 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPS-Guard: Framework for Dependability Assurance of AI- and LLM-Based Cyber-Physical Systems
Jun 04, 2025Cyber-Physical Systems (CPS) increasingly depend on advanced AI techniques to operate in critical applications. However, traditional verification and validation methods often struggle to handle the unpredictable and dynamic nature of AI components. In this paper, we introduce CPS-Guard, a novel framework that employs multi-role orchestration to automate the iterative assurance process for AI-powered CPS. By assigning specialized roles (e.g., safety monitoring, security assessment, fault injection, and recovery planning) to dedicated agents within a simulated environment, CPS-Guard continuously evaluates and refines AI behavior against a range of dependability requirements. We demonstrate the framework through a case study involving an autonomous vehicle navigating an intersection with an AI-based planner. Our results show that CPS-Guard effectively detects vulnerabilities, manages performance impacts, and supports adaptive recovery strategies, thereby offering a structured and extensible solution for rigorous V&V in safety- and security-critical systems.
GuideSR: Rethinking Guidance for One-Step High-Fidelity Diffusion-Based Super-Resolution
May 01, 2025In this paper, we propose GuideSR, a novel single-step diffusion-based image super-resolution (SR) model specifically designed to enhance image fidelity. Existing diffusion-based SR approaches typically adapt pre-trained generative models to image restoration tasks by adding extra conditioning on a VAE-downsampled representation of the degraded input, which often compromises structural fidelity. GuideSR addresses this limitation by introducing a dual-branch architecture comprising: (1) a Guidance Branch that preserves high-fidelity structures from the original-resolution degraded input, and (2) a Diffusion Branch, which a pre-trained latent diffusion model to enhance perceptual quality. Unlike conventional conditioning mechanisms, our Guidance Branch features a tailored structure for image restoration tasks, combining Full Resolution Blocks (FRBs) with channel attention and an Image Guidance Network (IGN) with guided attention. By embedding detailed structural information directly into the restoration pipeline, GuideSR produces sharper and more visually consistent results. Extensive experiments on benchmark datasets demonstrate that GuideSR achieves state-of-the-art performance while maintaining the low computational cost of single-step approaches, with up to 1.39dB PSNR gain on challenging real-world datasets. Our approach consistently outperforms existing methods across various reference-based metrics including PSNR, SSIM, LPIPS, DISTS and FID, further representing a practical advancement for real-world image restoration.
