 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNumColor: Precise Numeric Color Control in Text-to-Image Generation
Mar 13, 2026Text-to-image diffusion models excel at generating images from natural language descriptions, yet fail to interpret numerical colors such as hex codes (#FF5733) and RGB values (rgb(255,87,51)). This limitation stems from subword tokenization, which fragments color codes into semantically meaningless tokens that text encoders cannot map to coherent color representations. We present NumColor, that enables precise numerical color control across multiple diffusion architectures. NumColor comprises two components: a Color Token Aggregator that detects color specifications regardless of tokenization, and a ColorBook containing 6,707 learnable embeddings that map colors to embedding space of text encoder in perceptually uniform CIE Lab space. We introduce two auxiliary losses, directional alignment and interpolation consistency, to enforce geometric correspondence between Lab and embedding spaces, enabling smooth color interpolation. To train the ColorBook, we construct NumColor-Data, a synthetic dataset of 500K rendered images with unambiguous color-to-pixel correspondence, eliminating the annotation ambiguity inherent in photographic datasets. Although trained solely on FLUX, NumColor transfers zero-shot to SD3, SD3.5, PixArt-α, and PixArt-Σ without model-specific adaptation. NumColor improves numerical color accuracy by 4-9x across five models, while simultaneously improving color harmony scores by 10-30x on GenColorBench benchmark.
Diffusion-Based Low-Light Image Enhancement with Color and Luminance Priors
Feb 27, 2026Low-light images often suffer from low contrast, noise, and color distortion, degrading visual quality and impairing downstream vision tasks. We propose a novel conditional diffusion framework for low-light image enhancement that incorporates a Structured Control Embedding Module (SCEM). SCEM decomposes a low-light image into four informative components including illumination, illumination-invariant features, shadow priors, and color-invariant cues. These components serve as control signals that condition a U-Net-based diffusion model trained with a simplified noise-prediction loss. Thus, the proposed SCEM equipped Diffusion method enforces structured enhancement guided by physical priors. In experiments, our model is trained only on the LOLv1 dataset and evaluated without fine-tuning on LOLv2-real, LSRW, DICM, MEF, and LIME. The method achieves state-of-the-art performance in quantitative and perceptual metrics, demonstrating strong generalization across benchmarks. https://casted.github.io/scem/.
SyncLight: Controllable and Consistent Multi-View Relighting
Jan 23, 2026We present SyncLight, the first method to enable consistent, parametric relighting across multiple uncalibrated views of a static scene. While single-view relighting has advanced significantly, existing generative approaches struggle to maintain the rigorous lighting consistency essential for multi-camera broadcasts, stereoscopic cinema, and virtual production. SyncLight addresses this by enabling precise control over light intensity and color across a multi-view capture of a scene, conditioned on a single reference edit. Our method leverages a multi-view diffusion transformer trained using a latent bridge matching formulation, achieving high-fidelity relighting of the entire image set in a single inference step. To facilitate training, we introduce a large-scale hybrid dataset comprising diverse synthetic environments -- curated from existing sources and newly designed scenes -- alongside high-fidelity, real-world multi-view captures under calibrated illumination. Surprisingly, though trained only on image pairs, SyncLight generalizes zero-shot to an arbitrary number of viewpoints, effectively propagating lighting changes across all views, without requiring camera pose information. SyncLight enables practical relighting workflows for multi-view capture systems.
LumiCtrl : Learning Illuminant Prompts for Lighting Control in Personalized Text-to-Image Models
Dec 19, 2025Current text-to-image (T2I) models have demonstrated remarkable progress in creative image generation, yet they still lack precise control over scene illuminants, which is a crucial factor for content designers aiming to manipulate the mood, atmosphere, and visual aesthetics of generated images. In this paper, we present an illuminant personalization method named LumiCtrl that learns an illuminant prompt given a single image of an object. LumiCtrl consists of three basic components: given an image of the object, our method applies (a) physics-based illuminant augmentation along the Planckian locus to create fine-tuning variants under standard illuminants; (b) edge-guided prompt disentanglement using a frozen ControlNet to ensure prompts focus on illumination rather than structure; and (c) a masked reconstruction loss that focuses learning on the foreground object while allowing the background to adapt contextually, enabling what we call contextual light adaptation. We qualitatively and quantitatively compare LumiCtrl against other T2I customization methods. The results show that our method achieves significantly better illuminant fidelity, aesthetic quality, and scene coherence compared to existing personalization baselines. A human preference study further confirms strong user preference for LumiCtrl outputs. The code and data will be released upon publication.
