 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePinpoint Counterfactuals: Reducing social bias in foundation models via localized counterfactual generation
Dec 12, 2024
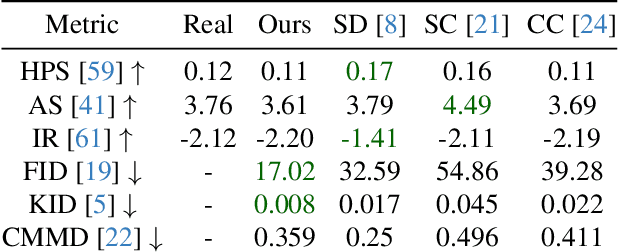

Foundation models trained on web-scraped datasets propagate societal biases to downstream tasks. While counterfactual generation enables bias analysis, existing methods introduce artifacts by modifying contextual elements like clothing and background. We present a localized counterfactual generation method that preserves image context by constraining counterfactual modifications to specific attribute-relevant regions through automated masking and guided inpainting. When applied to the Conceptual Captions dataset for creating gender counterfactuals, our method results in higher visual and semantic fidelity than state-of-the-art alternatives, while maintaining the performance of models trained using only real data on non-human-centric tasks. Models fine-tuned with our counterfactuals demonstrate measurable bias reduction across multiple metrics, including a decrease in gender classification disparity and balanced person preference scores, while preserving ImageNet zero-shot performance. The results establish a framework for creating balanced datasets that enable both accurate bias profiling and effective mitigation.
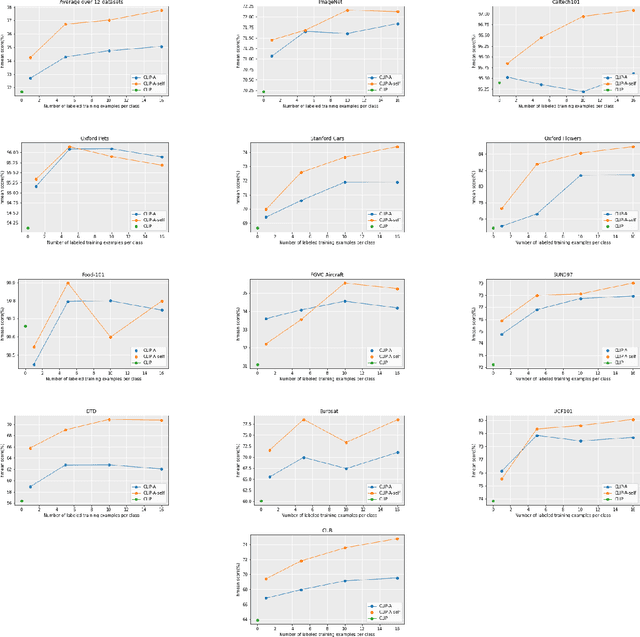
From Unimodal to Multimodal: Scaling up Projectors to Align Modalities
Sep 28, 2024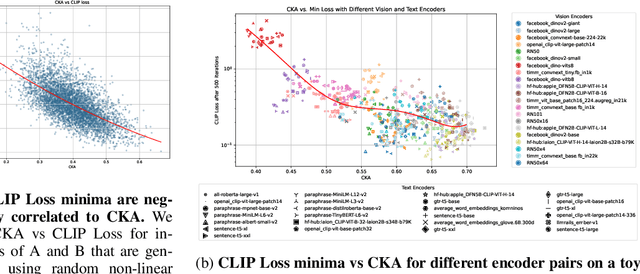
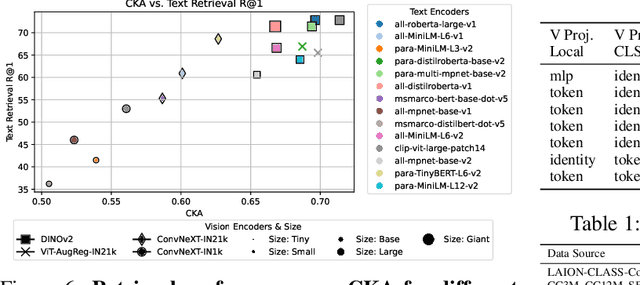

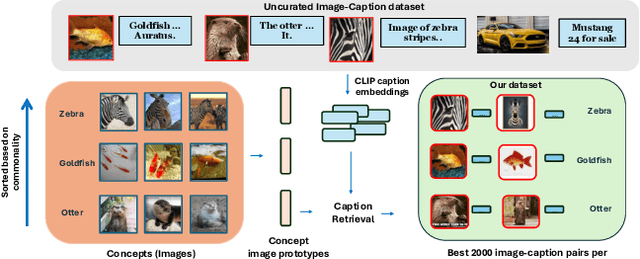
Recent contrastive multimodal vision-language models like CLIP have demonstrated robust open-world semantic understanding, becoming the standard image backbones for vision-language applications due to their aligned latent space. However, this practice has left powerful unimodal encoders for both vision and language underutilized in multimodal applications which raises a key question: Is there a plausible way to connect unimodal backbones for zero-shot vision-language tasks? To this end, we propose a novel approach that aligns vision and language modalities using only projection layers on pretrained, frozen unimodal encoders. Our method exploits the high semantic similarity between embedding spaces of well-trained vision and language models. It involves selecting semantically similar encoders in