 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Distillation of Hidden Layers for Self-Supervised Representation Learning
Mar 16, 2026The landscape of self-supervised learning (SSL) is currently dominated by generative approaches (e.g., MAE) that reconstruct raw low-level data, and predictive approaches (e.g., I-JEPA) that predict high-level abstract embeddings. While generative methods provide strong grounding, they are computationally inefficient for high-redundancy modalities like imagery, and their training objective does not prioritize learning high-level, conceptual features. Conversely, predictive methods often suffer from training instability due to their reliance on the non-stationary targets of final-layer self-distillation. We introduce Bootleg, a method that bridges this divide by tasking the model with predicting latent representations from multiple hidden layers of a teacher network. This hierarchical objective forces the model to capture features at varying levels of abstraction simultaneously. We demonstrate that Bootleg significantly outperforms comparable baselines (+10% over I-JEPA) on classification of ImageNet-1K and iNaturalist-21, and semantic segmentation of ADE20K and Cityscapes.
A Hyperbolic Perspective on Hierarchical Structure in Object-Centric Scene Representations
Mar 14, 2026Slot attention has emerged as a powerful framework for unsupervised object-centric learning, decomposing visual scenes into a small set of compact vector representations called \emph{slots}, each capturing a distinct region or object. However, these slots are learned in Euclidean space, which provides no geometric inductive bias for the hierarchical relationships that naturally structure visual scenes. In this work, we propose a simple post-hoc pipeline to project Euclidean slot embeddings onto the Lorentz hyperboloid of hyperbolic space, without modifying the underlying training pipeline. We construct five-level visual hierarchies directly from slot attention masks and analyse whether hyperbolic geometry reveals latent hierarchical structure that remains invisible in Euclidean space. Integrating our pipeline with SPOT (images), VideoSAUR (video), and SlotContrast (video), We find that hyperbolic projection exposes a consistent scene-level to object-level organisation, where coarse slots occupy greater manifold depth than fine slots, which is absent in Euclidean space. We further identify a "curvature--task tradeoff": low curvature ($c{=}0.2$) matches or outperforms Euclidean on parent slot retrieval, while moderate curvature ($c{=}0.5$) achieves better inter-level separation. Together, these findings suggest that slot representations already encode latent hierarchy that hyperbolic geometry reveals, motivating end-to-end hyperbolic training as a natural next step. Code and models are available at \href{https://github.com/NeeluMadan/HHS}{github.com/NeeluMadan/HHS}.
A continental-scale dataset of ground beetles with high-resolution images and validated morphological trait measurements
Jan 14, 2026Despite the ecological significance of invertebrates, global trait databases remain heavily biased toward vertebrates and plants, limiting comprehensive ecological analyses of high-diversity groups like ground beetles. Ground beetles (Coleoptera: Carabidae) serve as critical bioindicators of ecosystem health, providing valuable insights into biodiversity shifts driven by environmental changes. While the National Ecological Observatory Network (NEON) maintains an extensive collection of carabid specimens from across the United States, these primarily exist as physical collections, restricting widespread research access and large-scale analysis. To address these gaps, we present a multimodal dataset digitizing over 13,200 NEON carabids from 30 sites spanning the continental US and Hawaii through high-resolution imaging, enabling broader access and computational analysis. The dataset includes digitally measured elytra length and width of each specimen, establishing a foundation for automated trait extraction using AI. Validated against manual measurements, our digital trait extraction achieves sub-millimeter precision, ensuring reliability for ecological and computational studies. By addressing invertebrate under-representation in trait databases, this work supports AI-driven tools for automated species identification and trait-based research, fostering advancements in biodiversity monitoring and conservation.
BarcodeMamba+: Advancing State-Space Models for Fungal Biodiversity Research
Dec 17, 2025Accurate taxonomic classification from DNA barcodes is a cornerstone of global biodiversity monitoring, yet fungi present extreme challenges due to sparse labelling and long-tailed taxa distributions. Conventional supervised learning methods often falter in this domain, struggling to generalize to unseen species and to capture the hierarchical nature of the data. To address these limitations, we introduce BarcodeMamba+, a foundation model for fungal barcode classification built on a powerful and efficient state-space model architecture. We employ a pretrain and fine-tune paradigm, which utilizes partially labelled data and we demonstrate this is substantially more effective than traditional fully-supervised methods in this data-sparse environment. During fine-tuning, we systematically integrate and evaluate a suite of enhancements--including hierarchical label smoothing, a weighted loss function, and a multi-head output layer from MycoAI--to specifically tackle the challenges of fungal taxonomy. Our experiments show that each of these components yields significant performance gains. On a challenging fungal classification benchmark with distinct taxonomic distribution shifts from the broad training set, our final model outperforms a range of existing methods across all taxonomic levels. Our work provides a powerful new tool for genomics-based biodiversity research and establishes an effective and scalable training paradigm for this challenging domain. Our code is publicly available at https://github.com/bioscan-ml/BarcodeMamba.
