 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFalcon Perception
Mar 28, 2026Perception-centric systems are typically implemented with a modular encoder-decoder pipeline: a vision backbone for feature extraction and a separate decoder (or late-fusion module) for task prediction. This raises a central question: is this architectural separation essential or can a single early-fusion stack do both perception and task modeling at scale? We introduce Falcon Perception, a unified dense Transformer that processes image patches and text tokens in a shared parameter space from the first layer, using a hybrid attention pattern (bidirectional among image tokens, causal for prediction tokens) to combine global visual context with autoregressive, variable-length instance generation. To keep dense outputs practical, Falcon Perception retains a lightweight token interface and decodes continuous spatial outputs with specialized heads, enabling parallel high-resolution mask prediction. Our design promotes simplicity: we keep a single scalable backbone and shift complexity toward data and training signals, adding only small heads where outputs are continuous and dense. On SA-Co, Falcon Perception improves mask quality to 68.0 Macro-F$_1$ compared to 62.3 of SAM3. We also introduce PBench, a benchmark targeting compositional prompts (OCR, spatial constraints, relations) and dense long-context regimes, where the model shows better gains. Finally, we extend the same early-fusion recipe to Falcon OCR: a compact 300M-parameter model which attains 80.3% on olmOCR and 88.64 on OmniDocBench.
VisRes Bench: On Evaluating the Visual Reasoning Capabilities of VLMs
Dec 24, 2025Vision-Language Models (VLMs) have achieved remarkable progress across tasks such as visual question answering and image captioning. Yet, the extent to which these models perform visual reasoning as opposed to relying on linguistic priors remains unclear. To address this, we introduce VisRes Bench, a benchmark designed to study visual reasoning in naturalistic settings without contextual language supervision. Analyzing model behavior across three levels of complexity, we uncover clear limitations in perceptual and relational visual reasoning capacities. VisRes isolates distinct reasoning abilities across its levels. Level 1 probes perceptual completion and global image matching under perturbations such as blur, texture changes, occlusion, and rotation; Level 2 tests rule-based inference over a single attribute (e.g., color, count, orientation); and Level 3 targets compositional reasoning that requires integrating multiple visual attributes. Across more than 19,000 controlled task images, we find that state-of-the-art VLMs perform near random under subtle perceptual perturbations, revealing limited abstraction beyond pattern recognition. We conclude by discussing how VisRes provides a unified framework for advancing abstract visual reasoning in multimodal research.
AMoE: Agglomerative Mixture-of-Experts Vision Foundation Model
Dec 23, 2025Vision foundation models trained via multi-teacher distillation offer a promising path toward unified visual representations, yet the learning dynamics and data efficiency of such approaches remain underexplored. In this paper, we systematically study multi-teacher distillation for vision foundation models and identify key factors that enable training at lower computational cost. We introduce Agglomerative Mixture-of-Experts Vision Foundation Models (AMoE), which distill knowledge from SigLIP2 and DINOv3 simultaneously into a Mixture-of-Experts student. We show that (1) our Asymmetric Relation-Knowledge Distillation loss preserves the geometric properties of each teacher while enabling effective knowledge transfer, (2) token-balanced batching that packs varying-resolution images into sequences with uniform token budgets stabilizes representation learning across resolutions without sacrificing performance, and (3) hierarchical clustering and sampling of training data--typically reserved for self-supervised learning--substantially improves sample efficiency over random sampling for multi-teacher distillation. By combining these findings, we curate OpenLVD200M, a 200M-image corpus that demonstrates superior efficiency for multi-teacher distillation. Instantiated in a Mixture-of-Experts. We release OpenLVD200M and distilled models.
From Unimodal to Multimodal: Scaling up Projectors to Align Modalities
Sep 28, 2024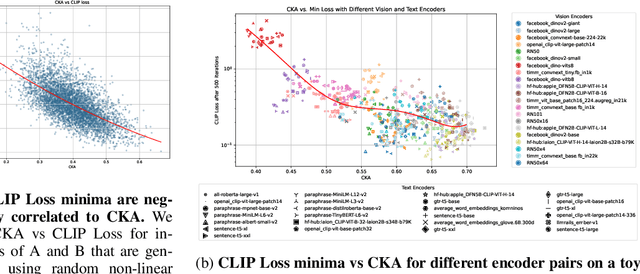

