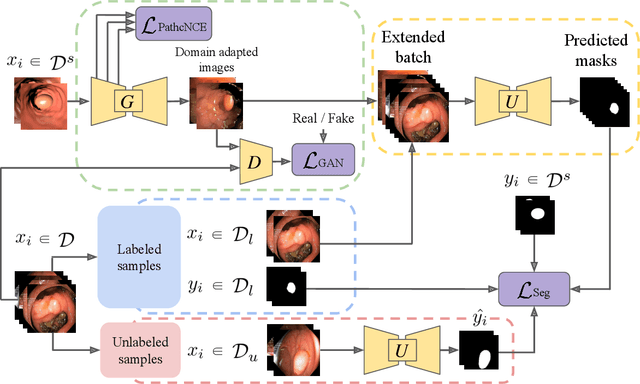
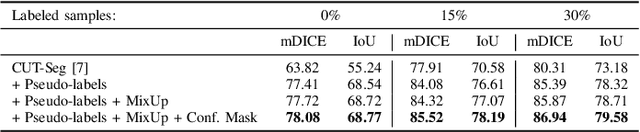
Early detection of colorectal polyps is of utmost importance for their treatment and for colorectal cancer prevention. Computer vision techniques have the potential to aid professionals in the diagnosis stage, where colonoscopies are manually carried out to examine the entirety of the patient's colon. The main challenge in medical imaging is the lack of data, and a further challenge specific to polyp segmentation approaches is the difficulty of manually labeling the available data: the annotation process for segmentation tasks is very time-consuming. While most recent approaches address the data availability challenge with sophisticated techniques to better exploit the available labeled data, few of them explore the self-supervised or semi-supervised paradigm, where the amount of labeling required is greatly reduced. To address both challenges, we leverage synthetic data and propose an end-to-end model for polyp segmentation that integrates real and synthetic data to artificially increase the size of the datasets and aid the training when unlabeled samples are available. Concretely, our model, Pl-CUT-Seg, transforms synthetic images with an image-to-image translation module and combines the resulting images with real images to train a segmentation model, where we use model predictions as pseudo-labels to better leverage unlabeled samples. Additionally, we propose PL-CUT-Seg+, an improved version of the model that incorporates targeted regularization to address the domain gap between real and synthetic images. The models are evaluated on standard benchmarks for polyp segmentation and reach state-of-the-art results in the self- and semi-supervised setups.
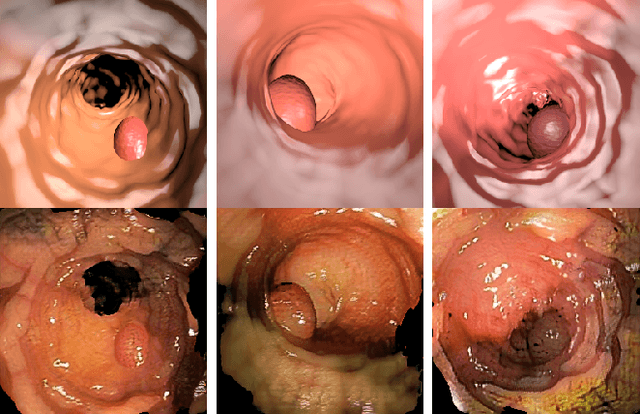
Joint one-sided synthetic unpaired image translation and segmentation for colorectal cancer prevention
Jul 20, 2023Deep learning has shown excellent performance in analysing medical images. However, datasets are difficult to obtain due privacy issues, standardization problems, and lack of annotations. We address these problems by producing realistic synthetic images using a combination of 3D technologies and generative adversarial networks. We propose CUT-seg, a joint training where a segmentation model and a generative model are jointly trained to produce realistic images while learning to segment polyps. We take advantage of recent one-sided translation models because they use significantly less memory, allowing us to add a segmentation model in the training loop. CUT-seg performs better, is computationally less expensive, and requires less real images than other memory-intensive image translation approaches that require two stage training. Promising results are achieved on five real polyp segmentation datasets using only one real image and zero real annotations. As a part of this study we release Synth-Colon, an entirely synthetic dataset that includes 20000 realistic colon images and additional details about depth and 3D geometry: https://enric1994.github.io/synth-colon
An Ensemble Deep Learning Approach for COVID-19 Severity Prediction Using Chest CT Scans
