 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing CLIP with GPT-4: Harnessing Visual Descriptions as Prompts
Aug 08, 2023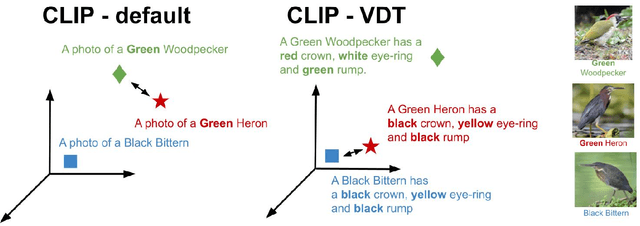


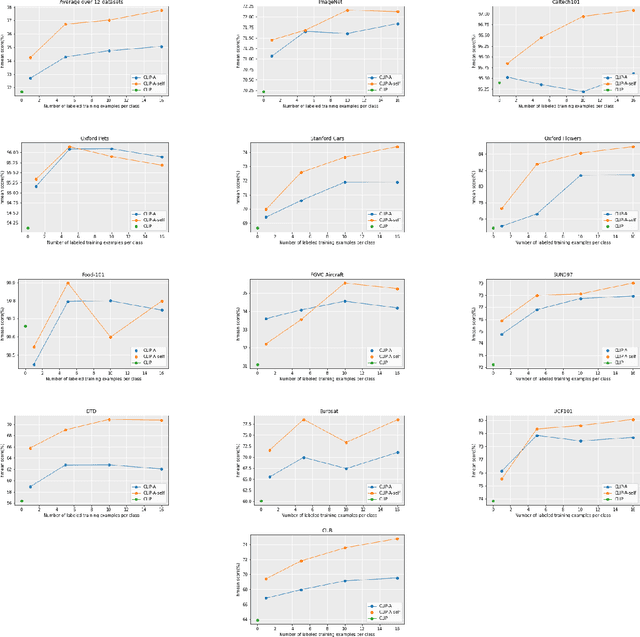
Contrastive pretrained large Vision-Language Models (VLMs) like CLIP have revolutionized visual representation learning by providing good performance on downstream datasets. VLMs are 0-shot adapted to a downstream dataset by designing prompts that are relevant to the dataset. Such prompt engineering makes use of domain expertise and a validation dataset. Meanwhile, recent developments in generative pretrained models like GPT-4 mean they can be used as advanced internet search tools. They can also be manipulated to provide visual information in any structure. In this work, we show that GPT-4 can be used to generate text that is visually descriptive and how this can be used to adapt CLIP to downstream tasks. We show considerable improvements in 0-shot transfer accuracy on specialized fine-grained datasets like EuroSAT (~7%), DTD (~7%), SUN397 (~4.6%), and CUB (~3.3%) when compared to CLIP's default prompt. We also design a simple few-shot adapter that learns to choose the best possible sentences to construct generalizable classifiers that outperform the recently proposed CoCoOP by ~2% on average and by over 4% on 4 specialized fine-grained datasets. The code, prompts, and auxiliary text dataset is available at https://github.com/mayug/VDT-Adapter.