A multi-modal dataset for insect biodiversity with imagery and DNA at the trap and individual level
Jul 09, 2025Insects comprise millions of species, many experiencing severe population declines under environmental and habitat changes. High-throughput approaches are crucial for accelerating our understanding of insect diversity, with DNA barcoding and high-resolution imaging showing strong potential for automatic taxonomic classification. However, most image-based approaches rely on individual specimen data, unlike the unsorted bulk samples collected in large-scale ecological surveys. We present the Mixed Arthropod Sample Segmentation and Identification (MassID45) dataset for training automatic classifiers of bulk insect samples. It uniquely combines molecular and imaging data at both the unsorted sample level and the full set of individual specimens. Human annotators, supported by an AI-assisted tool, performed two tasks on bulk images: creating segmentation masks around each individual arthropod and assigning taxonomic labels to over 17 000 specimens. Combining the taxonomic resolution of DNA barcodes with precise abundance estimates of bulk images holds great potential for rapid, large-scale characterization of insect communities. This dataset pushes the boundaries of tiny object detection and instance segmentation, fostering innovation in both ecological and machine learning research.
Taxonomic Reasoning for Rare Arthropods: Combining Dense Image Captioning and RAG for Interpretable Classification
Mar 13, 2025
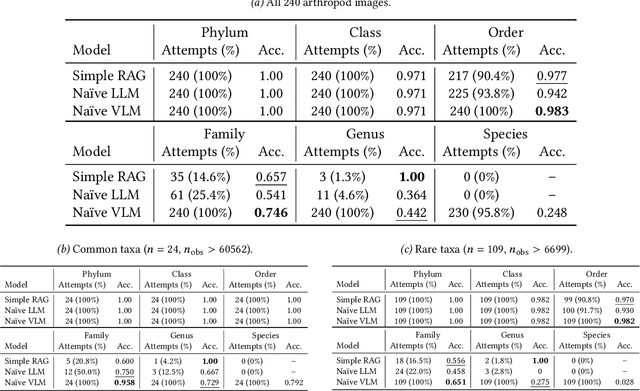
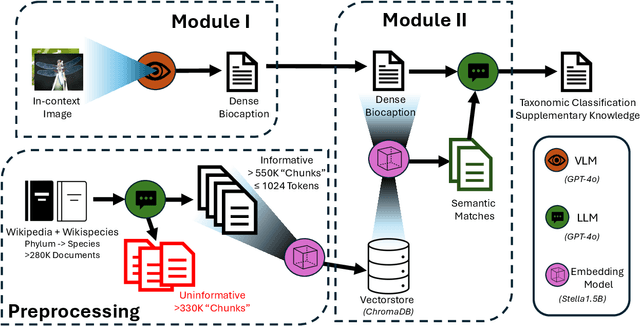
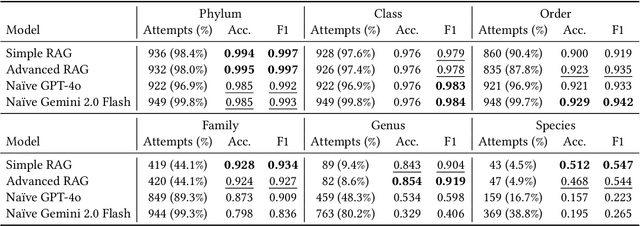
In the context of pressing climate change challenges and the significant biodiversity loss among arthropods, automated taxonomic classification from organismal images is a subject of intense research. However, traditional AI pipelines based on deep neural visual architectures such as CNNs or ViTs face limitations such as degraded performance on the long-tail of classes and the inability to reason about their predictions. We integrate image captioning and retrieval-augmented generation (RAG) with large language models (LLMs) to enhance biodiversity monitoring, showing particular promise for characterizing rare and unknown arthropod species. While a naive Vision-Language Model (VLM) excels in classifying images of common species, the RAG model enables classification of rarer taxa by matching explicit textual descriptions of taxonomic features to contextual biodiversity text data from external sources. The RAG model shows promise in reducing overconfidence and enhancing accuracy relative to naive LLMs, suggesting its viability in capturing the nuances of taxonomic hierarchy, particularly at the challenging family and genus levels. Our findings highlight the potential for modern vision-language AI pipelines to support biodiversity conservation initiatives, emphasizing the role of comprehensive data curation and collaboration with citizen science platforms to improve species identification, unknown species characterization and ultimately inform conservation strategies.
Enhancing DNA Foundation Models to Address Masking Inefficiencies
Feb 25, 2025Masked language modelling (MLM) as a pretraining objective has been widely adopted in genomic sequence modelling. While pretrained models can successfully serve as encoders for various downstream tasks, the distribution shift between pretraining and inference detrimentally impacts performance, as the pretraining task is to map [MASK] tokens to predictions, yet the [MASK] is absent during downstream applications. This means the encoder does not prioritize its encodings of non-[MASK] tokens, and expends parameters and compute on work only relevant to the MLM task, despite this being irrelevant at deployment time. In this work, we propose a modified encoder-decoder architecture based on the masked autoencoder framework, designed to address this inefficiency within a BERT-based transformer. We empirically show that the resulting mismatch is particularly detrimental in genomic pipelines where models are often used for feature extraction without fine-tuning. We evaluate our approach on the BIOSCAN-5M dataset, comprising over 2 million unique DNA barcodes. We achieve substantial performance gains in both closed-world and open-world classification tasks when compared against causal models and bidirectional architectures pretrained with MLM tasks.