Revisiting Image Fusion for Multi-Illuminant White-Balance Correction
Mar 18, 2025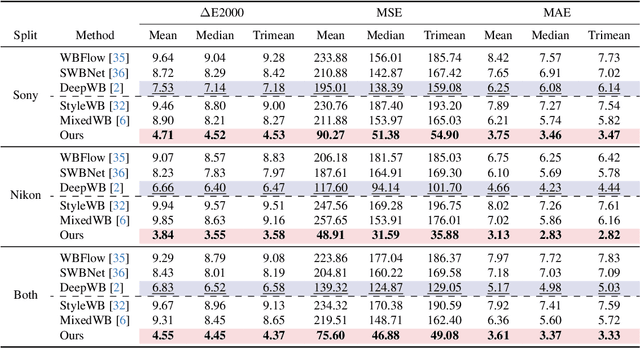

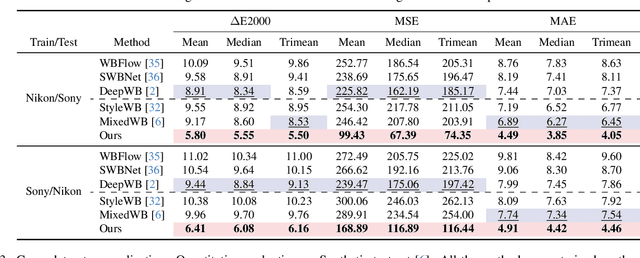
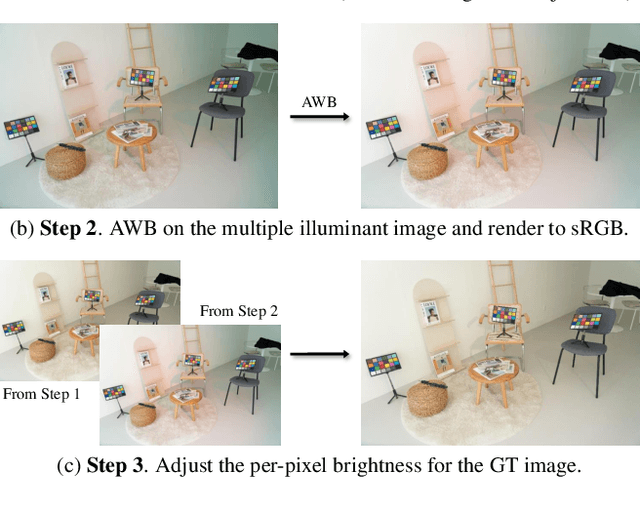
White balance (WB) correction in scenes with multiple illuminants remains a persistent challenge in computer vision. Recent methods explored fusion-based approaches, where a neural network linearly blends multiple sRGB versions of an input image, each processed with predefined WB presets. However, we demonstrate that these methods are suboptimal for common multi-illuminant scenarios. Additionally, existing fusion-based methods rely on sRGB WB datasets lacking dedicated multi-illuminant images, limiting both training and evaluation. To address these challenges, we introduce two key contributions. First, we propose an efficient transformer-based model that effectively captures spatial dependencies across sRGB WB presets, substantially improving upon linear fusion techniques. Second, we introduce a large-scale multi-illuminant dataset comprising over 16,000 sRGB images rendered with five different WB settings, along with WB-corrected images. Our method achieves up to 100\% improvement over existing techniques on our new multi-illuminant image fusion dataset.
Open-Vocabulary Temporal Action Localization using Multimodal Guidance
Jun 21, 2024Open-Vocabulary Temporal Action Localization (OVTAL) enables a model to recognize any desired action category in videos without the need to explicitly curate training data for all categories. However, this flexibility poses significant challenges, as the model must recognize not only the action categories seen during training but also novel categories specified at inference. Unlike standard temporal action localization, where training and test categories are predetermined, OVTAL requires understanding contextual cues that reveal the semantics of novel categories. To address these challenges, we introduce OVFormer, a novel open-vocabulary framework extending ActionFormer with three key contributions. First, we employ task-specific prompts as input to a large language model to obtain rich class-specific descriptions for action categories. Second, we introduce a cross-attention mechanism to learn the alignment between class representations and frame-level video features, facilitating the multimodal guided features. Third, we propose a two-stage training strategy which includes training with a larger vocabulary dataset and finetuning to downstream data to generalize to novel categories. OVFormer extends existing TAL methods to open-vocabulary settings. Comprehensive evaluations on the THUMOS14 and ActivityNet-1.3 benchmarks demonstrate the effectiveness of our method. Code and pretrained models will be publicly released.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022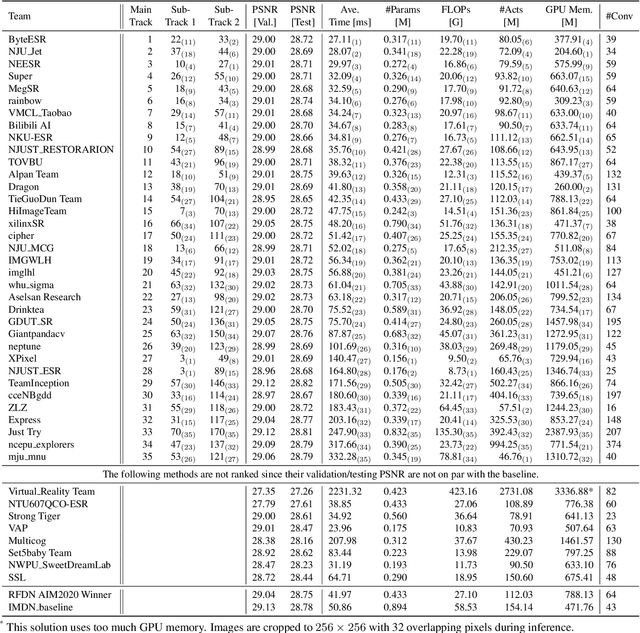