May 17, 2023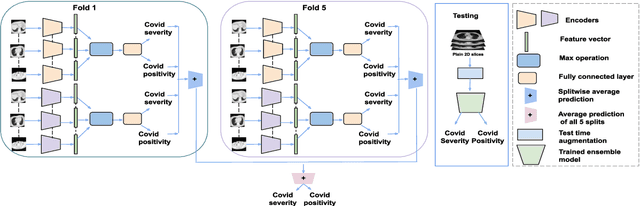
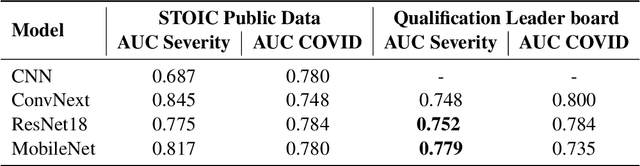

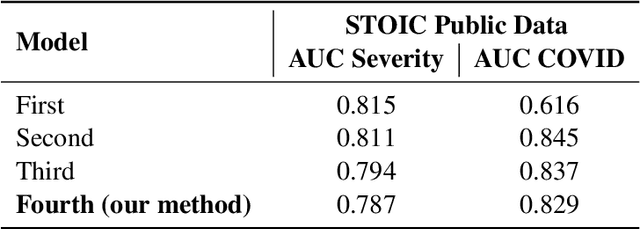
Chest X-rays have been widely used for COVID-19 screening; however, 3D computed tomography (CT) is a more effective modality. We present our findings on COVID-19 severity prediction from chest CT scans using the STOIC dataset. We developed an ensemble deep learning based model that incorporates multiple neural networks to improve predictions. To address data imbalance, we used slicing functions and data augmentation. We further improved performance using test time data augmentation. Our approach which employs a simple yet effective ensemble of deep learning-based models with strong test time augmentations, achieved results comparable to more complex methods and secured the fourth position in the STOIC2021 COVID-19 AI Challenge. Our code is available on online: at: https://github.com/aleemsidra/stoic2021- baseline-finalphase-main.
Site-specific Deep Learning Path Loss Models based on the Method of Moments
Feb 02, 2023This paper describes deep learning models based on convolutional neural networks applied to the problem of predicting EM wave propagation over rural terrain. A surface integral equation formulation, solved with the method of moments and accelerated using the Fast Far Field approximation, is used to generate synthetic training data which comprises path loss computed over randomly generated 1D terrain profiles. These are used to train two networks, one based on fractal profiles and one based on profiles generated using a Gaussian process. The models show excellent agreement when applied to test profiles generated using the same statistical process used to create the training data and very good accuracy when applied to real life problems.
Behaviour Discriminator: A Simple Data Filtering Method to Improve Offline Policy Learning
Jan 27, 2023This paper studies the problem of learning a control policy without the need for interactions with the environment; instead, learning purely from an existing dataset. Prior work has demonstrated that offline learning algorithms (e.g., behavioural cloning and offline reinforcement learning) are more likely to discover a satisfactory policy when trained using high-quality expert data. However, many real-world/practical datasets can contain significant proportions of examples generated using low-skilled agents. Therefore, we propose a behaviour discriminator (BD) concept, a novel and simple data filtering approach based on semi-supervised learning, which can accurately discern expert data from a mixed-quality dataset. Our BD approach was used to pre-process the mixed-skill-level datasets from the Real Robot Challenge (RRC) III, an open competition requiring participants to solve several dexterous robotic manipulation tasks using offline learning methods; the new BD method allowed a standard behavioural cloning algorithm to outperform other more sophisticated offline learning algorithms. Moreover, we demonstrate that the new BD pre-processing method can be applied to a number of D4RL benchmark problems, improving the performance of multiple state-of-the-art offline reinforcement learning algorithms.