the latent space, curating a concept-rich dataset of image-caption pairs, and training simple MLP projectors. We evaluated our approach on 12 zero-shot classification datasets and 2 image-text retrieval datasets. Our best model, utilizing DINOv2 and All-Roberta-Large text encoder, achieves 76\(\%\) accuracy on ImageNet with a 20-fold reduction in data and 65 fold reduction in compute requirements. The proposed framework enhances the accessibility of model development while enabling flexible adaptation across diverse scenarios, offering an efficient approach to building multimodal models by utilizing existing unimodal architectures. Code and datasets will be released soon.
Test-Time Adaptation with SaLIP: A Cascade of SAM and CLIP for Zero shot Medical Image Segmentation
Apr 09, 2024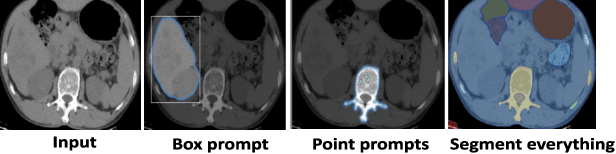
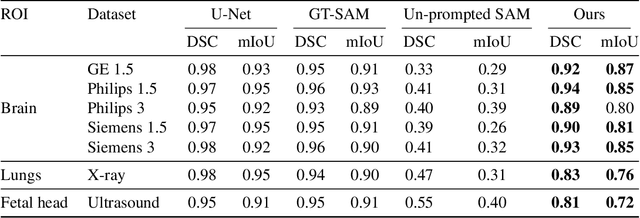
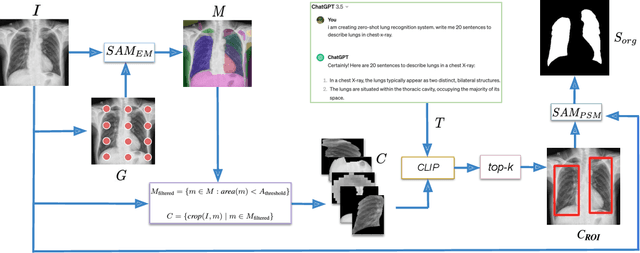

The Segment Anything Model (SAM) and CLIP are remarkable vision foundation models (VFMs). SAM, a prompt driven segmentation model, excels in segmentation tasks across diverse domains, while CLIP is renowned for its zero shot recognition capabilities. However, their unified potential has not yet been explored in medical image segmentation. To adapt SAM to medical imaging, existing methods primarily rely on tuning strategies that require extensive data or prior prompts tailored to the specific task, making it particularly challenging when only a limited number of data samples are available. This work presents an in depth exploration of integrating SAM and CLIP into a unified framework for medical image segmentation. Specifically, we propose a simple unified framework, SaLIP, for organ segmentation. Initially, SAM is used for part based segmentation within the image, followed by CLIP to retrieve the mask corresponding to the region of interest (ROI) from the pool of SAM generated masks. Finally, SAM is prompted by the retrieved ROI to segment a specific organ. Thus, SaLIP is training and fine tuning free and does not rely on domain expertise or labeled data for prompt engineering. Our method shows substantial enhancements in zero shot segmentation, showcasing notable improvements in DICE scores across diverse segmentation tasks like brain (63.46%), lung (50.11%), and fetal head (30.82%), when compared to un prompted SAM. Code and text prompts will be available online.