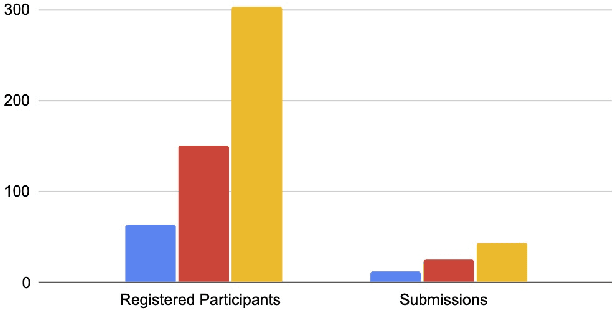
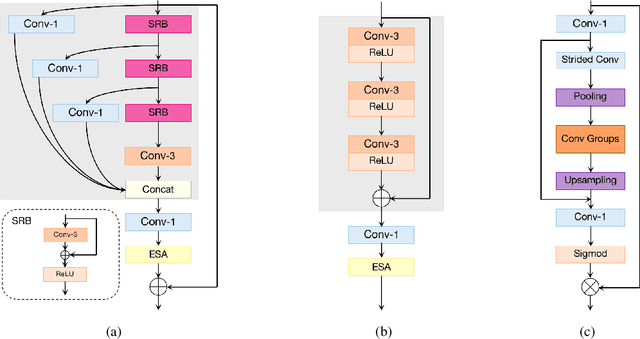
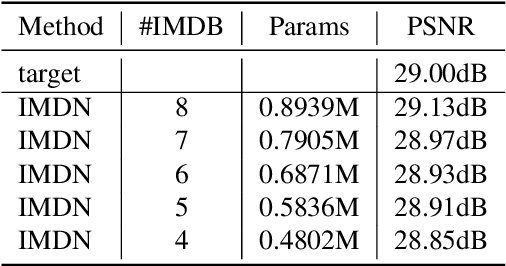
This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.
Learning Compressed Embeddings for On-Device Inference
Mar 18, 2022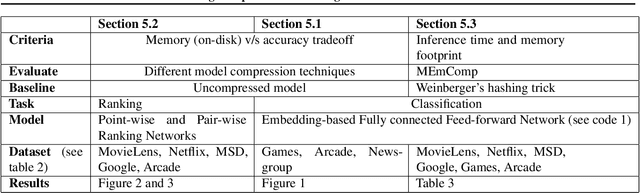
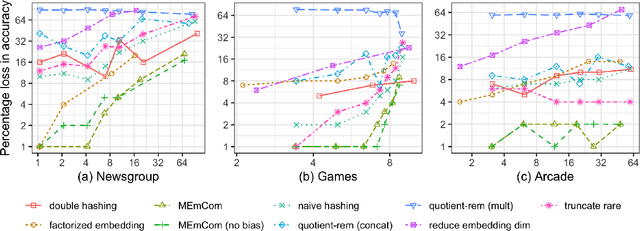
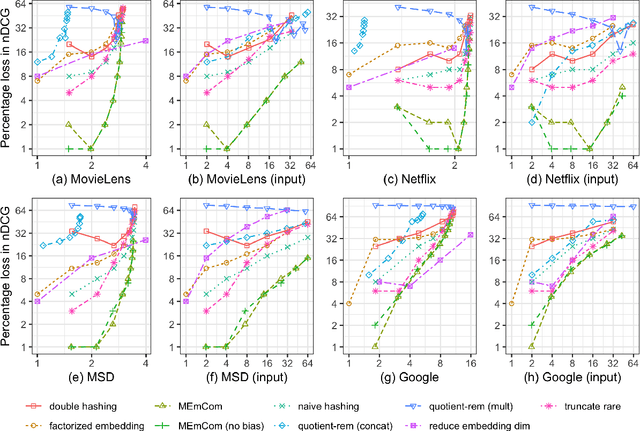

In deep learning, embeddings are widely used to represent categorical entities such as words, apps, and movies. An embedding layer maps each entity to a unique vector, causing the layer's memory requirement to be proportional to the number of entities. In the recommendation domain, a given category can have hundreds of thousands of entities, and its embedding layer can take gigabytes of memory. The scale of these networks makes them difficult to deploy in resource constrained environments. In this paper, we propose a novel approach for reducing the size of an embedding table while still mapping each entity to its own unique embedding. Rather than maintaining the full embedding table, we construct each entity's embedding "on the fly" using two separate embedding tables. The first table employs hashing to force multiple entities to share an embedding. The second table contains one trainable weight per entity, allowing the model to distinguish between entities sharing the same embedding. Since these two tables are trained jointly, the network is able to learn a unique embedding per entity, helping it maintain a discriminative capability similar to a model with an uncompressed embedding table. We call this approach MEmCom (Multi-Embedding Compression). We compare with state-of-the-art model compression techniques for multiple problem classes including classification and ranking. On four popular recommender system datasets, MEmCom had a 4% relative loss in nDCG while compressing the input embedding sizes of our recommendation models by 16x, 4x, 12x, and 40x. MEmCom outperforms the state-of-the-art techniques, which achieved 16%, 6%, 10%, and 8% relative loss in nDCG at the respective compression ratios. Additionally, MEmCom is able to compress the RankNet ranking model by 32x on a dataset with millions of users' interactions with games while incurring only a 1% relative loss in nDCG.