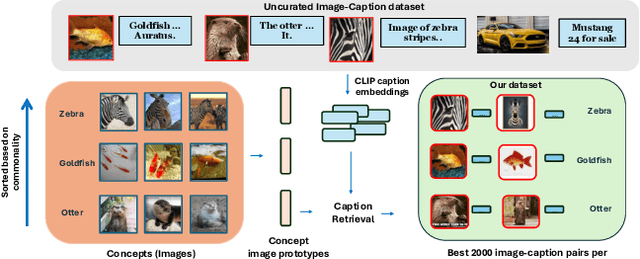
Recent contrastive multimodal vision-language models like CLIP have demonstrated robust open-world semantic understanding, becoming the standard image backbones for vision-language applications due to their aligned latent space. However, this practice has left powerful unimodal encoders for both vision and language underutilized in multimodal applications which raises a key question: Is there a plausible way to connect unimodal backbones for zero-shot vision-language tasks? To this end, we propose a novel approach that aligns vision and language modalities using only projection layers on pretrained, frozen unimodal encoders. Our method exploits the high semantic similarity between embedding spaces of well-trained vision and language models. It involves selecting semantically similar encoders in the latent space, curating a concept-rich dataset of image-caption pairs, and training simple MLP projectors. We evaluated our approach on 12 zero-shot classification datasets and 2 image-text retrieval datasets. Our best model, utilizing DINOv2 and All-Roberta-Large text encoder, achieves 76\(\%\) accuracy on ImageNet with a 20-fold reduction in data and 65 fold reduction in compute requirements. The proposed framework enhances the accessibility of model development while enabling flexible adaptation across diverse scenarios, offering an efficient approach to building multimodal models by utilizing existing unimodal architectures. Code and datasets will be released soon.
Falcon2-11B Technical Report
Jul 20, 2024



We introduce Falcon2-11B, a foundation model trained on over five trillion tokens, and its multimodal counterpart, Falcon2-11B-vlm, which is a vision-to-text model. We report our findings during the training of the Falcon2-11B which follows a multi-stage approach where the early stages are distinguished by their context length and a final stage where we use a curated, high-quality dataset. Additionally, we report the effect of doubling the batch size mid-training and how training loss spikes are affected by the learning rate. The downstream performance of the foundation model is evaluated on established benchmarks, including multilingual and code datasets. The foundation model shows strong generalization across all the tasks which makes it suitable for downstream finetuning use cases. For the vision language model, we report the performance on several benchmarks and show that our model achieves a higher average score compared to open-source models of similar size. The model weights and code of both Falcon2-11B and Falcon2-11B-vlm are made available under a permissive license.
Open-Vocabulary Temporal Action Localization using Multimodal Guidance
Jun 21, 2024Open-Vocabulary Temporal Action Localization (OVTAL) enables a model to recognize any desired action category in videos without the need to explicitly curate training data for all categories. However, this flexibility poses significant challenges, as the model must recognize not only the action categories seen during training but also novel categories specified at inference. Unlike standard temporal action localization, where training and test categories are predetermined, OVTAL requires understanding contextual cues that reveal the semantics of novel categories. To address these challenges, we introduce OVFormer, a novel open-vocabulary framework extending ActionFormer with three key contributions. First, we employ task-specific prompts as input to a large language model to obtain rich class-specific descriptions for action categories. Second, we introduce a cross-attention mechanism to learn the alignment between class representations and frame-level video features, facilitating the multimodal guided features. Third, we propose a two-stage training strategy which includes training with a larger vocabulary dataset and finetuning to downstream data to generalize to novel categories. OVFormer extends existing TAL methods to open-vocabulary settings. Comprehensive evaluations on the THUMOS14 and ActivityNet-1.3 benchmarks demonstrate the effectiveness of our method. Code and pretrained models will be publicly released.
Efficient 3D-Aware Facial Image Editing via Attribute-Specific Prompt Learning
Jun 06, 2024Drawing upon StyleGAN's expressivity and disentangled latent space, existing 2D approaches employ textual prompting to edit facial images with different attributes. In contrast, 3D-aware approaches that generate faces at different target poses require attribute-specific classifiers, learning separate model weights for each attribute, and are not scalable for novel attributes. In this work, we propose an efficient, plug-and-play, 3D-aware face editing framework based on attribute-specific prompt learning, enabling the generation of facial images with controllable attributes across various target poses. To this end, we introduce a text-driven learnable style token-based latent attribute editor (LAE). The LAE harnesses a pre-trained vision-language model to find text-guided attribute-specific editing direction in the latent space of any pre-trained 3D-aware GAN. It utilizes learnable style tokens and style mappers to learn and transform this editing direction to 3D latent space. To train LAE with multiple attributes, we use directional contrastive loss and style token loss. Furthermore, to ensure view consistency and identity preservation across different poses and attributes, we employ several 3D-aware identity and pose preservation losses. Our experiments show that our proposed framework generates high-quality images with 3D awareness and view consistency while maintaining attribute-specific features. We demonstrate the effectiveness of our method on different facial attributes, including hair color and style, expression, and others. Code: https://github.com/VIROBO-15/Efficient-3D-Aware-Facial-Image-Editing.
Multi-modal Generation via Cross-Modal In-Context Learning
May 28, 2024