Do Vision and Language Encoders Represent the World Similarly?
Jan 10, 2024



Aligned text-image encoders such as CLIP have become the de facto model for vision-language tasks. Furthermore, modality-specific encoders achieve impressive performances in their respective domains. This raises a central question: does an alignment exist between uni-modal vision and language encoders since they fundamentally represent the same physical world? Analyzing the latent spaces structure of vision and language models on image-caption benchmarks using the Centered Kernel Alignment (CKA), we find that the representation spaces of unaligned and aligned encoders are semantically similar. In the absence of statistical similarity in aligned encoders like CLIP, we show that a possible matching of unaligned encoders exists without any training. We frame this as a seeded graph-matching problem exploiting the semantic similarity between graphs and propose two methods - a Fast Quadratic Assignment Problem optimization, and a novel localized CKA metric-based matching/retrieval. We demonstrate the effectiveness of this on several downstream tasks including cross-lingual, cross-domain caption matching and image classification.
Enhancing CLIP with GPT-4: Harnessing Visual Descriptions as Prompts
Aug 08, 2023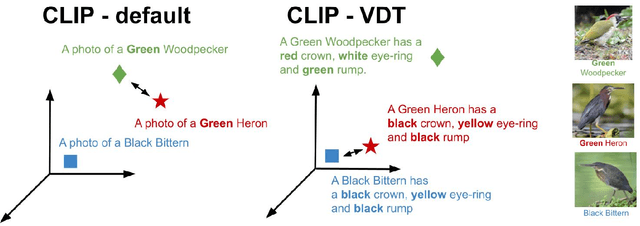


Contrastive pretrained large Vision-Language Models (VLMs) like CLIP have revolutionized visual representation learning by providing good performance on downstream datasets. VLMs are 0-shot adapted to a downstream dataset by designing prompts that are relevant to the dataset. Such prompt engineering makes use of domain expertise and a validation dataset. Meanwhile, recent developments in generative pretrained models like GPT-4 mean they can be used as advanced internet search tools. They can also be manipulated to provide visual information in any structure. In this work, we show that GPT-4 can be used to generate text that is visually descriptive and how this can be used to adapt CLIP to downstream tasks. We show considerable improvements in 0-shot transfer accuracy on specialized fine-grained datasets like EuroSAT (~7%), DTD (~7%), SUN397 (~4.6%), and CUB (~3.3%) when compared to CLIP's default prompt. We also design a simple few-shot adapter that learns to choose the best possible sentences to construct generalizable classifiers that outperform the recently proposed CoCoOP by ~2% on average and by over 4% on 4 specialized fine-grained datasets. The code, prompts, and auxiliary text dataset is available at https://github.com/mayug/VDT-Adapter.