Leveraging Multispectral Sensors for Color Correction in Mobile Cameras
Dec 09, 2025Recent advances in snapshot multispectral (MS) imaging have enabled compact, low-cost spectral sensors for consumer and mobile devices. By capturing richer spectral information than conventional RGB sensors, these systems can enhance key imaging tasks, including color correction. However, most existing methods treat the color correction pipeline in separate stages, often discarding MS data early in the process. We propose a unified, learning-based framework that (i) performs end-to-end color correction and (ii) jointly leverages data from a high-resolution RGB sensor and an auxiliary low-resolution MS sensor. Our approach integrates the full pipeline within a single model, producing coherent and color-accurate outputs. We demonstrate the flexibility and generality of our framework by refactoring two different state-of-the-art image-to-image architectures. To support training and evaluation, we construct a dedicated dataset by aggregating and repurposing publicly available spectral datasets, rendering under multiple RGB camera sensitivities. Extensive experiments show that our approach improves color accuracy and stability, reducing error by up to 50% compared to RGB-only and MS-driven baselines. Datasets, code, and models will be made available upon acceptance.
Evaluating Low-Light Image Enhancement Across Multiple Intensity Levels
Nov 19, 2025Imaging in low-light environments is challenging due to reduced scene radiance, which leads to elevated sensor noise and reduced color saturation. Most learning-based low-light enhancement methods rely on paired training data captured under a single low-light condition and a well-lit reference. The lack of radiance diversity limits our understanding of how enhancement techniques perform across varying illumination intensities. We introduce the Multi-Illumination Low-Light (MILL) dataset, containing images captured at diverse light intensities under controlled conditions with fixed camera settings and precise illuminance measurements. MILL enables comprehensive evaluation of enhancement algorithms across variable lighting conditions. We benchmark several state-of-the-art methods and reveal significant performance variations across intensity levels. Leveraging the unique multi-illumination structure of our dataset, we propose improvements that enhance robustness across diverse illumination scenarios. Our modifications achieve up to 10 dB PSNR improvement for DSLR and 2 dB for the smartphone on Full HD images.
GenColorBench: A Color Evaluation Benchmark for Text-to-Image Generation Models
Oct 23, 2025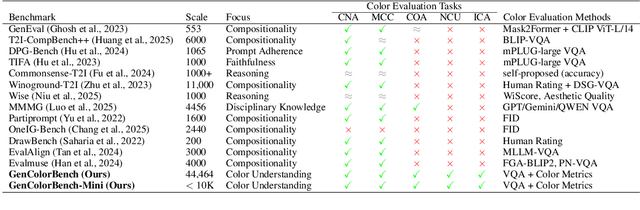

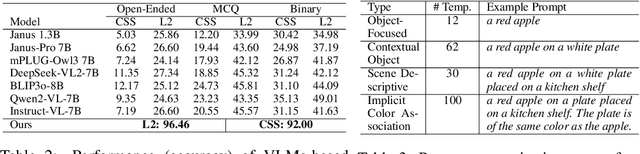
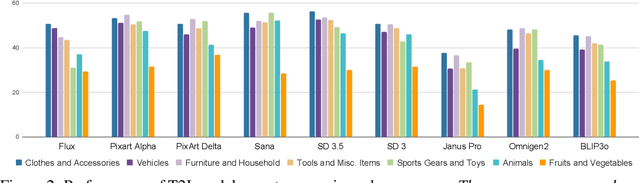
Recent years have seen impressive advances in text-to-image generation, with image generative or unified models producing high-quality images from text. Yet these models still struggle with fine-grained color controllability, often failing to accurately match colors specified in text prompts. While existing benchmarks evaluate compositional reasoning and prompt adherence, none systematically assess color precision. Color is fundamental to human visual perception and communication, critical for applications from art to design workflows requiring brand consistency. However, current benchmarks either neglect color or rely on coarse assessments, missing key capabilities such as interpreting RGB values or aligning with human expectations. To this end, we propose GenColorBench, the first comprehensive benchmark for text-to-image color generation, grounded in color systems like ISCC-NBS and CSS3/X11, including numerical colors which are absent elsewhere. With 44K color-focused prompts covering 400+ colors, it reveals models' true capabilities via perceptual and automated assessments. Evaluations of popular text-to-image models using GenColorBench show performance variations, highlighting which color conventions models understand best and identifying failure modes. Our GenColorBench assessments will guide improvements in precise color generation. The benchmark will be made public upon acceptance.
Color Names in Vision-Language Models
Sep 26, 2025Color serves as a fundamental dimension of human visual perception and a primary means of communicating about objects and scenes. As vision-language models (VLMs) become increasingly prevalent, understanding whether they name colors like humans is crucial for effective human-AI interaction. We present the first systematic evaluation of color naming capabilities across VLMs, replicating classic color naming methodologies using 957 color samples across five representative models. Our results show that while VLMs achieve high accuracy on prototypical colors from classical studies, performance drops significantly on expanded, non-prototypical color sets. We identify 21 common color terms that consistently emerge across all models, revealing two distinct approaches: constrained models using predominantly basic terms versus expansive models employing systematic lightness modifiers. Cross-linguistic analysis across nine languages demonstrates severe training imbalances favoring English and Chinese, with hue serving as the primary driver of color naming decisions. Finally, ablation studies reveal that language model architecture significantly influences color naming independent of visual processing capabilities.