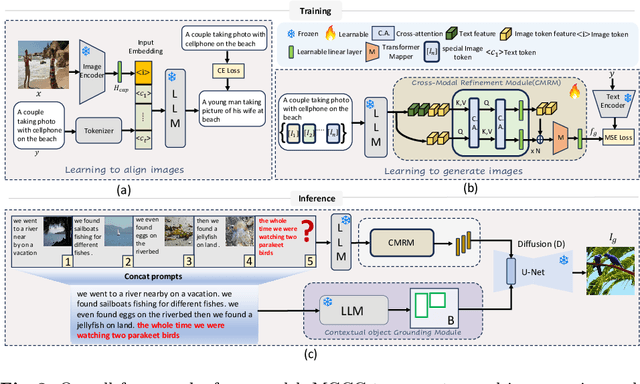

In this work, we study the problem of generating novel images from complex multimodal prompt sequences. While existing methods achieve promising results for text-to-image generation, they often struggle to capture fine-grained details from lengthy prompts and maintain contextual coherence within prompt sequences. Moreover, they often result in misaligned image generation for prompt sequences featuring multiple objects. To address this, we propose a Multi-modal Generation via Cross-Modal In-Context Learning (MGCC) method that generates novel images from complex multimodal prompt sequences by leveraging the combined capabilities of large language models (LLMs) and diffusion models. Our MGCC comprises a novel Cross-Modal Refinement module to explicitly learn cross-modal dependencies between the text and image in the LLM embedding space, and a contextual object grounding module to generate object bounding boxes specifically targeting scenes with multiple objects. Our MGCC demonstrates a diverse range of multimodal capabilities, like novel image generation, the facilitation of multimodal dialogue, and generation of texts. Experimental evaluations on two benchmark datasets, demonstrate the effectiveness of our method. On Visual Story Generation (VIST) dataset with multimodal inputs, our MGCC achieves a CLIP Similarity score of $0.652$ compared to SOTA GILL $0.641$. Similarly, on Visual Dialogue Context (VisDial) having lengthy dialogue sequences, our MGCC achieves an impressive CLIP score of $0.660$, largely outperforming existing SOTA method scoring $0.645$. Code: https://github.com/VIROBO-15/MGCC
ViSpeR: Multilingual Audio-Visual Speech Recognition
May 27, 2024This work presents an extensive and detailed study on Audio-Visual Speech Recognition (AVSR) for five widely spoken languages: Chinese, Spanish, English, Arabic, and French. We have collected large-scale datasets for each language except for English, and have engaged in the training of supervised learning models. Our model, ViSpeR, is trained in a multi-lingual setting, resulting in competitive performance on newly established benchmarks for each language. The datasets and models are released to the community with an aim to serve as a foundation for triggering and feeding further research work and exploration on Audio-Visual Speech Recognition, an increasingly important area of research. Code available at \href{https://github.com/YasserdahouML/visper}{https://github.com/YasserdahouML/visper}.
Do Vision and Language Encoders Represent the World Similarly?
Jan 10, 2024



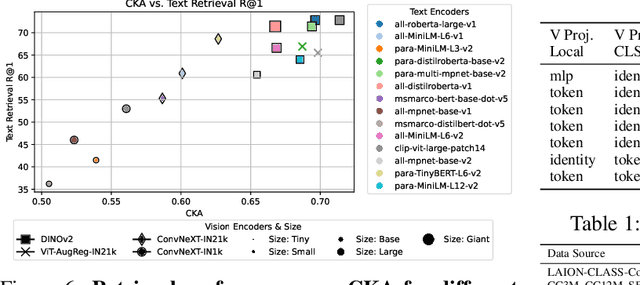
Aligned text-image encoders such as CLIP have become the de facto model for vision-language tasks. Furthermore, modality-specific encoders achieve impressive performances in their respective domains. This raises a central question: does an alignment exist between uni-modal vision and language encoders since they fundamentally represent the same physical world? Analyzing the latent spaces structure of vision and language models on image-caption benchmarks using the Centered Kernel Alignment (CKA), we find that the representation spaces of unaligned and aligned encoders are semantically similar. In the absence of statistical similarity in aligned encoders like CLIP, we show that a possible matching of unaligned encoders exists without any training. We frame this as a seeded graph-matching problem exploiting the semantic similarity between graphs and propose two methods - a Fast Quadratic Assignment Problem optimization, and a novel localized CKA metric-based matching/retrieval. We demonstrate the effectiveness of this on several downstream tasks including cross-lingual, cross-domain caption matching and image classification.