The STOIC2021 COVID-19 AI challenge: applying reusable training methodologies to private data
Jun 25, 2023Challenges drive the state-of-the-art of automated medical image analysis. The quantity of public training data that they provide can limit the performance of their solutions. Public access to the training methodology for these solutions remains absent. This study implements the Type Three (T3) challenge format, which allows for training solutions on private data and guarantees reusable training methodologies. With T3, challenge organizers train a codebase provided by the participants on sequestered training data. T3 was implemented in the STOIC2021 challenge, with the goal of predicting from a computed tomography (CT) scan whether subjects had a severe COVID-19 infection, defined as intubation or death within one month. STOIC2021 consisted of a Qualification phase, where participants developed challenge solutions using 2000 publicly available CT scans, and a Final phase, where participants submitted their training methodologies with which solutions were trained on CT scans of 9724 subjects. The organizers successfully trained six of the eight Final phase submissions. The submitted codebases for training and running inference were released publicly. The winning solution obtained an area under the receiver operating characteristic curve for discerning between severe and non-severe COVID-19 of 0.815. The Final phase solutions of all finalists improved upon their Qualification phase solutions.HSUXJM-TNZF9CHSUXJM-TNZF9C
An Ensemble Deep Learning Approach for COVID-19 Severity Prediction Using Chest CT Scans
May 17, 2023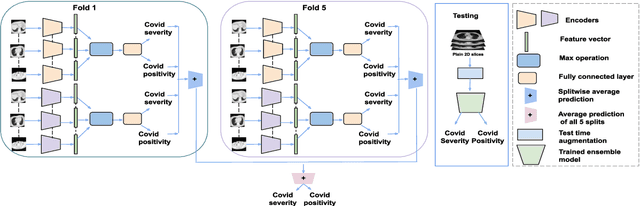
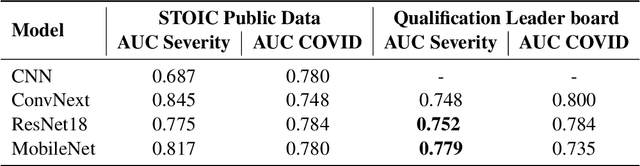

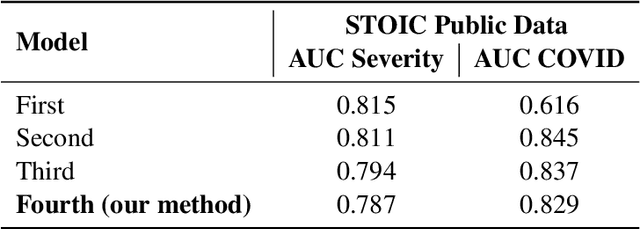
Chest X-rays have been widely used for COVID-19 screening; however, 3D computed tomography (CT) is a more effective modality. We present our findings on COVID-19 severity prediction from chest CT scans using the STOIC dataset. We developed an ensemble deep learning based model that incorporates multiple neural networks to improve predictions. To address data imbalance, we used slicing functions and data augmentation. We further improved performance using test time data augmentation. Our approach which employs a simple yet effective ensemble of deep learning-based models with strong test time augmentations, achieved results comparable to more complex methods and secured the fourth position in the STOIC2021 COVID-19 AI Challenge. Our code is available on online: at: https://github.com/aleemsidra/stoic2021- baseline-finalphase-main.
BaseTransformers: Attention over base data-points for One Shot Learning