One-Shot Learning on Attributed Sequences
Jan 23, 2022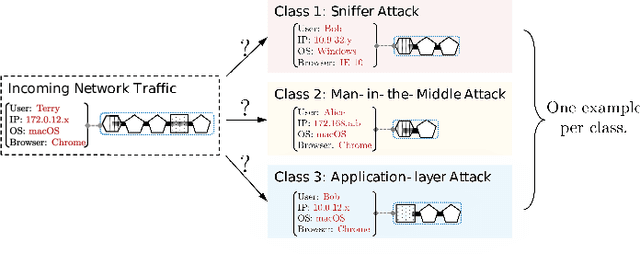
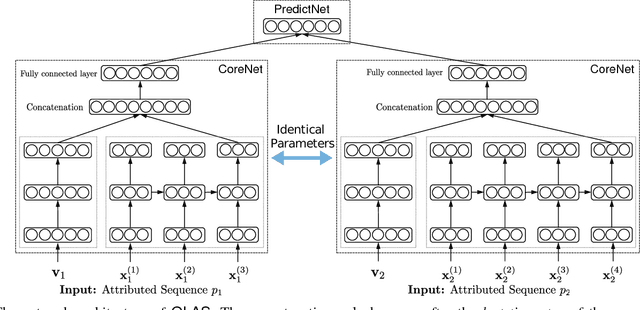
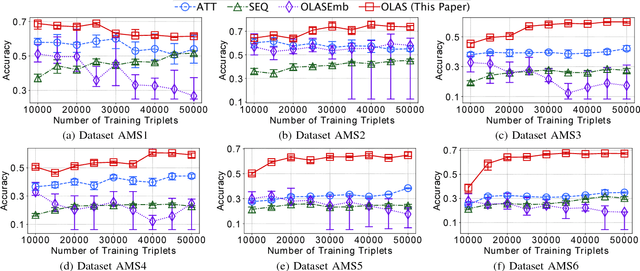
One-shot learning has become an important research topic in the last decade with many real-world applications. The goal of one-shot learning is to classify unlabeled instances when there is only one labeled example per class. Conventional problem setting of one-shot learning mainly focuses on the data that is already in feature space (such as images). However, the data instances in real-world applications are often more complex and feature vectors may not be available. In this paper, we study the problem of one-shot learning on attributed sequences, where each instance is composed of a set of attributes (e.g., user profile) and a sequence of categorical items (e.g., clickstream). This problem is important for a variety of real-world applications ranging from fraud prevention to network intrusion detection. This problem is more challenging than conventional one-shot learning since there are dependencies between attributes and sequences. We design a deep learning framework OLAS to tackle this problem. The proposed OLAS utilizes a twin network to generalize the features from pairwise attributed sequence examples. Empirical results on real-world datasets demonstrate the proposed OLAS can outperform the state-of-the-art methods under a rich variety of parameter settings.