LLM-Driven Medical Document Analysis: Enhancing Trustworthy Pathology and Differential Diagnosis
Jun 24, 2025Medical document analysis plays a crucial role in extracting essential clinical insights from unstructured healthcare records, supporting critical tasks such as differential diagnosis. Determining the most probable condition among overlapping symptoms requires precise evaluation and deep medical expertise. While recent advancements in large language models (LLMs) have significantly enhanced performance in medical document analysis, privacy concerns related to sensitive patient data limit the use of online LLMs services in clinical settings. To address these challenges, we propose a trustworthy medical document analysis platform that fine-tunes a LLaMA-v3 using low-rank adaptation, specifically optimized for differential diagnosis tasks. Our approach utilizes DDXPlus, the largest benchmark dataset for differential diagnosis, and demonstrates superior performance in pathology prediction and variable-length differential diagnosis compared to existing methods. The developed web-based platform allows users to submit their own unstructured medical documents and receive accurate, explainable diagnostic results. By incorporating advanced explainability techniques, the system ensures transparent and reliable predictions, fostering user trust and confidence. Extensive evaluations confirm that the proposed method surpasses current state-of-the-art models in predictive accuracy while offering practical utility in clinical settings. This work addresses the urgent need for reliable, explainable, and privacy-preserving artificial intelligence solutions, representing a significant advancement in intelligent medical document analysis for real-world healthcare applications. The code can be found at \href{https://github.com/leitro/Differential-Diagnosis-LoRA}{https://github.com/leitro/Differential-Diagnosis-LoRA}.
xLSTM-ECG: Multi-label ECG Classification via Feature Fusion with xLSTM
Apr 14, 2025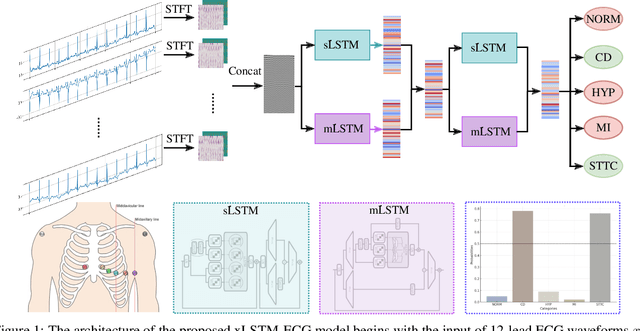
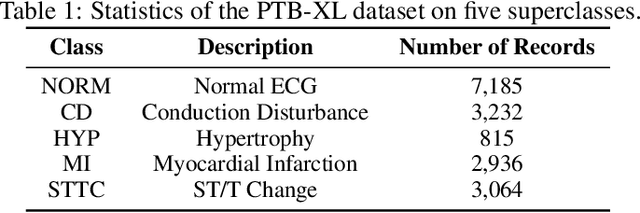
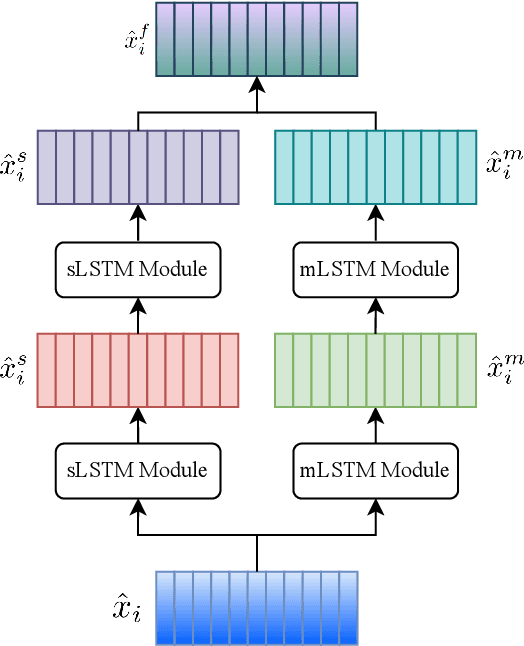

Cardiovascular diseases (CVDs) remain the leading cause of mortality worldwide, highlighting the critical need for efficient and accurate diagnostic tools. Electrocardiograms (ECGs) are indispensable in diagnosing various heart conditions; however, their manual interpretation is time-consuming and error-prone. In this paper, we propose xLSTM-ECG, a novel approach that leverages an extended Long Short-Term Memory (xLSTM) network for multi-label classification of ECG signals, using the PTB-XL dataset. To the best of our knowledge, this work represents the first design and application of xLSTM modules specifically adapted for multi-label ECG classification. Our method employs a Short-Time Fourier Transform (STFT) to convert time-series ECG waveforms into the frequency domain, thereby enhancing feature extraction. The xLSTM architecture is specifically tailored to address the complexities of 12-lead ECG recordings by capturing both local and global signal features. Comprehensive experiments on the PTB-XL dataset reveal that our model achieves strong multi-label classification performance, while additional tests on the Georgia 12-Lead dataset underscore its robustness and efficiency. This approach significantly improves ECG classification accuracy, thereby advancing clinical diagnostics and patient care. The code will be publicly available upon acceptance.