Oct 05, 2022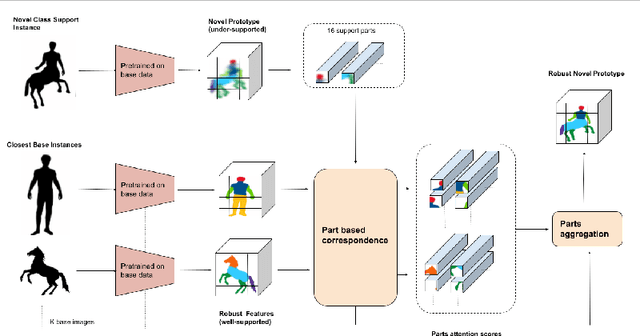
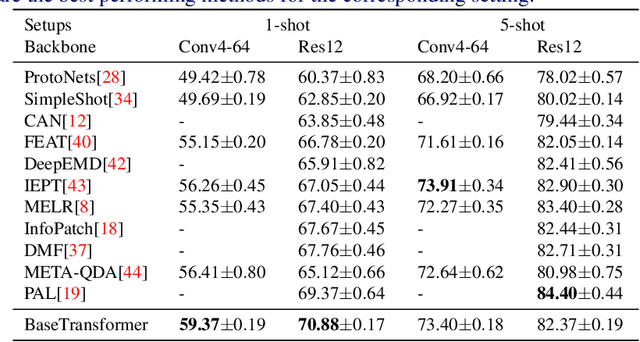
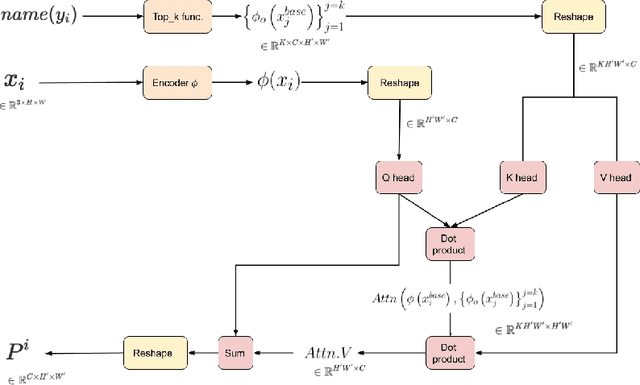
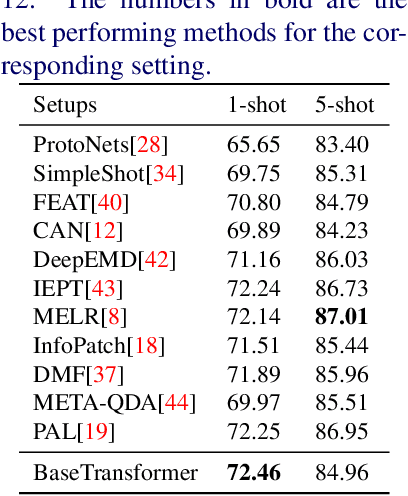
Few shot classification aims to learn to recognize novel categories using only limited samples per category. Most current few shot methods use a base dataset rich in labeled examples to train an encoder that is used for obtaining representations of support instances for novel classes. Since the test instances are from a distribution different to the base distribution, their feature representations are of poor quality, degrading performance. In this paper we propose to make use of the well-trained feature representations of the base dataset that are closest to each support instance to improve its representation during meta-test time. To this end, we propose BaseTransformers, that attends to the most relevant regions of the base dataset feature space and improves support instance representations. Experiments on three benchmark data sets show that our method works well for several backbones and achieves state-of-the-art results in the inductive one shot setting. Code is available at github.com/mayug/BaseTransformers
Phase retrieval for Fourier Ptychography under varying amount of measurements
May 09, 2018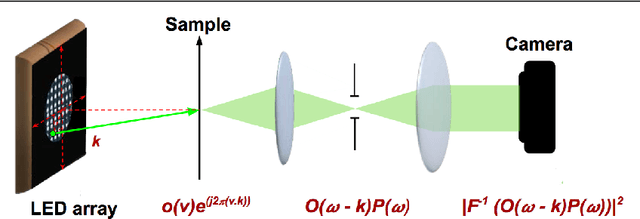



Fourier Ptychography is a recently proposed imaging technique that yields high-resolution images by computationally transcending the diffraction blur of an optical system. At the crux of this method is the phase retrieval algorithm, which is used for computationally stitching together low-resolution images taken under varying illumination angles of a coherent light source. However, the traditional iterative phase retrieval technique relies heavily on the initialization and also need a good amount of overlap in the Fourier domain for the successively captured low-resolution images, thus increasing the acquisition time and data. We show that an auto-encoder based architecture can be adaptively trained for phase retrieval under both low overlap, where traditional techniques completely fail, and at higher levels of overlap. For the low overlap case we show that a supervised deep learning technique using an autoencoder generator is a good choice for solving the Fourier ptychography problem. And for the high overlap case, we show that optimizing the generator for reducing the forward model error is an appropriate choice. Using simulations for the challenging case of uncorrelated phase and amplitude, we show that our method outperforms many of the previously proposed Fourier ptychography phase retrieval techniques.