Restormer: Efficient Transformer for High-Resolution Image Restoration
Nov 18, 2021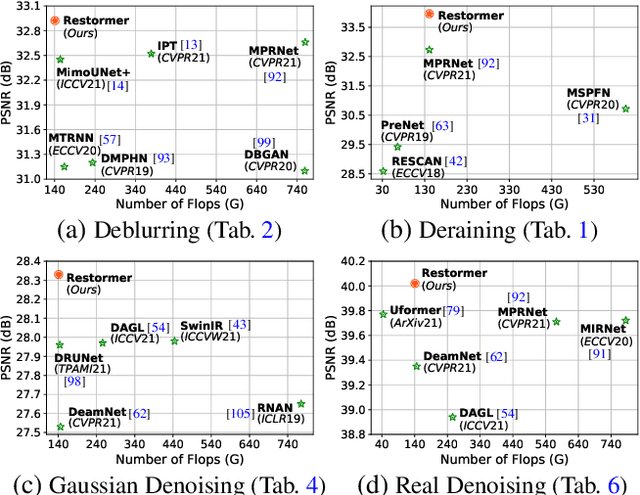
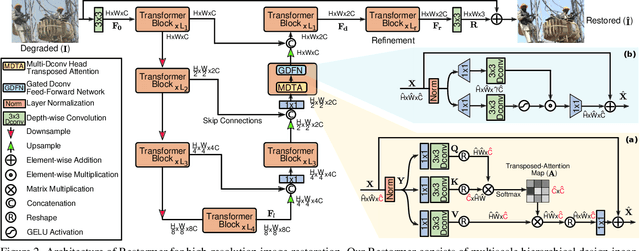
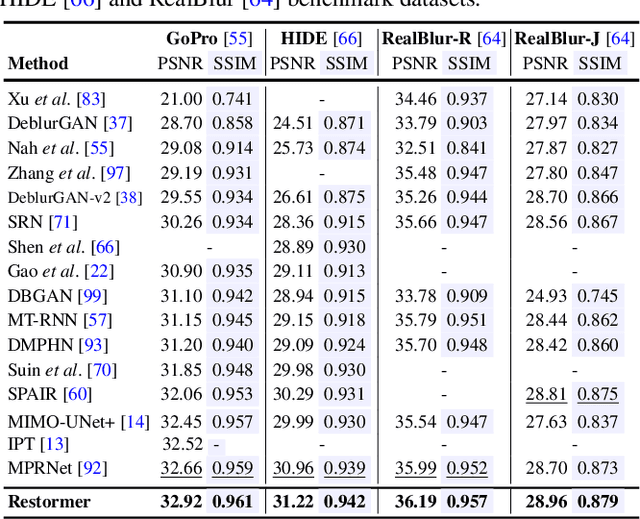
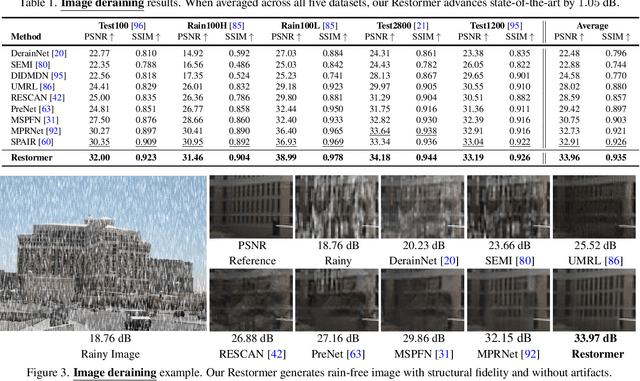
Since convolutional neural networks (CNNs) perform well at learning generalizable image priors from large-scale data, these models have been extensively applied to image restoration and related tasks. Recently, another class of neural architectures, Transformers, have shown significant performance gains on natural language and high-level vision tasks. While the Transformer model mitigates the shortcomings of CNNs (i.e., limited receptive field and inadaptability to input content), its computational complexity grows quadratically with the spatial resolution, therefore making it infeasible to apply to most image restoration tasks involving high-resolution images. In this work, we propose an efficient Transformer model by making several key designs in the building blocks (multi-head attention and feed-forward network) such that it can capture long-range pixel interactions, while still remaining applicable to large images. Our model, named Restoration Transformer (Restormer), achieves state-of-the-art results on several image restoration tasks, including image deraining, single-image motion deblurring, defocus deblurring (single-image and dual-pixel data), and image denoising (Gaussian grayscale/color denoising, and real image denoising). The source code and pre-trained models are available at https://github.com/swz30/Restormer.