BarcodeMamba: State Space Models for Biodiversity Analysis
Dec 15, 2024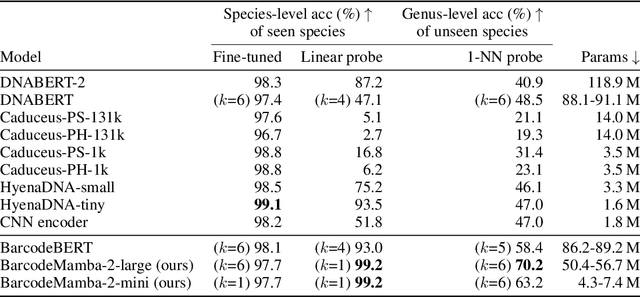
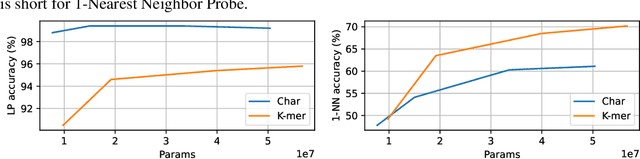
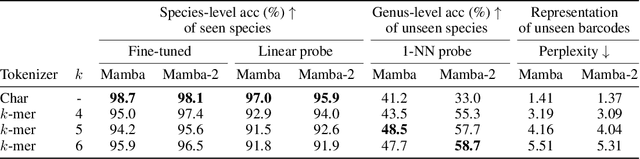
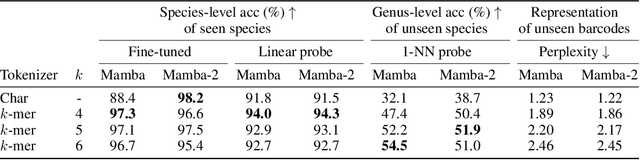
DNA barcodes are crucial in biodiversity analysis for building automatic identification systems that recognize known species and discover unseen species. Unlike human genome modeling, barcode-based invertebrate identification poses challenges in the vast diversity of species and taxonomic complexity. Among Transformer-based foundation models, BarcodeBERT excelled in species-level identification of invertebrates, highlighting the effectiveness of self-supervised pretraining on barcode-specific datasets. Recently, structured state space models (SSMs) have emerged, with a time complexity that scales sub-quadratically with the context length. SSMs provide an efficient parameterization of sequence modeling relative to attention-based architectures. Given the success of Mamba and Mamba-2 in natural language, we designed BarcodeMamba, a performant and efficient foundation model for DNA barcodes in biodiversity analysis. We conducted a comprehensive ablation study on the impacts of self-supervised training and tokenization methods, and compared both versions of Mamba layers in terms of expressiveness and their capacity to identify "unseen" species held back from training. Our study shows that BarcodeMamba has better performance than BarcodeBERT even when using only 8.3% as many parameters, and improves accuracy to 99.2% on species-level accuracy in linear probing without fine-tuning for "seen" species. In our scaling study, BarcodeMamba with 63.6% of BarcodeBERT's parameters achieved 70.2% genus-level accuracy in 1-nearest neighbor (1-NN) probing for unseen species. The code repository to reproduce our experiments is available at https://github.com/bioscan-ml/BarcodeMamba.
Food for thought: How can machine learning help better predict and understand changes in food prices?
Dec 09, 2024In this work, we address a lack of systematic understanding of fluctuations in food affordability in Canada. Canada's Food Price Report (CPFR) is an annual publication that predicts food inflation over the next calendar year. The published predictions are a collaborative effort between forecasting teams that each employ their own approach at Canadian Universities: Dalhousie University, the University of British Columbia, the University of Saskatchewan, and the University of Guelph/Vector Institute. While the University of Guelph/Vector Institute forecasting team has leveraged machine learning (ML) in previous reports, the most recent editions (2024--2025) have also included a human-in-the-loop approach. For the 2025 report, this focus was expanded to evaluate several different data-centric approaches to improve forecast accuracy. In this study, we evaluate how different types of forecasting models perform when estimating food price fluctuations. We also examine the sensitivity of models that curate time series data representing key factors in food pricing.
Agglomerative Token Clustering
Sep 18, 2024We present Agglomerative Token Clustering (ATC), a novel token merging method that consistently outperforms previous token merging and pruning methods across image classification, image synthesis, and object detection & segmentation tasks. ATC merges clusters through bottom-up hierarchical clustering, without the introduction of extra learnable parameters. We find that ATC achieves state-of-the-art performance across all tasks, and can even perform on par with prior state-of-the-art when applied off-the-shelf, i.e. without fine-tuning. ATC is particularly effective when applied with low keep rates, where only a small fraction of tokens are kept and retaining task performance is especially difficult.