Multi-Stage Progressive Image Restoration
Feb 04, 2021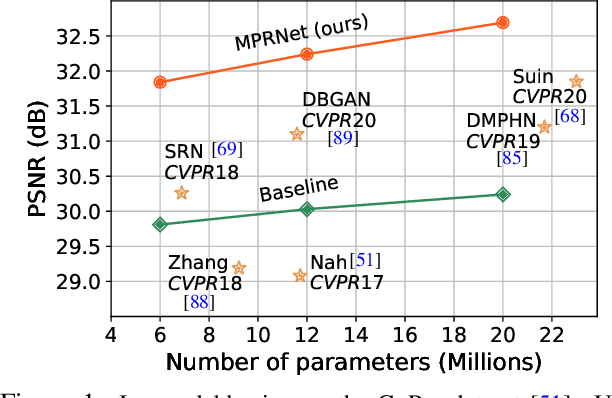

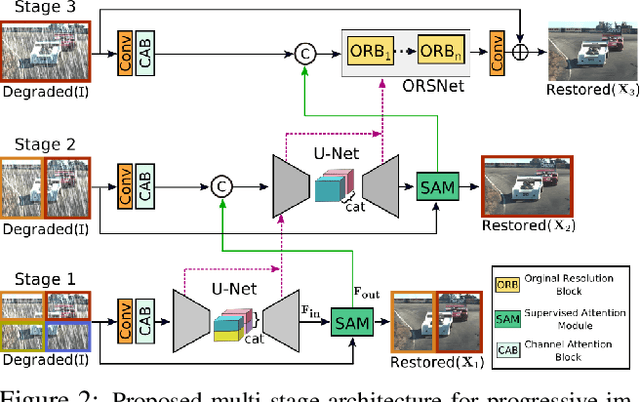
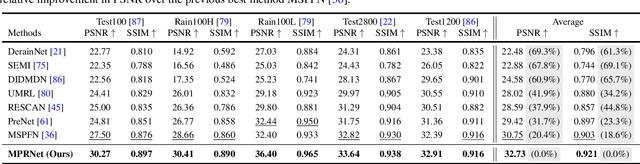
Image restoration tasks demand a complex balance between spatial details and high-level contextualized information while recovering images. In this paper, we propose a novel synergistic design that can optimally balance these competing goals. Our main proposal is a multi-stage architecture, that progressively learns restoration functions for the degraded inputs, thereby breaking down the overall recovery process into more manageable steps. Specifically, our model first learns the contextualized features using encoder-decoder architectures and later combines them with a high-resolution branch that retains local information. At each stage, we introduce a novel per-pixel adaptive design that leverages in-situ supervised attention to reweight the local features. A key ingredient in such a multi-stage architecture is the information exchange between different stages. To this end, we propose a two-faceted approach where the information is not only exchanged sequentially from early to late stages, but lateral connections between feature processing blocks also exist to avoid any loss of information. The resulting tightly interlinked multi-stage architecture, named as MPRNet, delivers strong performance gains on ten datasets across a range of tasks including image deraining, deblurring, and denoising. For example, on the Rain100L, GoPro and DND datasets, we obtain PSNR gains of 4 dB, 0.81 dB and 0.21 dB, respectively, compared to the state-of-the-art. The source code and pre-trained models are available at https://github.com/swz30/MPRNet.
Low Light Image Enhancement via Global and Local Context Modeling
Jan 04, 2021
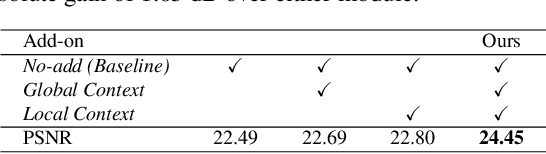
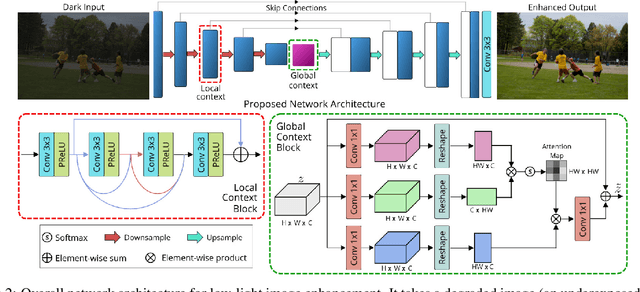

Images captured under low-light conditions manifest poor visibility, lack contrast and color vividness. Compared to conventional approaches, deep convolutional neural networks (CNNs) perform well in enhancing images. However, being solely reliant on confined fixed primitives to model dependencies, existing data-driven deep models do not exploit the contexts at various spatial scales to address low-light image enhancement. These contexts can be crucial towards inferring several image enhancement tasks, e.g., local and global contrast, brightness and color corrections; which requires cues from both local and global spatial extent. To this end, we introduce a context-aware deep network for low-light image enhancement. First, it features a global context module that models spatial correlations to find complementary cues over full spatial domain. Second, it introduces a dense residual block that captures local context with a relatively large receptive field. We evaluate the proposed approach using three challenging datasets: MIT-Adobe FiveK, LoL, and SID. On all these datasets, our method performs favorably against the state-of-the-arts in terms of standard image fidelity metrics. In particular, compared to the best performing method on the MIT-Adobe FiveK dataset, our algorithm improves PSNR from 23.04 dB to 24.45 dB.